Python3数据驱动ddt
对于同一个方法执行大量数据的程序时,我们可以采用ddt数据驱动的方式,来对数据规范化整理及输出
一、需要使用python的ddt库,ddt,data,unpack方法
1、仅使用ddt和data,代码如下
import unittest
from ddt import ddt, data, unpack test_data = (1, 2, 3)
@ddt # 需要在要引用的类前面加上 @ddt声明
class TestAdd(unittest.TestCase):
@data(test_data) # 调用ddt的数据
def test_add(self, a):
print(a)
test_add函数那里的形参a可以随便定义,程序会自动去接收 @data里面的值
输出结果
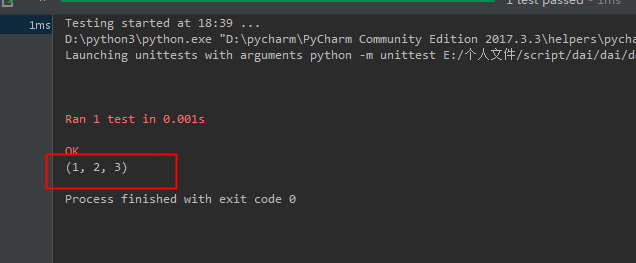
2、使用unpack功能,此方法主要是拆分数据类型,例如元组(1, 2, 3),在data下面加上 unpack后,会将数据类型拆分为
"""元组、列表数据驱动"""
import unittest
from ddt import ddt, data, unpack test_data = ((1, 2, 3), (4, 5, 6), (7, 8, 9))
@ddt # 需要在要引用的类前面加上 @ddt声明
class TestAdd(unittest.TestCase):
@data(test_data) # 调用ddt的数据
@unpack
def test_add(self, a, b, c):
print('数据类型为', type(a), '数值为', a)
print('数据类型为', type(b), '数值为', b)
print('数据类型为', type(c), '数值为', c)
输出结果为:

会将test_data大元组拆分为,子类数值,并自动匹配数据类型。 例如将初始数据变为列表类型,并且列表里面的项未字符类型时
import unittest
from ddt import ddt, data, unpack #test_data = ((1, 2, 3), (4, 5, 6), (7, 8, 9))
test_data = ['A', 'B', 'C']
@ddt # 需要在要引用的类前面加上 @ddt声明
class TestAdd(unittest.TestCase):
@data(test_data) # 调用ddt的数据
@unpack
def test_add(self, a, b, c):
print('数据类型为', type(a), '数值为', a)
print('数据类型为', type(b), '数值为', b)
print('数据类型为', type(c), '数值为', c)
结果如下:
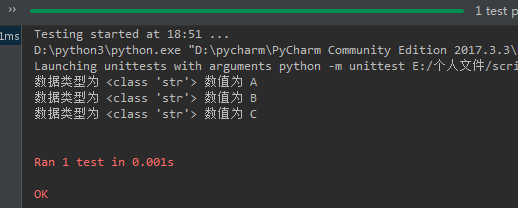
所以,ddt和data可以实现数据调用, unpack能对调用的大量数据进行拆分,得到最小等分的数据并进行使用。 注意,拆分之后的数据在函数test_data引用时,形参要和拆分的数量一致,即拆分了3个变量,那么我们调用函数的形参也必须是3个a,b,c (形参变量名不限,可以任意取,除了系统关键字)
二、对字典类型的数据进行数据驱动及拆分
字典是以键对值的形式来展示的,调用和拆分与列表、元组一样。 唯一不同点,在调用函数引用时,形参必须是字典的键值
"""字典类型数据驱动"""
import unittest
from ddt import ddt, data, unpack test_data = {"tall": 180, "sex": "boy"}
@ddt
class TestAdd(unittest.TestCase):
@data(test_data)
@unpack
def test_add(self, tall, sex): # 此处的形参必须要是字典的键值
print("身高是", tall, "性别是", sex)
运行结果:
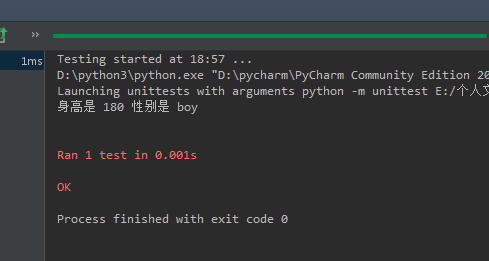
三、拓展使用
我们在进行数据驱动时,一般是从excel中读取数据,然后引用。 excel中的数据读取
from openpyxl import load_workbook class ReadExcel: # 读取Excel里面的内容
def __init__(self, file_name, sheet_name):
self.file_name = file_name
self.sheet_name = sheet_name def get_title(self): # 读取Excel里面的title数据
wb = load_workbook(self.file_name) # 打开Excel工作簿
sheet1 = wb[self.sheet_name]
title = [] # 定义一个空列表,将读取的title字段进行存储
for i in range(1, sheet1.max_column+1):
title.append(sheet1.cell(1, i).value)
return title def do_excel(self):
wb = load_workbook(self.file_name)
sheet1 = wb[self.sheet_name]
title = self.get_title() # 调用title内容
all_data = []
for j in range(2, sheet1.max_row+1): # 获取最大行数,加入循环
row_data={}
for i in range(3, sheet1.max_column+1): # 获取最大列数,进行嵌套循环
row_data[title[i-1]] = sheet1.cell(j, i).value # 把拿到的数据进行字典的键对值匹配
all_data.append(row_data)
return all_data
然后ddt进行引用即可
Python3数据驱动ddt的更多相关文章
- python webdriver 测试框架-数据驱动DDT的例子
先在cmd环境 运行 pip install ddt 安装数据驱动ddt模块 脚本: #encoding=utf-8 from selenium import webdriver import un ...
- Python 数据驱动ddt 使用
准备工作: pip install ddt 知识点: 一,数据驱动和代码驱动: 数据驱动的意思是 根据你提供的数据来测试的 比如 ATP框架 需要excel里面的测试用例 代码驱动是必须得写代码 ...
- 数据驱动ddt
在设计用例的时候,有些用例操作过程是一样的,只是参数数据输入的不同,如果用例重复的去写操作过程会增加代码量,对于这种多组数据的测试用例,可以使用数据驱动设计模式,一组数据对应一个测试用例,用例自动加载 ...
- unittest使用数据驱动ddt
简介 ddt(data driven test)数据驱动测试:由外部数据集合来驱动测试用例,适用于测试方法不变,但需要大量变化的数据进行测试的情况,目的就是为了数据和测试步骤的分离 由于unittes ...
- Python数据驱动DDT的应用
在开始之前,我们先来明确一下什么是数据驱动,在百度百科中数据驱动的解释是:数据驱动测试,即黑盒测试(Black-box Testing),又称为功能测试,是把测试对象看作一个黑盒子.利用黑盒测试法进行 ...
- python接口自动化测试 - 数据驱动DDT模块的简单使用
DDT简单介绍 名称:Data-Driven Tests,数据驱动测试 作用:由外部数据集合来驱动测试用例的执行 核心的思想:数据和测试代码分离 应用场景:一组外部数据来执行相同的操作 优点:当测试数 ...
- unittest---unittest数据驱动(ddt)
在做测试的时候,有些地方无论是接口还是UI只是参数数据的输入不一样,操作过程是一样的.重复去写操作过程会增加代码量,我们可以通过参数化的方式解决这个问题,也叫做数据驱动,我们通过python做参数化的 ...
- python之数据驱动ddt操作(方法三)
import unittestfrom selenium import webdriverfrom selenium.webdriver.common.by import Byimport unitt ...
- python之数据驱动ddt操作(方法二)
import unittestfrom ddt import ddt,unpack,datafrom selenium import webdriverfrom selenium.webdriver. ...
随机推荐
- 节能减排到底如何----google earth engine 告诉你!!
(First,再次严谨说明,本人成果未经允许,切勿发表到相关学术期刊,如果有技术交流,qq1044625113,顺便打个广告,兼职GEE开发,欢迎联系!) 终于过了严寒的冬天,2017年的冬天中国南方 ...
- Azkaban学习之路(二)—— Azkaban 3.x 编译及部署
一.Azkaban 源码编译 1.1 下载并解压 Azkaban 在3.0版本之后就不提供对应的安装包,需要自己下载源码进行编译. 下载所需版本的源码,Azkaban的源码托管在GitHub上,地址为 ...
- python算法与数据结构-二叉树的代码实现(46)
一.二叉树回忆 上一篇我们对数据结构中常用的树做了介绍,本篇博客主要以二叉树为例,讲解一下树的数据结构和代码实现.回顾二叉树:二叉树是每个节点最多有两个子树的树结构.通常子树被称作“左子树”(left ...
- python 基本数据类型之列表
#列表是可变类型,可以增删改查#字符串不可变类型,不能修改,只能生成新的值. #1.追加 # user_list = ['李泉','刘一','刘康','豆豆','小龙'] # user_list.ap ...
- mac-VBox-Centos6.6安装增强功能
1. 更新内核 yum update kernel 2.安装依赖包 yum install kernel-headers yum install kernel-devel yum install gc ...
- POJ 1966:Cable TV Network(最小点割集)***
http://poj.org/problem?id=1966 题意:给出一个由n个点,m条边组成的无向图.求最少去掉多少点才能使得图中存在两点,它们之间不连通. 思路:将点i拆成a和b,连一条a-&g ...
- K2工作流引擎Demo
---恢复内容开始--- 以前的工作都是电商网站形式的,从未接触过工作流相关工作,新公司是传统制造业行业,我进的这个组又是做工作流这块相关工作的,所以避免不了和工作流打交道. 这边工作流主要用K2来做 ...
- Oracle数据库---异常处理
Oracle异常处理在PL/SQL语句书写时,需要处理的异常-- 不做异常处理时DECLARE v_name emp.ename%TYPE; v_sal emp.sal%TYPE;BEGIN SELE ...
- 常见Code Review过程中发现的问题
软件环境:Spring MVC + MyBatis 主要体现在两个方面,一个是编码习惯问题,另一个是编码质量的问题.编码习惯主要有日志编写.代码注释以及编码风格的问题,而编码质量则与很多方面相关,比如 ...
- mysql in与exists问题剖析
1 问题描述 发布当天发现一个日志分析的sql,在测试环境上执行良好,1秒内,而在线上环境上,执行要13秒左右. 嵌套sql一步一步分析后,发现出在in上,因时间紧迫,来补不及具体分析原因,尝试使 ...