Python3数据驱动ddt
对于同一个方法执行大量数据的程序时,我们可以采用ddt数据驱动的方式,来对数据规范化整理及输出
一、需要使用python的ddt库,ddt,data,unpack方法
1、仅使用ddt和data,代码如下
import unittest
from ddt import ddt, data, unpack test_data = (1, 2, 3)
@ddt # 需要在要引用的类前面加上 @ddt声明
class TestAdd(unittest.TestCase):
@data(test_data) # 调用ddt的数据
def test_add(self, a):
print(a)
test_add函数那里的形参a可以随便定义,程序会自动去接收 @data里面的值
输出结果
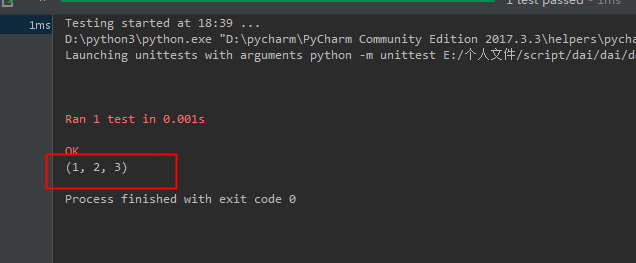
2、使用unpack功能,此方法主要是拆分数据类型,例如元组(1, 2, 3),在data下面加上 unpack后,会将数据类型拆分为
"""元组、列表数据驱动"""
import unittest
from ddt import ddt, data, unpack test_data = ((1, 2, 3), (4, 5, 6), (7, 8, 9))
@ddt # 需要在要引用的类前面加上 @ddt声明
class TestAdd(unittest.TestCase):
@data(test_data) # 调用ddt的数据
@unpack
def test_add(self, a, b, c):
print('数据类型为', type(a), '数值为', a)
print('数据类型为', type(b), '数值为', b)
print('数据类型为', type(c), '数值为', c)
输出结果为:

会将test_data大元组拆分为,子类数值,并自动匹配数据类型。 例如将初始数据变为列表类型,并且列表里面的项未字符类型时
import unittest
from ddt import ddt, data, unpack #test_data = ((1, 2, 3), (4, 5, 6), (7, 8, 9))
test_data = ['A', 'B', 'C']
@ddt # 需要在要引用的类前面加上 @ddt声明
class TestAdd(unittest.TestCase):
@data(test_data) # 调用ddt的数据
@unpack
def test_add(self, a, b, c):
print('数据类型为', type(a), '数值为', a)
print('数据类型为', type(b), '数值为', b)
print('数据类型为', type(c), '数值为', c)
结果如下:
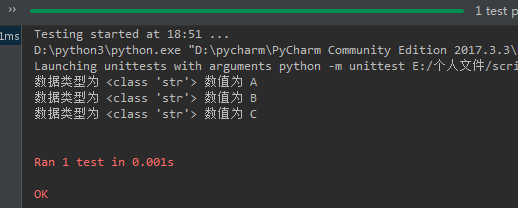
所以,ddt和data可以实现数据调用, unpack能对调用的大量数据进行拆分,得到最小等分的数据并进行使用。 注意,拆分之后的数据在函数test_data引用时,形参要和拆分的数量一致,即拆分了3个变量,那么我们调用函数的形参也必须是3个a,b,c (形参变量名不限,可以任意取,除了系统关键字)
二、对字典类型的数据进行数据驱动及拆分
字典是以键对值的形式来展示的,调用和拆分与列表、元组一样。 唯一不同点,在调用函数引用时,形参必须是字典的键值
"""字典类型数据驱动"""
import unittest
from ddt import ddt, data, unpack test_data = {"tall": 180, "sex": "boy"}
@ddt
class TestAdd(unittest.TestCase):
@data(test_data)
@unpack
def test_add(self, tall, sex): # 此处的形参必须要是字典的键值
print("身高是", tall, "性别是", sex)
运行结果:
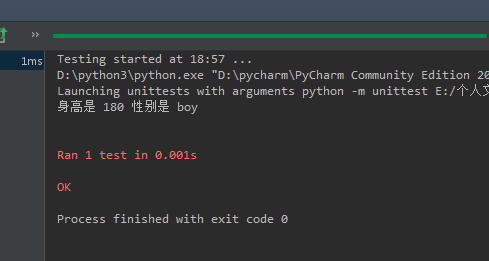
三、拓展使用
我们在进行数据驱动时,一般是从excel中读取数据,然后引用。 excel中的数据读取
from openpyxl import load_workbook class ReadExcel: # 读取Excel里面的内容
def __init__(self, file_name, sheet_name):
self.file_name = file_name
self.sheet_name = sheet_name def get_title(self): # 读取Excel里面的title数据
wb = load_workbook(self.file_name) # 打开Excel工作簿
sheet1 = wb[self.sheet_name]
title = [] # 定义一个空列表,将读取的title字段进行存储
for i in range(1, sheet1.max_column+1):
title.append(sheet1.cell(1, i).value)
return title def do_excel(self):
wb = load_workbook(self.file_name)
sheet1 = wb[self.sheet_name]
title = self.get_title() # 调用title内容
all_data = []
for j in range(2, sheet1.max_row+1): # 获取最大行数,加入循环
row_data={}
for i in range(3, sheet1.max_column+1): # 获取最大列数,进行嵌套循环
row_data[title[i-1]] = sheet1.cell(j, i).value # 把拿到的数据进行字典的键对值匹配
all_data.append(row_data)
return all_data
然后ddt进行引用即可
Python3数据驱动ddt的更多相关文章
- python webdriver 测试框架-数据驱动DDT的例子
先在cmd环境 运行 pip install ddt 安装数据驱动ddt模块 脚本: #encoding=utf-8 from selenium import webdriver import un ...
- Python 数据驱动ddt 使用
准备工作: pip install ddt 知识点: 一,数据驱动和代码驱动: 数据驱动的意思是 根据你提供的数据来测试的 比如 ATP框架 需要excel里面的测试用例 代码驱动是必须得写代码 ...
- 数据驱动ddt
在设计用例的时候,有些用例操作过程是一样的,只是参数数据输入的不同,如果用例重复的去写操作过程会增加代码量,对于这种多组数据的测试用例,可以使用数据驱动设计模式,一组数据对应一个测试用例,用例自动加载 ...
- unittest使用数据驱动ddt
简介 ddt(data driven test)数据驱动测试:由外部数据集合来驱动测试用例,适用于测试方法不变,但需要大量变化的数据进行测试的情况,目的就是为了数据和测试步骤的分离 由于unittes ...
- Python数据驱动DDT的应用
在开始之前,我们先来明确一下什么是数据驱动,在百度百科中数据驱动的解释是:数据驱动测试,即黑盒测试(Black-box Testing),又称为功能测试,是把测试对象看作一个黑盒子.利用黑盒测试法进行 ...
- python接口自动化测试 - 数据驱动DDT模块的简单使用
DDT简单介绍 名称:Data-Driven Tests,数据驱动测试 作用:由外部数据集合来驱动测试用例的执行 核心的思想:数据和测试代码分离 应用场景:一组外部数据来执行相同的操作 优点:当测试数 ...
- unittest---unittest数据驱动(ddt)
在做测试的时候,有些地方无论是接口还是UI只是参数数据的输入不一样,操作过程是一样的.重复去写操作过程会增加代码量,我们可以通过参数化的方式解决这个问题,也叫做数据驱动,我们通过python做参数化的 ...
- python之数据驱动ddt操作(方法三)
import unittestfrom selenium import webdriverfrom selenium.webdriver.common.by import Byimport unitt ...
- python之数据驱动ddt操作(方法二)
import unittestfrom ddt import ddt,unpack,datafrom selenium import webdriverfrom selenium.webdriver. ...
随机推荐
- Scala 学习之路(五)—— 集合类型综述
一.集合简介 Scala中拥有多种集合类型,主要分为可变的和不可变的集合两大类: 可变集合: 可以被修改.即可以更改,添加,删除集合中的元素: 不可变集合类:不能被修改.对集合执行更改,添加或删除操作 ...
- 如何把设计稿中px值转化为想要的rem值
首先我们需要的是把尺寸转化为rem值 假如 设计稿中的是 200px*200px的图片 移动端的设计图尺寸一般是640*750; 第一步. 把图片分为若干份(好算即可),每一份的大小就是rem的单位 ...
- 嵌入式物联网32 ARM linux 等创客学院学习视频共享给大家
大家手机号登录学习链接即可观看 有坛友说手机号登录不上 具体自测 http://www.makeru.com.cn/live/1392_303.html?s=60220走进嵌入式http:// ...
- Codeforces 755D:PolandBall and Polygon(思维+线段树)
http://codeforces.com/problemset/problem/755/D 题意:给出一个n正多边形,还有k,一开始从1出发,向第 1 + k 个点连一条边,然后以此类推,直到走完 ...
- scrapy基础知识之 CrawlSpiders爬取lagou招聘保存在mysql(分布式):
items.py import scrapy class LagouItem(scrapy.Item): # define the fields for your item here like: # ...
- echo-nginx-module的安装、配置、使用
一.下载压缩包 [root@www nginx-1.16.0]# wget https://github.com/openresty/echo-nginx-module/archive/v0.61.t ...
- Spring Cloud 之 Hystrix.
一.概述 在微服务架构中,我们将系统拆分成了很多服务单元,各单元的应用间通过服务注册与订阅的方式互相依赖.由于每个单元都在不同的进程中运行,依赖通过远程调用的方式执行,这样就有可能因为网络原因或是依 ...
- c++学习书籍推荐《Exceptional C++ Style》下载
百度云及其他网盘下载地址:点我 编辑推荐 软件“风格”所要讨论的主题是如何在开销与功能之间.优雅与可维护性之间.灵活.性与过分灵活之间寻找完美的平街点.在本书中,著名的C++大师Herb Sutter ...
- mysql中id值被重置的情况
MySQL中,如果你为一张使用了innodb引擎的表指定了一auto_increment列,那么这张表会有一个auto_increment计数器,专门记录当前auto_increment的相关值,用来 ...
- 「玩转Python」突破封锁继续爬取百万妹子图
前言 从零学 Python 案例,自从提交第一个妹子图版本引来了不少小伙伴的兴趣.最近,很多小伙伴发来私信说,妹子图不能爬了!? 趁着周末试了一把,果然爬不动了,爬下来的都是些 0kb 的假图片,然后 ...