OOUnit3Summary
一、JML基础梳理及工具链
jml语言基础
JML的全称是Java Modeling language,是一种行为接口规格语言,通过JML及其支持工具,不仅可以基于规格自动构造测试用例,还可用SMT Solver等工具以静态方式来检查代码实现对规格的满足情况。
1、注释结构
行注释://@annotation
块注释:/*@ annotation @*/
2、JML表达式
1.1原子表达式
\result表达式:表示一个非 void 类型的方法执行所获得的结果,即方法执行后的返回值。
\old( expr )表达式:用来表示一个表达式 expr 在相应方法执行前的取值。
\not_assigned(x,y,...)表达式:用来表示括号中的变量是否在方法执行过程中被赋值。
\not_modified(x,y,...)表达式:与上面的\not_assigned表达式类似,该表达式限制括号中的变量在方法执行期间的取 值未发生变化。
\nonnullelements( container )表达式:表示 container 对象中存储的对象不会有 null 。
\type(type)表达式:返回类型type对应的类型(Class) 。
\typeof(expr)表达式:该表达式返回expr对应的准确类型。
1.2量化表达式
\forall表达式:全称量词修饰的表达式,表示对于给定范围内的元素,每个元素都满足相应的约束。
\exists表达式:存在量词修饰的表达式,表示对于给定范围内的元素,存在某个元素满足相应的约束。
\sum表达式:返回给定范围内的表达式的和。
\product表达式:返回给定范围内的表达式的连乘结果。
\max表达式:返回给定范围内的表达式的最大值。
\num_of表达式:返回指定变量中满足相应条件的取值个数。
3、方法规格
(1) 前置条件:requires
(2)后置条件:ensures
(3)副作用范围限定:assignable或modifiable
4、类型规格
(1)不变式invariant:是要求在所有可见状态下都必须满足的特性,语法上定义 invariant P ,其中 invariant 为关 键词, P 为谓词。
(2)状态变化约束constraint :对象的状态在变化时往往也许满足一些约束,这种约束本质上也是一种不变式。
工具链
1.OpenJML:检查JML规格的正确性,提供对程序的静态和动态检查。
由于各种报错等问题,本人openjml的布局失败。。。
2.JMLUnitNG:根据JML自动生成测试数据来验证正确性。
首先,将(稍加修改的)MyGroup.java和openjml,junitng的jar包放在同一目录下,然后命令行运行如下命令:
java -jar jmlunitng.jar test/Group.java javac -cp jmlunitng.jar test/*.java java -jar openjml.jar -rac test/Group.java test/Person.java java -cp jmlunitng.jar test.Group_JML_Test
经过一系列尝试之后,终于是有结果了,以下是本人运行结果的片段,由于测试样例大多为一些边界数据,并不是所有的点都是pass,下图仅为pass的部分点:
二、前三次作业内容分析
前言
第三单元的作业以JML语言主题,以人际关系网络为背景,分三次要求逐步增加,难度逐步提高。这三次作业,让我进一步理解了java编程语言,明白了规格和实现之间的关系,使得我在编程上更为严谨。
以下是我对于这三次作业的总结,希望能给我以后得到作业和今后的编程道路提供帮助和参考。
第一次作业

架构分析:第一次作业主要是基于规格填写代码,难度不高。在isCircle方法中,本人使用了DFS,这并不是效率很高的算法,但对于本次作业的数据规模来说足够通过。
bug分析:本人在本次作业中并未被测出bug。
第二次作业
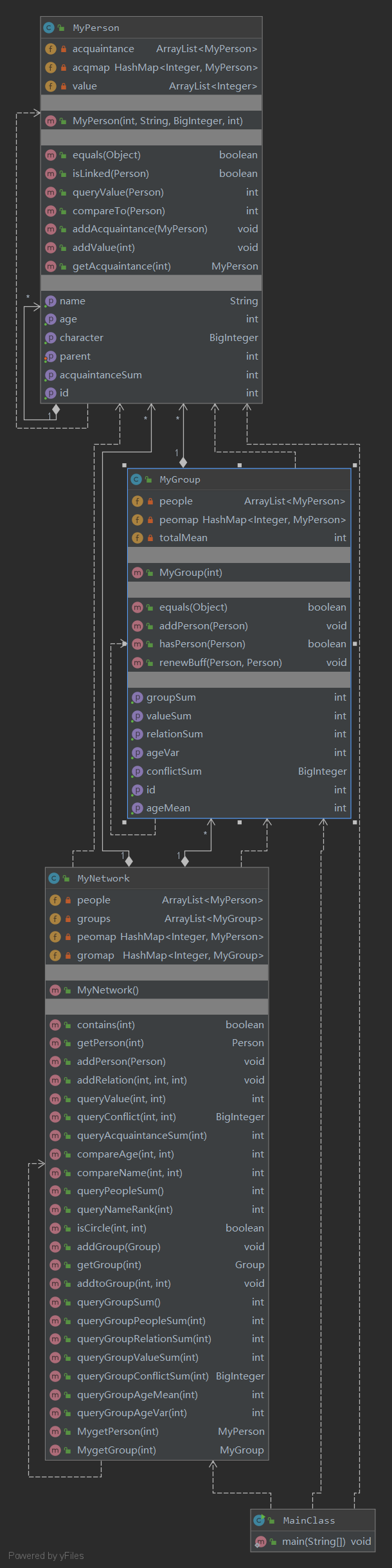
架构分析:第二次作业也主要是基于规格填写代码,增加了Group类,数据规模相对于第一次大大增加,本人不得不对其做一些优化;本人将isCircle方法改为了查并集,并且对于组内的关系合,平均年龄等数据采用了缓存机制;这些优化对于这种高访问低修改的数据效果十分明显。
bug分析:本人在这次作业中因为没要看到一行规格的描述(选择性忽略),导致强测挂了4个点;具体来说是group的人数小于1111,本人检查工作和测试工作做的十分不到位。
第三次作业
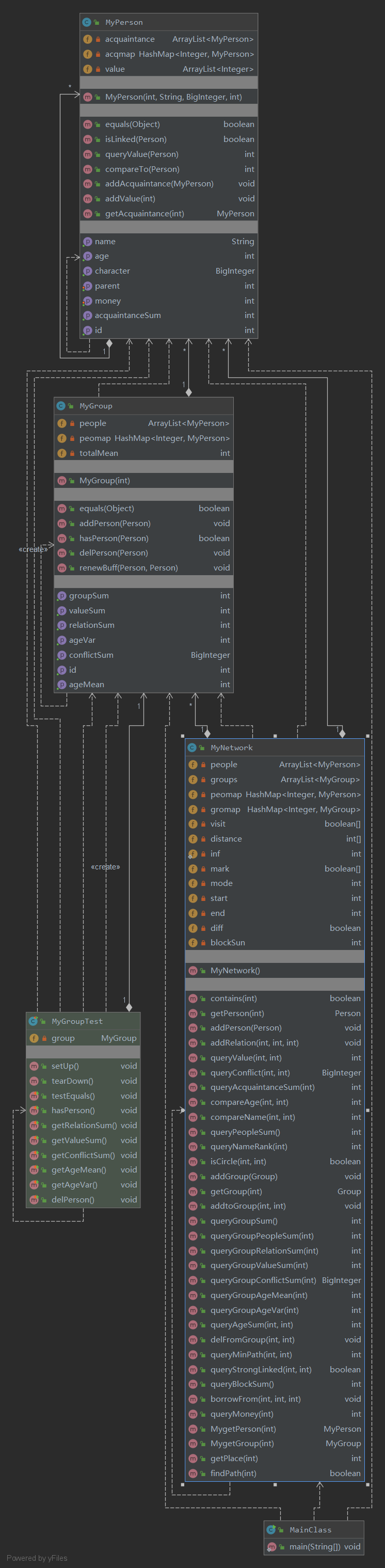
架构分析:第三次作业的难度相对于一,二次作业有了明显的提升,尤其是qmp(最短路径查询),qsl (环路查询)方法,本人前者采用了Dijkstra算法,后者采用了DFS环路查询算法,然而这两者复杂度较高,为强测和互测埋下隐患。
bug分析:本人在这次作业中的qmp和qsl均出现了tle问题,导致强测直接挂了5个点,本人不得不进行优化算法;参考了讨论区大佬和一些博客之后,本人qmp采用了优先队列的Dijkstra算法,qsl采用了枚举删点判断联通的方法,性能大大提高。
三、算法分析
虽然这次的博客在jml工具链方面着实恶心人,但三次作业下来本人还是接触到了一些非常有用的算法,虽然它们都是我因为数据强度关系不得已之为,但还是在这里总结一下, 这些东西至少比jml工具链的验证要有意义的多:
1.iscircle--并查集
每一个极大连通子图都抽象为一个群体,拥有共同的祖先(ancestor),每个人都有唯一的父亲结点(parent),每次进行isCircle,只需对两个结点循环找父亲结点 (追根溯源),直到找到祖宗(祖宗的父亲为其本身),两者的祖宗结点相同,则必连通。
int ancestor1 = p1.getParent();
while (ancestor1 != p1.getId()) {
p1 = MygetPerson(ancestor1);
ancestor1 = p1.getParent();
}
int ancestor2 = p2.getParent();
while (ancestor2 != p2.getId()) {
p2 = MygetPerson(ancestor2);
ancestor2 = p2.getParent();
}
p1.setParent(ancestor1);
p2.setParent(ancestor2);
return ancestor1 == ancestor2;
同时,在addrelation的时候,需要循环查找两者的祖先,若祖先不相同,则将后者的祖先的parent设置为前者的祖先,这样可以保证查找祖先路径的唯一性;
同时,为了进一步提高效率,本人采取了压缩路径的方法,每一次循环找祖先(adderlation,isCircle),都将结点的parent直接设置为自己的祖先,下一次访问课大大减少循环次数。
2.queryMinPath--优先队列的Dijkstra算法
此算法借鉴了一些博客,做了一些修改以适应本人的体系,采用java的核心类PriorityQueue,并将人抽象为id-distance二元对,用Weight类来表示这个二元对,并增加MyComparator类(继承Comparator,重写compare方法,为优先队列内部的堆排序提供比较原则)
MyComparator myComparator = new MyComparator();
PriorityQueue<Weight> que = new PriorityQueue<Weight>(myComparator);
HashMap<Integer, Integer> visit = new HashMap<Integer, Integer>();
HashMap<Integer, Integer> distance = new HashMap<Integer, Integer>();
Weight nweight = new Weight(id1, 0);
distance.put(id1, 0);
que.add(nweight);
while (!que.isEmpty()) {
Weight now = que.poll();
int id = now.getId();
if (visit.containsKey(id)) {
continue;
}
if (id == id2) {
break;
}
int min = now.getWeight();
visit.put(id, 1);
MyPerson top = MygetPerson(id);
for (int i = 0; i < top.getAcquaintanceSum(); i++) {
MyPerson np = top.getAcquaintance(i);
if (!visit.containsKey(np.getId())) {
if (!distance.containsKey(np.getId()) ||
min + top.queryValue(np) < distance.get(np.getId())) {
int update = min + top.queryValue(np);
Weight next = new Weight(np.getId(), update);
distance.put(np.getId(), update);
que.add(next);
}
}
}
}
return distance.get(id2);
3.queryStrongLink--删点寻通路
这个方法也是询问了大佬,本人一开始是用DFS找环路这种朴素的方法实现的,但无奈这个算法效率过于低下
此方法分为两种情况
1).两点直接相连:将连点之间的边(关系)删去,并进行DFS查找通路,若存在,则两点必成环
if (p1.isLinked(p2)) {
//System.out.println("mode1");
visit = new HashMap<Integer, Integer>();
final int value = p1.queryValue(p2);
p1.delAcquaintance(p2);
p2.delAcquaintance(p1);
final boolean isfind = findPath(id1, id2);
p1.addAcquaintance(p2);
p2.addAcquaintance(p1);
p1.addValue(value);
p2.addValue(value);
return isfind;
}
注意,由于这次背景架构的特殊性,删边即删除关系(熟人列表),由于arraylist顺序存储的特性,本人的Person类的熟人和Value集合位置是一一对应的,暂时删除人的时候关系值也要一并删除,加回的时候,要一并加回;
2),不直接相连:将除两点外的点一个个删去判断删除后有无通路,在一个个加回,事实上,若两点成环,删去任意一个点,不影响两者之间的连通性(找割点),实际上这只是一个必要条件,无法涵盖第一种情况,所以需要分类讨论,较为统一得到做法是直接删边,但这样更为复杂,遂放弃。
else {
for (int i = 0; i < people.size(); i++) {
int id = people.get(i).getId();
if (id == id1 || id == id2) {
continue;
} else {
visit = new HashMap<Integer, Integer>();
MyPerson np = peomap.remove(id);
//System.out.println("Remove:" + np.getId());
if (!findPath(id1, id2)) {
peomap.put(id, np);
//System.out.println("Fail:" + np.getId());
return false;
}
peomap.put(id, np);
}
}
return true;
}
}
同时要注意,由于数据规模的问题,visit采用数组,Person在arraylist中的位置对应数组中的index这样会炸tle,因为从id得知其位置需要一个遍历操作,才能知道其有无被访问过,然后遍历操作不可怕,可怕的是在循环中的遍历,更可怕的是在循环中的DFS中的每一次递归中的遍历;可取的做法是采用Hashmap,将id和是否被访问的标志为存的二元对存放。
四、心得体会
按理来说,本单元相对于前两单元是比较轻松的,但本人做的反而比前两次作业差,这主要是本人的疏忽和算法优化的工作不到位所致;相信经历了这单元之后,本人对于代码编写将更为严谨,也会更加注重算法复杂度的考量。
OOUnit3Summary的更多相关文章
随机推荐
- c++ win32 关机 注销 重启
#include <iostream> #include <Windows.h> #pragma comment(lib, "user32.lib") #p ...
- uniapp vue mixin使用
这个mixin的翻版,主要用来分离处理列表数据逻辑 我用了覆写模式 创建mixin ListMoreDataMixin // 由于没有超类的限制这里要判断下 function ____checkGet ...
- 2. Vue语法--插值操作&动态绑定属性 详解
目录 1. 设置vue模板 2. vue语法--插值操作 3. 动态绑定属性--v-bind 一. 设置vue模板 我们经常新建一个vue项目的时候, 会写如下的一段代码 <!DOCTYPE h ...
- django学习-4.url动态传值
1.前言 我们在浏览器访问一个网页A是通过一个指定的url地址去访问的.但在浏览器用一个不存在的url地址去执行访问是打不开正确的网页的,只会打开一个浏览器自带的有错误提示的网页. 在django框架 ...
- C++实现String类
1 #include<iostream> 2 #include<cstring> 3 4 class String 5 { 6 public: 7 String(); 8 St ...
- 三种远程部署war包检测
简介 远程部署漏洞属于服务器.中间件配置问题,攻击者可通过远程部署漏洞获取系统权限,远程部署漏洞经常出现在Tomcat.Jboss.Weblogic等web容器之上. 0x01 ### tomcat部 ...
- CentOS 7.7上配置mysql
转载:https://www.cnblogs.com/VinsonYang/p/12333570.html 首先登陆到阿里云,进行远程连接,在这里我使用的是Xshell 6进行连接的. 参照https ...
- 【死磕JVM】五年 整整五年了 该知道JVM加载机制了!
类加载 Java虚拟机类加载过程是把Class类文件加载到内存,并对Class文件中的数据进行校验.转换解析和初始化,最终形成可以被虚拟机直接使用的java类型的过程 和那些编译时需要连接工作的语言不 ...
- 从零开始搞后台管理系统(2)——shin-server
shin 的读音是[ʃɪn],谐音就是行,寓意可行的后端系统服务,shin-server 的特点是: 站在巨人的肩膀上,依托KOA2.bunyan.Sequelize等优秀的框架和库所搭建的定制化 ...
- (报错解决)Exception encountered during context initialization
转: (报错解决)Exception encountered during context initialization 关键词 JavaEE JavaWeb eclipse XML AspectJ ...