Redis HyperLogLog用法简介
(1)HyperLogLog简介
在Redis 在 2.8.9 版本才添加了 HyperLogLog,HyperLogLog算法是用于基数统计的算法,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。HyperLogLog适用于大数据量的统计,因为成本相对来说是更低的,最多也就占用12kb内存
业务场景,HyperLogLog常用于大数据量的统计,比如页面访问量统计或者用户访问量统计
举个例子,假如要统计一个页面的访问量(PV),这个还比较好办,可以直接用redis计数器或者直接存数据库都可以做,然后如果再加需求,现在要统计一个页面的用户访问量(UV),一个用户一天内如果访问多次的话,也只能算一次,这样的话,你可能会想到用SET集合来做,因为SET集合是有去重功能的,key存储页面对应的关键字,value存储对应userId,这种方法是可行,可是访问量一多的话,假如有几千万访问量,那就麻烦了,为了统计一个访问量,要频繁创建SET集合对象
那有其它方法吗?针对上面大访问量的情况,redis是有实现了HyperLogLog算法,HyperLogLog 这个数据结构的发明人 是Philippe Flajolet 教授
Redis集成的HyperLogLog使用语法主要有pfadd和pfcount,顾名思义,一个是来添加数据,一个是来统计的,使用比较容易掌握,不过算法是比较复杂的,然后为什么用pf?是因为HyperLogLog 这个数据结构的发明人 是Philippe Flajolet教授 ,所以用发明人的英文缩写,这样我们也容易记住这个语法了
下面给出一些简单例子,启动redis客户端
127.0.0.1:6379> flushall
OK
127.0.0.1:6379> pfadd uv user1
(integer) 1
127.0.0.1:6379> pfcount uv
(integer) 1
127.0.0.1:6379> pfadd uv user2
(integer) 1
127.0.0.1:6379> pfcount uv
(integer) 2
127.0.0.1:6379> pfadd uv user3
(integer) 1
127.0.0.1:6379> pfcount uv
(integer) 3
127.0.0.1:6379> pfadd uv user4
(integer) 1
127.0.0.1:6379> pfcount uv
(integer) 4
127.0.0.1:6379> pfadd uv user5 user6 user 7 user8 user9 user10
(integer) 1
127.0.0.1:6379> pfcount uv
(integer) 10
127.0.0.1:6379>
然后用java的Jedis库来实现
加上Maven:
<dependencies>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
</dependencies>
写个测试类,要先启动redis服务端
package com.test.redis;
import redis.clients.jedis.Jedis;
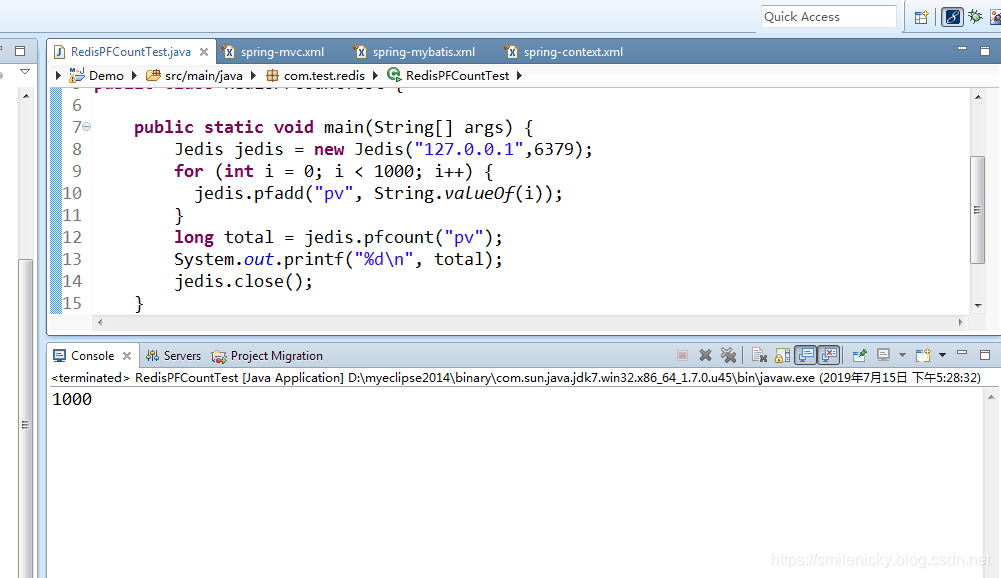
public class RedisPFCountTest {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1",6379);
for (int i = 0; i < 1000; i++) {
jedis.pfadd("pv", String.valueOf(i));
}
long total = jedis.pfcount("pv");
System.out.printf("%d\n", total);
jedis.close();
}
}
再加大数据量,这里写了10万次的统计,可以看出是有一点误差的
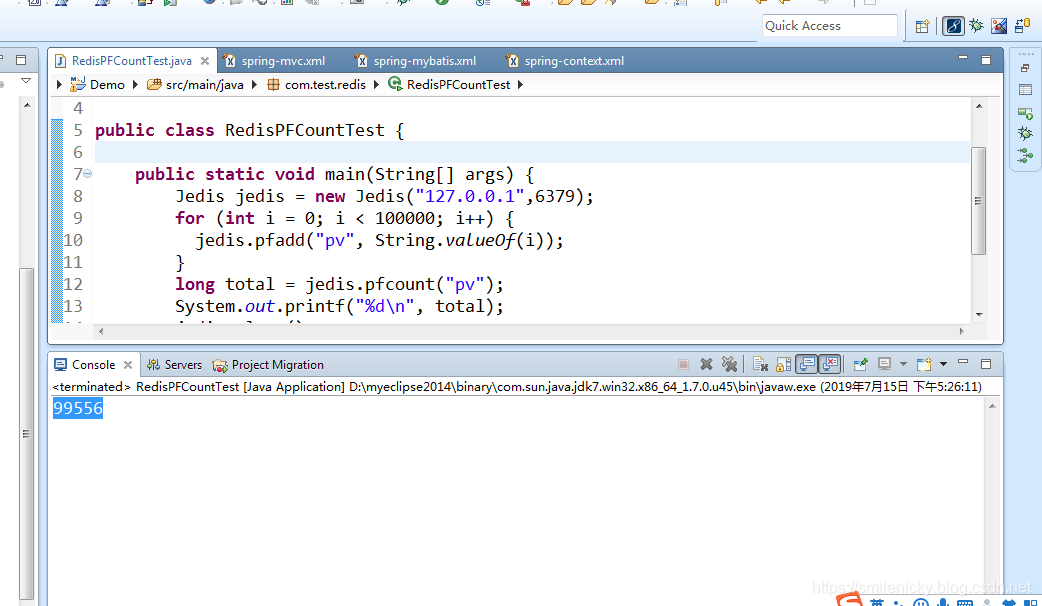
当然HyperLogLog算法一开始就是为了大数据量的统计而发明的,所以很适合那种数据量很大,然后又没要求不能有一点误差的计算,HyperLogLog 提供不精确的去重计数方案,虽然不精确但是也不是非常不精确,标准误差是 0.81%,不过这对于页面用户访问量是没影响的,因为这种统计可能是访问量非常巨大,但是又没必要做到绝对准确,访问量对准确率要求没那么高,但是性能存储方面要求就比较高了,而HyperLogLog正好符合这种要求,不会占用太多存储空间,同时性能不错
(2) PFMERGE 用法
pfadd和pfcount常用于统计,然后来个需求,假如两个页面很相近,现在想统计这两个页面的用户访问量呢?这里就可以用pfmerge合并统计了,语法如例子:
127.0.0.1:6379> PFADD test1 "apple" "banana" "cherry"
(integer) 1
127.0.0.1:6379> PFCOUNT test1
(integer) 3
127.0.0.1:6379> PFADD test2 "apple" "cherry" "durian" "mongo"
(integer) 1
127.0.0.1:6379> PFCOUNT test2
(integer) 4
127.0.0.1:6379> PFMERGE test1&test2 test1 test2
OK
127.0.0.1:6379> PFCOUNT test1&test2
(integer) 5
Redis HyperLogLog用法简介的更多相关文章
- IOS NSInvocation用法简介
IOS NSInvocation用法简介 2012-10-25 19:59 来源:博客园 作者:csj007523 字号:T|T [摘要]在 iOS中可以直接调用某个对象的消息方式有两种,其中一种就是 ...
- JodaTime用法简介
JodaTime用法简介 Java的Date和Calendar用起来简直就是灾难,跟C#的DateTime差距太明显了,幸好有JodaTime 本文简单罗列JodaTime的用法 package co ...
- Redis HyperLogLog
Redis 在 2.8.9 版本添加了 HyperLogLog 结构. Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非 ...
- redis基本用法
java连接redis基本用法 package Redis; import java.util.HashMap; import java.util.List; import java.uti ...
- Apache自带压力测试工具ab用法简介
ab命令原理 ab命令会创建很多的并发访问线程,模拟多个访问者同时对某一URL进行访问.它的测试目标是基于URL的,因此,既可以用来测试Apache的负载压力,也可以测试nginx.lighthttp ...
- Redis和nosql简介,api调用;Redis数据功能(String类型的数据处理);List数据结构(及Java调用处理);Hash数据结构;Set数据结构功能;sortedSet(有序集合)数
1.Redis和nosql简介,api调用 14.1/ nosql介绍 NoSQL:一类新出现的数据库(not only sql),它的特点: 1. 不支持SQL语法 2. 存储结构跟传统关系型数 ...
- 【redis 基础学习】(六)Redis HyperLogLog
摘自:http://www.mayou18.com/detail/o6M0v9mi.html Redis HyperLogLog 结构讲解 Redis 在 2.8.9 版本添加了 HyperLogL ...
- Postman用法简介
转自:http://blog.csdn.net/flowerspring/article/details/52774399 Postman用法简介 转载 2016年10月10日 09:04:10 10 ...
- MSSQL Sql加密函数 hashbytes 用法简介
转自:http://www.maomao365.com/?p=4732 一.mssql sql hashbytes 函数简介 hashbytes函数功能为:返回一个字符,通过 MD2.MD4.MD5. ...
随机推荐
- LINQ查询表达式---------from子句
LINQ查询表达式---------from子句 LINQ的查询由3基本部分组成:获取数据源,创建查询,执行查询. //1.获取数据源 List<, , , , , }; //创建查询 var ...
- Asp +Js 无刷新分页
Default.aspx代码 <%@ Page Language="C#" AutoEventWireup="true" CodeBehind=" ...
- HTTP 错误 403.14 - Forbidden Web 服务器被配置为不列出此目录的内容。
解决方法: 找到目录浏览,打开,点击右边的启用就OK了.
- jQuery简明教程
本文参考w3cshool中文教程,网址:http://www.w3school.com.cn/jquery/index.asp 简介 jQuery是一个Javascript库,使用其的主要目的是简化J ...
- delphi xe5 中TMemo控件的应用——for android
TMemo中的两个方法: TMemo.Lines.Add(stringxxx);意思是向TMemo中增加字符串stringxxx: TMemo.Lines.Text :=stringxxx,意思是清空 ...
- delphi中move函数的正确理解(const和var一样,都是传地址,所以Move是传地址,而恰恰不是传值)太精彩了 good
我们能看到以下代码var pSource,pDest:PChar; len: integer;.......................//一些代码Move(pSource,pDest,l ...
- 为什么你有10年经验,但成不了专家?(重复性刻意训练+反馈修正,练习的精髓是要持续地做自己做不好的,太精彩了)真正的高手都有很强的自学能力,老师和教练的最重要作用是提供即时的反馈(莫非我从小到大学习不好的原因在这里?没有单独刻意训练?) good
也许简单看书就是没有刻意训练.更没有反馈,所以没有效果 我倒是想起自己,研究VCL源码的时候,都是自己给自己提问,然后苦思冥想.自己解决问题,然后Windows编程水平果然上了一个台阶.对什么叫做“框 ...
- 将后台窗口激活到前台的方法(使用AttachThreadInput和SetForegroundWindow两个API)
下面这种方法是我见到的最理想的,还有一些其他的方法,像通过SetWindowsPos这个API设置窗口的Z-oder到最顶层,再设置回去.还有通过把当前窗口设置到底层,然后激活目标窗口等等方法. HW ...
- 模态对话框测试 MFC中的模态对话框与非模态对话框
http://blog.csdn.net/u010839382/article/details/52972427 http://blog.csdn.net/u010839382/article/det ...
- redission-tomcat:快速实现从单机部署到多机部署
原文地址: http://blog.jboost.cn/2019/06/29/session-redis.html 一些项目初期出于简单快速,都是做单机开发与部署,但是随着业务的扩展或对可用性要求的提 ...