Scrapy安装和简单使用
模块安装
Windows
安装scrapy 需要安装依赖环境twisted,twisted又需要安装C++的依赖环境
pip install scrapy 时 如果出现twisted错误
在https://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载对应的Twisted的版本文件(cp36代表python3.6版本)

再cmd进入到Twisted所在的目录 执行pip install 加Twisted文件名
最后执行pip install scrapy
Ubuntu安装注意事项
不要使用 python-scrapyUbuntu提供的软件包,它们通常太旧而且速度慢,无法赶上最新的Scrapy
要在Ubuntu(或基于Ubuntu)系统上安装scrapy,您需要安装这些依赖项
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
如果你想在python3上安装scrapy,你还需要Python3的开发头文件
sudo apt-get install python3-dev
在virtualenv中,你可以使用pip安装Scrapy:pip install scrapy
简单使用
新建项目
scrapy startproject project_name
编写爬虫
第一种方式:创建单个文件
创建一个类,它必须继承scrapy.Spider类,需要定义三个属性
name: spider的名字,必须且唯一
start_urls: 初始的url列表
parse(self, response) 方法:每个初始url完成之后被调用
这个parse函数要完成两个功能
1、解析响应,封装成item对象并返回这个对象
2、提取新的需要下载的url,创建新的request,并返回它
单个文件的运行命令 scrapy runspider demo.py
第二种方式:通过命令创建
scrapy genspider 爬虫名 域名
运行爬虫
scrapy list 查看可以运行的爬虫文件
scrapy crawl 爬虫名(name属性的值)
追踪链接
创建一个类变量page_num用来记录当前爬取到的页码,在parse函数中提取信息,然后通过爬虫对象给变量page__num自加1,构造下一页的url,然后创建scrapy.Request对象并返回
如果response中提取不到信息,我们判断已经到了最后一页,parse函数直接return结束
定义item管道
parse函数在解析出我们需要的信息之后,可以将这些信息打包成一个字典对象或scray.Item对象,然后返回
这个对象会被发送到item管道,该管道会通过顺序执行几个组件处理它。每个item管道组件是一个实现简单方法的Python类
它们收到一个item并对其执行操作,同时决定该item是否应该继续通过管道或者被丢弃并且不再处理
item管道的典型用途:
清理HTML数据
验证已删除的数据(检查项目是否包含某些字段)
检查重复项(并删除它们)
将已爬取的item进行数据持久化
编写管道类
#在爬虫启动时执行 def open_ spider(self, spider)
#在爬虫关闭时,执行 def close_ spider(self, spider)
#对传递过来的item处理并return处理完的item def process_ item(self, item, spider)
要激活这个管道组件,必须将其添加到ITEM_PIPELINES设置中,在settings文件中设置
在此设置中为类分配的整数值决定了它们运行的顺序:按照从较低值到较高值的顺序进行
定义item
Scrapy提供了Item类
编辑项目目录下的items.py文件
在爬虫中导入我们定义的Item类,实例化后用它进行数据结构化
运行流程
数据流
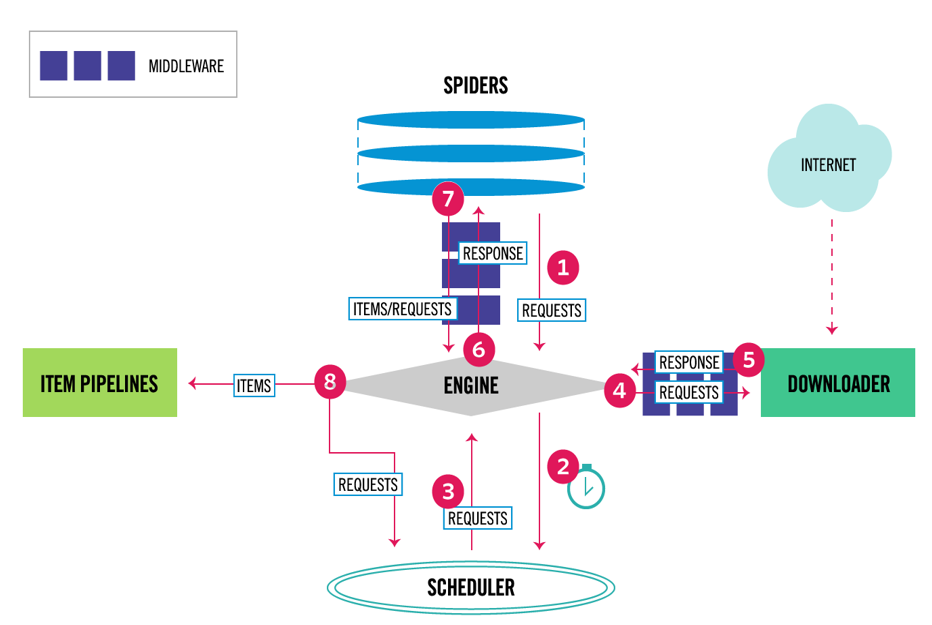
首先从爬虫获取初始的请求
将请求放入调度模块,然后获取下一个需要爬取的请求
调度模块返回下一个需要爬取的请求给引擎
引擎将请求发送给下载器,依次穿过所有的下载中间件
一旦页面下载完成,下载器会返回一个响应包含了页面数据,然后再依次穿过所有的下载中间件
引擎从下载器接收到响应,然后发送给爬虫进行解析,依次穿过所有的爬虫中间件
爬虫处理接收到的响应,然后解析出item和生成新的请求,并发送给引擎
引擎将已经处理好的item发送给管道组件,将生成好的新的请求发送给调度模块,并请求下一个请求
该过程重复,直到调度程序不再有请求为止
组件
spiders 爬虫程序 处理response 提取需要的数据 或其他要抓取的请求
engine 引擎 引擎负责控制系统所有组件之间的数据流,并在发生某些操作时触发事件
scheduler调度器 接收request请求 排队加入队列
download下载器 负责引擎发送过来的request请求 进行下载
item pipelines 管道 负责spider返回的数据 进行存储
中间件
下载中间件
下载中间件是位于引擎和下载器之间的特定的钩子,它们处理从引擎传递到下载器的请求,以及下载器传递到引擎的响应
使用Downloader中间件执行以下操作
在请求发送到下载程序之前处理请求(即在scrapy将请求发送到网站之前)
在响应发送给爬虫之前
直接发送新的请求,而不是将收到的响应传递给蜘蛛
将响应传递给爬行器而不获取web页面
默默的放弃一些请求
爬虫中间件
爬虫中间件是位于引擎和爬虫之间的特定的钩子,能够处理传入的响应和传递出去的item和请求
使用爬虫中间件执行以下操作
处理爬虫回调之后的 请求或item
处理start_requests
处理爬虫异常
根据响应内容调用errback而不是回调请求
事件驱动的网络
scrapy是用Twisted编写的,Twisted是一个流行的事件驱动的Python网络框架。它使用非阻塞(也称为异步)代码实现并发
Scrapy安装和简单使用的更多相关文章
- Python爬虫框架--Scrapy安装以及简单实用
scrapy框架 框架 -具有很多功能且具有很强通用性的一个项目模板 环境安装: Linux: pip3 install scrapy Windows: ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- python Scrapy安装和介绍
python Scrapy安装和介绍 Windows7下安装1.执行easy_install Scrapy Centos6.5下安装 1.库文件安装yum install libxslt-devel ...
- 转:Scrapy安装、爬虫入门教程、爬虫实例(豆瓣电影爬虫)
Scrapy在window上的安装教程见下面的链接:Scrapy安装教程 上述安装教程已实践,可行.(本来打算在ubuntu上安装Scrapy的,但是Ubuntu 磁盘空间太少了,还没扩展磁盘空间,所 ...
- Scrapy安装、爬虫入门教程、爬虫实例(豆瓣电影爬虫)
Scrapy在window上的安装教程见下面的链接:Scrapy安装教程 上述安装教程已实践,可行.(本来打算在ubuntu上安装Scrapy的,但是Ubuntu 磁盘空间太少了,还没扩展磁盘空间,所 ...
- python爬虫框架—Scrapy安装及创建项目
linux版本安装 pip3 install scrapy 安装完成 windows版本安装 pip install wheel 下载twisted,网址:http://www.lfd.uci.edu ...
- 第五篇 scrapy安装及目录结构,启动spider项目
实际上安装scrapy框架时,需要安装很多依赖包,因此建议用pip安装,这里我就直接使用pycharm的安装功能直接搜索scrapy安装好了. 然后进入虚拟环境创建一个scrapy工程: (third ...
- scrapy安装及入门使用
scrapy安装及入门使用 安装 pip3.7 install Scrapy 输入scrapy命令查看是否安装成功 J-pro:myproject will$ scrapy Scrapy 2.1.0 ...
随机推荐
- 让终端更好看--Ubuntu OhMyZsh配置指南
查看shell列表 cat /etc/shells 如果发现没有zsh就安装 安装zsh sudo apt install zsh 设置默认shell chsh -s $(which zsh) 重启主 ...
- Nginx模块及配置虚拟主机
1.Nginx的2组主要的模块 (1)core modules (必需,核心模块) 包括:Main.Events (2)Standard HTTP modules(虽然不是必需,但是缺省都会安装,不建 ...
- 死磕 java线程系列之线程池深入解析——构造方法
(手机横屏看源码更方便) 注:java源码分析部分如无特殊说明均基于 java8 版本. 简介 ThreadPoolExecutor的构造方法是创建线程池的入口,虽然比较简单,但是信息量很大,由此也能 ...
- code snippet:依赖属性propa的小技巧
很早之前就玩过VS里面的code snippet,相当方便. 今天在用prop自动属性代码时,无意中用了一下propa,然后就自动出来了依赖属性的代码片段,太方便了,尤其是对于WPF新手来说,比如我这 ...
- vue中计算属性的get与set方法
计算属性get set方法 在vue的计算属性中,所定义的都是属性,可以直接调用 正常情况下,计算属性中的每一个属性对应的都是一个对象,对象中包括了set方法与get方法 computed:{ ful ...
- JWT基础知识
1> JWT定义 JSON Web Token (JWT) 是一种开放的行业标准(RFC 7519),用于安全传送认证信息. 是目前流行的跨域认证的解决方案. 2> JWT数据结构 由三部 ...
- 数据库学习笔记day04
--row_number()over(partition by xxx order by xxx)分组排序函数 特点:组内连续且唯一select ename,sal,deptno,row_number ...
- 使用objc runtime实现iOS绿色的懒加载
使用objc runtime实现懒加载 地址:AutoPropertyCocoa 本文所指懒加载形式如下 - (id)lazyloadProperty{ if(_lazyloadProperty == ...
- c#串口通信并处理接收的多个参数
最近摸索做个上位机,简单记录一下关键的几个部分 c#做串口通信主要使用的是System.IO.Ports类,其实还是十分方便的 最终效果如下: 千万不要忘记了下面这个 填写串口相关配置 我们可以通过G ...
- 浮点运算与boost.multiprecision
在C++中,float占4个字节,double占8个字节,均采用 IEEE 754 浮点标准:内部都是以二进制为基础,表述实数,有些实数可以被精确表述,比如0.2,但有些不行,比如0.3.针对这一点, ...