使用各类BeanUtils的时候,切记注意这个坑!
在日常开发中,我们经常需要给对象进行赋值,通常会调用其set/get方法,有些时候,如果我们要转换的两个对象之间属性大致相同,会考虑使用属性拷贝工具进行。
如我们经常在代码中会对一个数据结构封装成DO、SDO、DTO、VO等,而这些Bean中的大部分属性都是一样的,所以使用属性拷贝类工具可以帮助我们节省大量的set和get操作。
市面上有很多类似的工具类,比较常用的有
1、Spring BeanUtils 2、Cglib BeanCopier 3、Apache BeanUtils 4、Apache PropertyUtils 5、Dozer 6、MapStucts
这里面我比较建议大家使用的是MapStructs,我在《丢弃掉那些BeanUtils工具类吧,MapStruct真香!!!》中介绍过原因。这里就不再赘述了。
最近我们有个新项目,要创建一个新的应用,因为我自己分析过这些工具的效率,也去看过他们的实现原理,比较下来之后,我觉得MapStruct是最适合我们的,于是就在代码中引入了这个框架。
另外,因为Spring的BeanUtils用起来也比较方便,所以,代码中对于需要beanCopy的地方主要在使用这两个框架。
我们一般是这样的,如果是DO和DTO/Entity之间的转换,我们统一使用MapStruct,因为他可以指定单独的Mapper,可以自定义一些策略。
如果是同对象之间的拷贝(如用一个DO创建一个新的DO),或者完全不相关的两个对象转换,则使用Spring的BeanUtils。
刚开始都没什么问题,但是后面我在写单测的时候,发现了一个问题。
问题
先来看看我们是在什么地方用的Spring的BeanUtils
我们的业务逻辑中,需要对订单信息进行修改,在更改时,不仅要更新订单的上面的属性信息,还需要创建一条变更流水。
而变更流水中同时记录了变更前和变更后的数据,所以就有了以下代码:
//从数据库中查询出当前订单,并加锁
OrderDetail orderDetail = orderDetailDao.queryForLock();
//copy一个新的订单模型
OrderDetail newOrderDetail = new OrderDetail();
BeanUtils.copyProperties(orderDetail, newOrderDetail);
//对新的订单模型进行修改逻辑操作
newOrderDetail.update();
//使用修改前的订单模型和修改后的订单模型组装出订单变更流水
OrderDetailStream orderDetailStream = new OrderDetailStream();
orderDetailStream.create(orderDetail, newOrderDetail);
大致逻辑是这样的,因为创建订单变更流水的时候,需要一个改变前的订单和改变后的订单。所以我们想到了要new一个新的订单模型,然后操作新的订单模型,避免对旧的有影响。
但是,就是这个BeanUtils.copyProperties的过程其实是有问题的。
因为BeanUtils在进行属性copy的时候,本质上是浅拷贝,而不是深拷贝。
浅拷贝?深拷贝?
什么是浅拷贝和深拷贝?来看下概念。
1、浅拷贝:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。
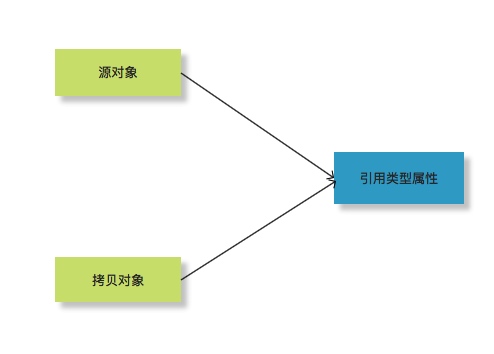 

2、深拷贝:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。
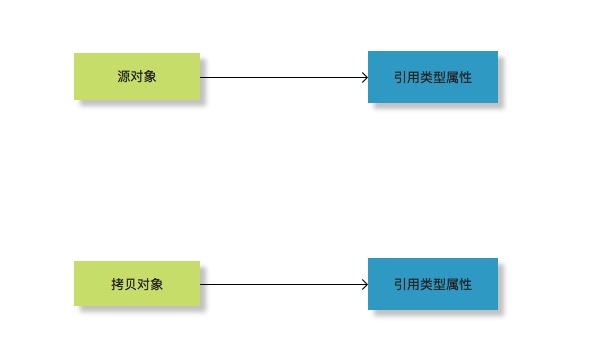 

我们举个实际例子,来看下为啥我说BeanUtils.copyProperties的过程是浅拷贝。
先来定义两个类:
public class Address {
private String province;
private String city;
private String area;
//省略构造函数和setter/getter
}
class User {
private String name;
private String password;
private HomeAddress address;
//省略构造函数和setter/getter
}
然后写一段测试代码:
User user = new User("Hollis", "hollischuang");
user.setAddress(new HomeAddress("zhejiang", "hangzhou", "binjiang"));
User newUser = new User();
BeanUtils.copyProperties(user, newUser);
System.out.println(user.getAddress() == newUser.getAddress());
以上代码输出结果为:true
即,我们BeanUtils.copyProperties拷贝出来的newUser中的address对象和原来的user中的address对象是同一个对象。
可以尝试着修改下newUser中的address对象:
newUser.getAddress().setCity("shanghai");
System.out.println(JSON.toJSONString(user));
System.out.println(JSON.toJSONString(newUser));
输出结果:
{"address":{"area":"binjiang","city":"shanghai","province":"zhejiang"},"name":"Hollis","password":"hollischuang"}
{"address":{"area":"binjiang","city":"shanghai","province":"zhejiang"},"name":"Hollis","password":"hollischuang"}
可以发现,原来的对象也受到了修改的影响。
这就是所谓的浅拷贝!
如何进行深拷贝
发现问题之后,我们就要想办法解决,那么如何实现深拷贝呢?
1、实现Cloneable接口,重写clone()
在Object类中定义了一个clone方法,这个方法其实在不重写的情况下,其实也是浅拷贝的。
如果想要实现深拷贝,就需要重写clone方法,而想要重写clone方法,就必须实现Cloneable,否则会报CloneNotSupportedException异常。
将上述代码修改下,重写clone方法:
public class Address implements Cloneable{
private String province;
private String city;
private String area;
//省略构造函数和setter/getter
@Override
public Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
class User implements Cloneable{
private String name;
private String password;
private HomeAddress address;
//省略构造函数和setter/getter
@Override
protected Object clone() throws CloneNotSupportedException {
User user = (User)super.clone();
user.setAddress((HomeAddress)address.clone());
return user;
}
}
之后,在执行一下上面的测试代码,就可以发现,这时候newUser中的address对象就是一个新的对象了。
这种方式就能实现深拷贝,但是问题是如果我们在User中有很多个对象,那么clone方法就写的很长,而且如果后面有修改,在User中新增属性,这个地方也要改。
那么,有没有什么办法可以不需要修改,一劳永逸呢?
2、序列化实现深拷贝
我们可以借助序列化来实现深拷贝。先把对象序列化成流,再从流中反序列化成对象,这样就一定是新的对象了。
序列化的方式有很多,比如我们可以使用各种JSON工具,把对象序列化成JSON字符串,然后再从字符串中反序列化成对象。
如使用fastjson实现:
User newUser = JSON.parseObject(JSON.toJSONString(user), User.class);
也可实现深拷贝。
除此之外,还可以使用Apache Commons Lang中提供的SerializationUtils工具实现。
我们需要修改下上面的User和Address类,使他们实现Serializable接口,否则是无法进行序列化的。
class User implements Serializable
class Address implements Serializable
然后在需要拷贝的时候:
User newUser = (User) SerializationUtils.clone(user);
同样,也可以实现深拷贝啦~!
使用各类BeanUtils的时候,切记注意这个坑!的更多相关文章
- Python中的logging模块
http://python.jobbole.com/86887/ 最近修改了项目里的logging相关功能,用到了python标准库里的logging模块,在此做一些记录.主要是从官方文档和stack ...
- Gink掉过的坑(一):将CCTableView导入到lua中
环境: 系统:win7 64位 cocos2dx:cocos2d-2.1rc0-x-2.1.3 Visual Studio: 2012 由于项目是用lua写的,需要将cocos2dx中的方法导入到lu ...
- python logging method 02
基本用法 下面的代码展示了logging最基本的用法. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 ...
- redis的入门篇---五种数据类型及基本操作
查看所有的key keys * 清空所有的key flushall 检查key是否存在 exists key 设置已存在的key的时长 expire key //设置key为10s 查看key还剩多少 ...
- 从技术专家到管理者的思路转变(V1)
作为技术专家出身的管理者,是一种优势(你所做的很多决策可能比非技术出身的管理者更加具有可行性和性价比).也是一种劣势(你可能会过于自恋自己的技术优势).这取决于你在接下去的职业生涯中,如何取舍你的技术 ...
- JSON.toJSONString中序列化空字符串遇到的坑
前言 最近在做系统Bug修复时遇到了一个问题,调用其他服务时传递的参数和自己预先的不一致,例如Map中有10条记录,然后使用JSON.toJSONString 包装后进行网络传递,但是通过调试发现接收 ...
- c json实战引擎四 , 最后❤跳跃
引言 - 以前那些系列 长活短说, 写的最终 scjson 纯c跨平台引擎, 希望在合适场景中替代老的csjon引擎, 速度更快, 更轻巧. 下面也是算一个系列吧. 从cjson 中得到灵感, 外加 ...
- python的logging日志模块(一)
最近修改了项目里的logging相关功能,用到了Python标准库里的logging模块,在此做一些记录.主要是从官方文档和stackoverflow上查询到的一些内容. 官方文档 技术博客 基本用法 ...
- 小程序 大转盘 抽奖 canvas animation
项目需求运用到大转盘 可设置概率 可直接自定义结果 效果如下
随机推荐
- Vue 全局组件
全局注册的组件可以在其他组件内直接使用,它在整个Vue实例中都是全局有效的. 非单文件组件中使用 Vue.component('student-list', { template: ` <div ...
- 暑假自学java第五天
关于测试类的问题: 单独创建一个包存放测试类,如com.test 首先要构建路径添加测试类的相关类库,方法是项目右键,buld path->config buld path->librar ...
- MyBatis:MyBatis-Plus条件构造器EntityWrapper
EntityWrapper 简介 1. MybatisPlus 通过 EntityWrapper(简称 EW,MybatisPlus 封装的一个查询条件构造器)或者 Condition(与 EW 类似 ...
- shell 中()、[]、{}、(())、[[]]等各种括号的使用
11 shell中内置关键字[[]]:检查条件是否成立 1.小括号.圆括号() 1.1 单小括号() 用途 命令组 括号中的命令将会新开一个子shell顺序执行,所以括号中的变量不能够被脚本余 ...
- Nginx 实践:location 路径匹配
1. 目标 nginx 反向代理,路径映射的过程是什么?如何配置路径映射规则? 2.location 路径匹配 2.1 匹配规则: location 路径正则匹配: 符号 说明 ~ 正则匹配,区分大小 ...
- 【重学Java】多线程基础(三种创建方式,线程安全,生产者消费者)
实现多线程 简单了解多线程[理解] 是指从软件或者硬件上实现多个线程并发执行的技术. 具有多线程能力的计算机因有硬件支持而能够在同一时间执行多个线程,提升性能. 并发和并行[理解] 并行:在同一时刻, ...
- YAOI Round #5 题解
前言 比赛链接: Div.1 : http://47.110.12.131:9016/contest/13 Div.2 : http://47.110.12.131:9016/contest/12 D ...
- Echarts入门踩坑记录
关于Echarts,官网上,是这样介绍的,"Echarts,一个使用JavaScript实现的开源可视化库",也就是说,在使用过程中,将其作为普通的JavaScript组件库使用即 ...
- Blazor 事件处理开发指南
翻译自 Waqas Anwar 2021年3月25日的文章 <A Developer's Guide To Blazor Event Handling> [1] 如果您正在开发交互式 We ...
- 用Nextcloud在树莓派上布置你的个人网盘“NAS”
用Nextcloud在树莓派上布置你的个人网盘"NAS" 这次用的是目前最新的 Raspbian Stretch 系统,基于 Debian 9. 软件程序是 Nextcloud 1 ...