python爬虫(2)——urllib、get和post请求、异常处理、浏览器伪装
urllib基础
urlretrieve()
urlretrieve(网址,本地文件存储地址) 直接下载网页到本地
import urllib.request
#urlretrieve(网址,本地文件存储地址) 直接下载网页到本地
urllib.request.urlretrieve("http://www.baidu.com","dld.html")
urlcleanup()
清除缓存
urllib.request.urlcleanup()
info()
查看网页简介
file=urllib.request.urlopen("http://www.baidu.com")
print(file.info())
getcode()
输出网页爬取状态码,200为正常,其他都不正常
file=urllib.request.urlopen("http://www.baidu.com")
print(file.getcode())
geturl()
获取当前访问的网页的url
file=urllib.request.urlopen("http://www.baidu.com")
print(file.geturl())
超时设置
timeout设置为多少秒才判断超时
import urllib.request
for i in range(1000):
try:
file = urllib.request.urlopen("https://www.cnblogs.com/mcq1999/", timeout=1)
print(len(file.read().decode("utf-8")))
except Exception as e:
print("出现异常")
自动模拟HTTP请求
get请求
模拟百度搜索python:
import urllib.request
import re
keywd="python"
url="http://www.baidu.com/s?wd="+keywd
data=urllib.request.urlopen(url).read().decode("utf-8")
pat='{"title":"(.*?)",'
res=re.compile(pat).findall(data)
print(res)
关键字为中文:
import urllib.request
import re
keywd="百度"
keywd=urllib.request.quote(keywd) #如果有中文
url="http://www.baidu.com/s?wd="+keywd
data=urllib.request.urlopen(url).read().decode("utf-8")
pat='{"title":"(.*?)",'
res=re.compile(pat).findall(data)
print(res)
提取前1~10页:
import urllib.request
import re
keywd="百度"
keywd=urllib.request.quote(keywd) #如果有中文
# 页码公式:page=(num-1)*10
for i in range(1,11):
url="http://www.baidu.com/s?wd="+keywd+"&pn="+str((i-1)*10)
data=urllib.request.urlopen(url).read().decode("utf-8")
pat='{"title":"(.*?)",'
res=re.compile(pat).findall(data)
for j in range(len(res)):
print(res[j])
post请求
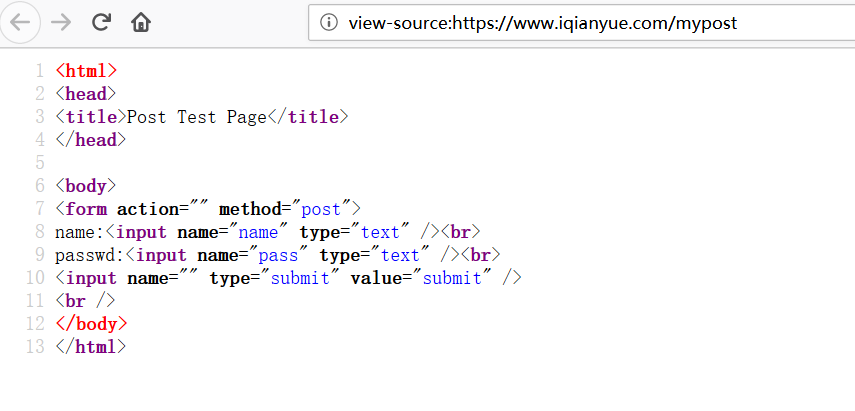
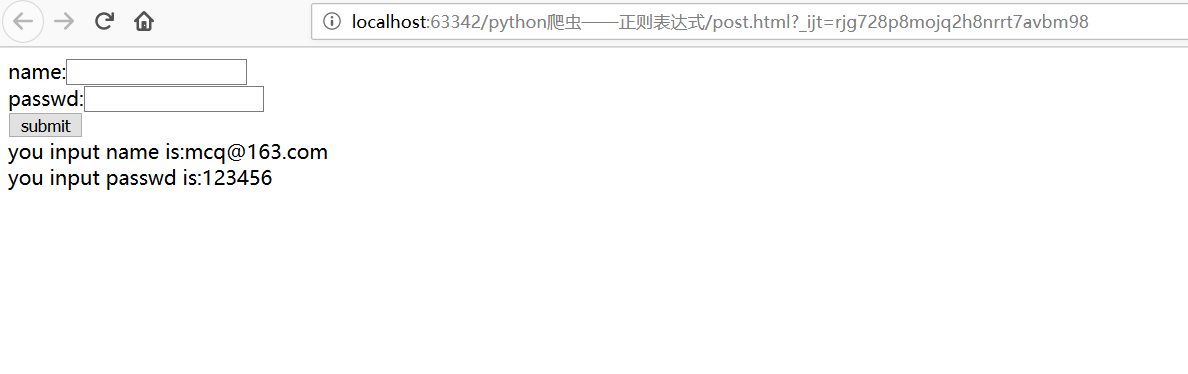
import urllib.request
import urllib.parse
posturl="https://www.iqianyue.com/mypost"
postdata=urllib.parse.urlencode({
"name":"mcq@163.com",
"pass":"123456",
}).encode("utf-8")
#进行post,需要使用urllib.request下面的Request(真实post地址,post数据)
req=urllib.request.Request(posturl,postdata)
res=urllib.request.urlopen(req).read().decode("utf-8")
print(res)
fh=open("post.html","w")
fh.write(res)
爬虫的异常处理
如果没有异常处理,爬虫遇到异常时就会直接崩溃停止运行,下次再次运行时,又会从头开始,所以,要开发一个具有顽强生命力的爬虫,必须要进行异常处理。
常见状态码及含义

HTTPError和URLError
两者都是异常处理的类,HTTPError是URLError的子类,HTTPError有异常状态码与异常原因,URLError没有异常状态码,所以在处理的时候,不能使用URLError直接代替HTTPError。如果要代替,必须要判断是否有状态码属性。
URLError出现的原因:
- 连不上服务器
- 远程url不存在
- 无网络
- 触发HTTPError
import urllib.request
import urllib.error
for i in range(20):
try:
urllib.request.urlopen("https://www.cnblogs.com/mcq1999/p/python_Crawler_1.html")
print("gg")
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
浏览器伪装技术
有的网站爬取的时候会返回403,因为对方服务器会对爬虫进行屏蔽。此时,我们要伪装成浏览器才能爬取。
浏览器伪装一般通过报头实现。
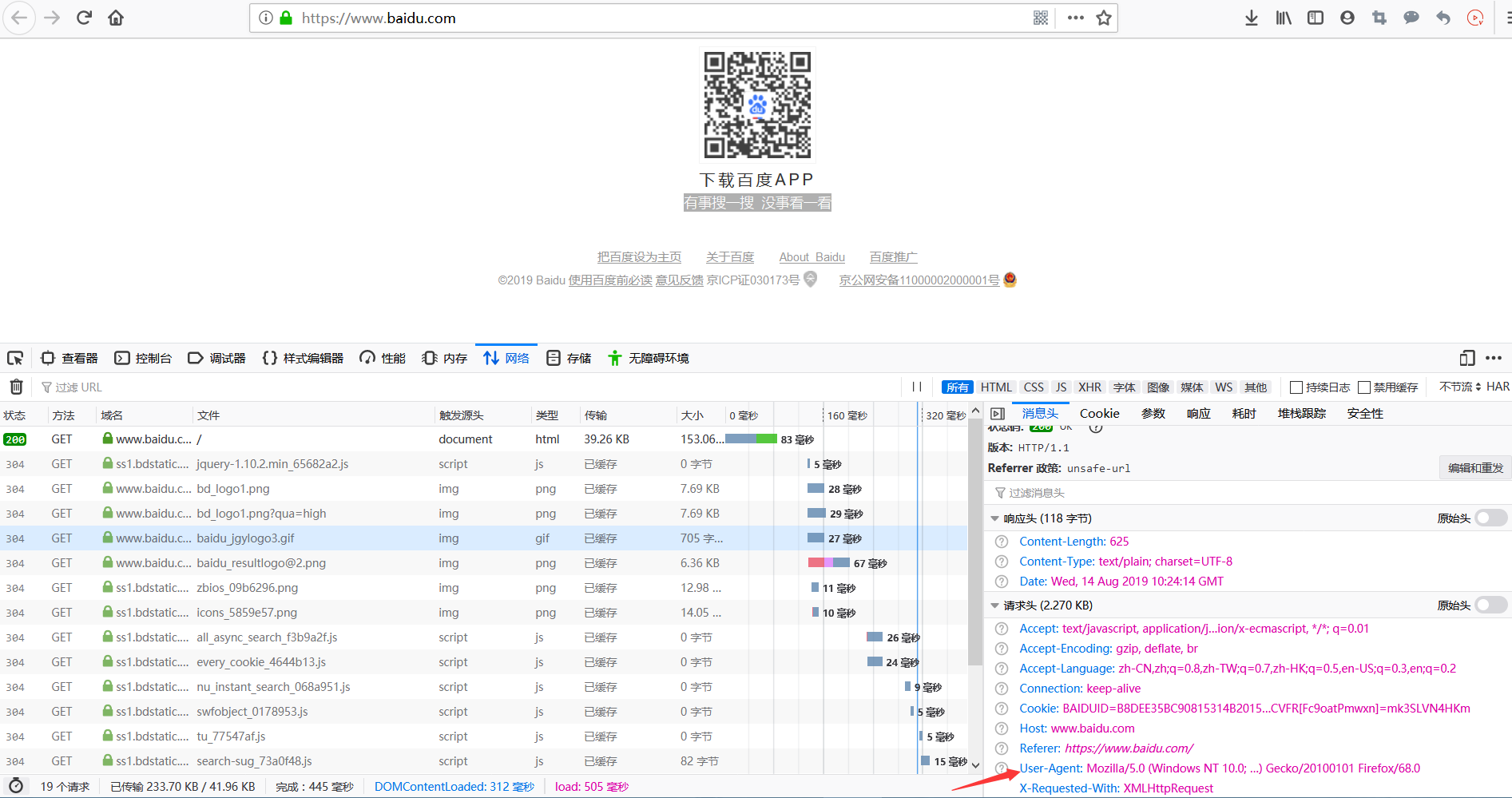
由于urlopen()对于一些HTTP的高级功能不支持,所以要修改报头,可以使用urllib.request.build_opener()或urllib.request.Request()下的add_header()实现浏览器的模拟。
opener的全局安装在下面的糗事百科爬虫里有应用
import urllib.request
url="https://blog.csdn.net/"
#头文件格式header=("User-Agent",具体用户代理制)
headers=("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0")
opener=urllib.request.build_opener()
opener.addheaders=[headers]
data=opener.open(url).read()
fh=open("ua.html","wb")
fh.write(data)
fh.close()
python新闻爬虫实战
需求:将新浪新闻首页所有新闻都爬倒本地
思路:先爬首页,通过正则表达式获取所有新闻链接,然后依次爬各新闻,并存储到本地
import urllib.request
import re
url="https://news.sina.com.cn/"
data=urllib.request.urlopen(url).read().decode("utf-8","ignore") #忽略有异常的编码
pat1='<a target="_blank" href="(.*?)"'
alllink=re.compile(pat1).findall(data)
for i in range(len(alllink)):
thislink=alllink[i]
urllib.request.urlopen(thislink).read().decode("utf-8","ignore")
urllib.request.urlretrieve(thislink,"news/"+str(i)+".html")
糗事百科爬取
目标1:爬取糗事百科首页的内容(包括视频、图片)
涉及伪装浏览器、opener安装为全局等知识
import urllib.request
import re
url="https://www.qiushibaike.com/"
#测试是否需要伪装浏览器
try:
urllib.request.urlopen(url)
except Exception as e:
print(e)
#显示Remote end closed connection without response,要伪装
headers=("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0")
opener=urllib.request.build_opener()
opener.addheaders=[headers]
urllib.request.install_opener(opener) #安装为全局
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
pat='<a class="recmd-content" href="/(.*?)"'
alllink=re.compile(pat).findall(data)
for i in range(len(alllink)):
realurl=url+alllink[i]
print(realurl)
urllib.request.urlretrieve(realurl,"糗事百科/"+str(i)+".html")
目标2:爬取1~10页的文章
import urllib.request
import re
headers=("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0")
opener=urllib.request.build_opener()
opener.addheaders=[headers]
urllib.request.install_opener(opener) #安装为全局
for i in range(10):
thisurl="https://www.qiushibaike.com/text/page/"+str(i+1)+"/";
data=urllib.request.urlopen(thisurl).read().decode("utf-8","ignore")
pat='<div class="content">.*?<span>(.*?)</span>.*?</div>'
res=re.compile(pat,re.S).findall(data)
for j in range(len(res)):
print(res[j])
print('---------------------')
python爬虫(2)——urllib、get和post请求、异常处理、浏览器伪装的更多相关文章
- python爬虫之urllib库(三)
python爬虫之urllib库(三) urllib库 访问网页都是通过HTTP协议进行的,而HTTP协议是一种无状态的协议,即记不住来者何人.举个栗子,天猫上买东西,需要先登录天猫账号进入主页,再去 ...
- python爬虫之urllib库(二)
python爬虫之urllib库(二) urllib库 超时设置 网页长时间无法响应的,系统会判断网页超时,无法打开网页.对于爬虫而言,我们作为网页的访问者,不能一直等着服务器给我们返回错误信息,耗费 ...
- python爬虫之urllib库(一)
python爬虫之urllib库(一) urllib库 urllib库是python提供的一种用于操作URL的模块,python2中是urllib和urllib2两个库文件,python3中整合在了u ...
- Python爬虫之urllib模块2
Python爬虫之urllib模块2 本文来自网友投稿 作者:PG-55,一个待毕业待就业的二流大学生. 看了一下上一节的反馈,有些同学认为这个没什么意义,也有的同学觉得太简单,关于Beautiful ...
- Python爬虫之urllib模块1
Python爬虫之urllib模块1 本文来自网友投稿.作者PG,一个待毕业待就业二流大学生.玄魂工作室未对该文章内容做任何改变. 因为本人一直对推理悬疑比较感兴趣,所以这次爬取的网站也是平时看一些悬 ...
- Python爬虫之urllib.parse详解
Python爬虫之urllib.parse 转载地址 Python 中的 urllib.parse 模块提供了很多解析和组建 URL 的函数. 解析url 解析url( urlparse() ) ur ...
- 第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术.设置用户代理 如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执 ...
- python爬虫之urllib库介绍
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
- 小白学 Python 爬虫(32):异步请求库 AIOHTTP 基础入门
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- Python 爬虫之urllib库的使用
urllib库 urllib库是Python中一个最基本的网络请求库.可以模拟浏览器的行为,向指定的服务器发送一个请求,并可以保存服务器返回的数据. urlopen函数: 在Python3的urlli ...
随机推荐
- 002 C/C++ 数组的传递
传递一个数组给一个函数的正确做法: 1.传递数组的内存首地址. 2.传递数组的有效长度.指数组的元素数量. 编译器总是将数组类型的变量作为指针传递. 计算数组的长度: int length = siz ...
- vue跨域
比如 我要请求的地址是https://edu.51cto.com/center/seckill/index/get-seckill-data 首先去 config ==> index.js 添加 ...
- git(1) 比较两个不同版本的文件
git diff commit_id1:file_name commit_id2:file_name 或者 git diff commit_id1 commit_id2 -- file_name co ...
- Re-DD-androideasy
题目地址 https://dn.jarvisoj.com/challengefiles/DDCTF-Easy.apk.64812266499cc050ac23e190e53b87f7 用JEB打开 返 ...
- 如何在Markdown格式下插入动图/gif
上传GIF动图与上传普通图片是一样的,都需要以下在markdown语法中 ![]() 的小括号内填写图片的地址.问题在于如何获取本地gif的地址呢? 核心的东西就是要把这个gif动图传上网络,这样图片 ...
- Linux运维基础篇大全
基础知识的文章都在这里https://www.jianshu.com/u/a3c215af055a ,想要了解,请访问这个地址!!!!
- 基于TCP协议的socket套接字编程
目录 一.什么是Scoket 二.套接字发展史及分类 2.1 基于文件类型的套接字家族 2.2 基于网络类型的套接字家族 三.套接字工作流程 3.1 服务端套接字函数 3.2 客户端套接字函数 3.3 ...
- beego安装错误处理
1. 安装beego时无法安装go依赖包 解决办法: $vim ~/.bashrc export GOPROXY=https://goproxy.io $source ~/.bashrc$go get ...
- vscode源码分析【七】主进程启动消息通信服务
第一篇: vscode源码分析[一]从源码运行vscode 第二篇:vscode源码分析[二]程序的启动逻辑,第一个窗口是如何创建的 第三篇:vscode源码分析[三]程序的启动逻辑,性能问题的追踪 ...
- DirectShow 简介
一.DirectShow 简介 DirectShow(简称 DShow) 是一个 Windows 平台上的流媒体框架,提供了高质量的多媒体流采集和回放功能.它支持多种多样的媒体文件格式,包括 ASF. ...