spark 源码分析之二十二-- Task的内存管理
问题的提出
本篇文章将回答如下问题:
1. spark任务在执行的时候,其内存是如何管理的?
2. 堆内内存的寻址是如何设计的?是如何避免由于JVM的GC的存在引起的内存地址变化的?其内部的内存缓存池回收机制是如何设计的?
3. 堆外和堆内内存分别是通过什么来分配的?其数据的偏移量是如何计算的?
4. 消费者MemoryConsumer是什么?
5. 数据在内存页中是如何寻址的?
单个任务的内存管理是由 org.apache.spark.memory.TaskMemoryManager 来管理的。
TaskMemoryManager
它主要是负责管理单个任务的内存。
首先内存分为堆外内存和堆内内存。
对于堆外内存,可以内存地址直接使用64位长整型地址寻址。
对于堆内内存,内存地址由一个base对象和一个offset对象组合起来表示。
类在设计的过程中遇到的问题:
对于其他结构内部的结构的地址的保存是存在问题的,比如在hashmap或者是 sorting buffer 中的记录的指针,尽管我们决定使用128位来寻址,我们不能只存base对象的地址,因为由于gc的存在,这个地址不能保证是稳定不变的。(由于分代回收机制的存在,内存中的对象会不断移动,每次移动,对象内存地址都会改变,但这对于不关注对象地址的开发者来说,是透明的)
最终的方案:
对于堆外内存,只保存其原始地址,因为堆外内存不受gc影响;对于堆内内存,我们使用64位的高13位来保存内存页数,低51位来保存这个页中的offset,使用page表来保存base对象,其在page表中的索引就是该内存的内存页数。页数最多有8192页,理论上允许索引 8192 * (2^31 -1)* 8 bytes,相当于140TB的数据。其中 2^31 -1 是整数的最大值,因为page表中记录索引的是一个long型数组,这个数组的最大长度是2^31 -1。实际上没有那么大。因为64位中除了用来设计页数和页内偏移量外还用于存放数据的分区信息。
MemoryLocation
其中这个base对象和offset对象被封装进了 MemoryLocation对象中,也就是说,这个类就是用来内存寻址的,如下:
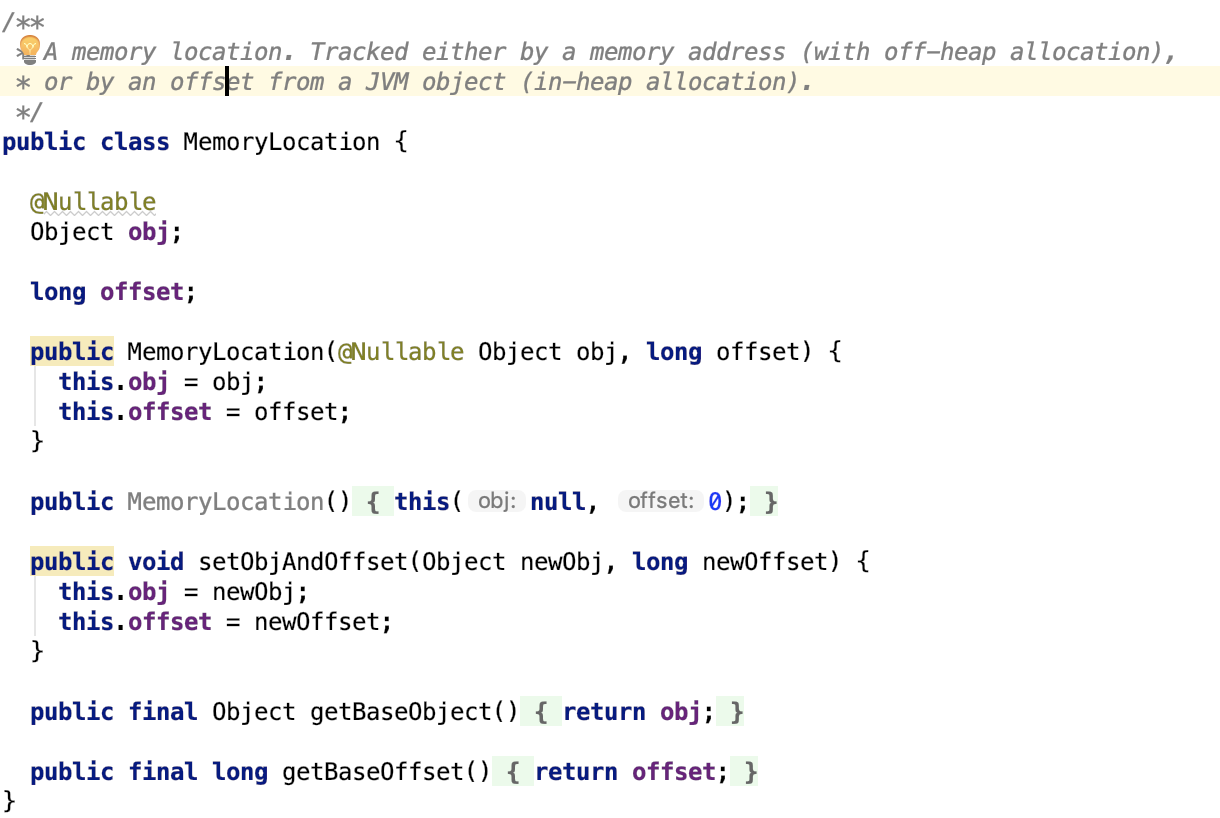
其唯一实现类为 org.apache.spark.unsafe.memory.MemoryBlock。
MemoryBlock
它表示一段连续的内存块,包括一个起始位置和一个固定大小。起始位置有MemoryLocation来表示。
也就是说它有四个属性:
这段连续内存块的起始地址:从父类继承而来的base对象和offset。
固定大小 length以及对这个内存块的唯一标识 - 内存页码(page number)
主要方法如下,其中Platform是跟操作系统有关的一个类,不做过多说明。

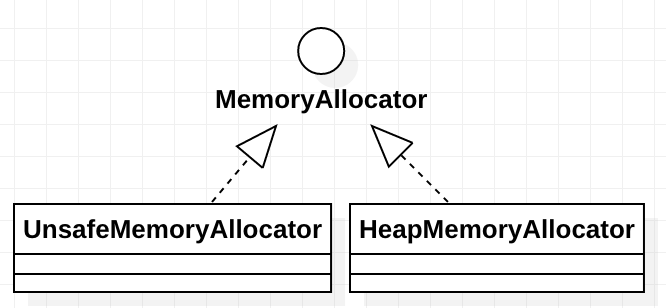
MemoryAllocator
其主要负责内存的申请工作。这个接口的实现类是真正分配内存的。后面介绍的TaskMemoryManager只是负责管理内存,但是不负责具体的内存分配事宜。
其继承关系如下,有两个子类:
其定义的主要的常量和方法如下:

主要方法主要用来分配和释放内存块。下面主要来看一下它两个子类的实现。
HeapMemoryAllocator
全称:org.apache.spark.unsafe.memory.HeapMemoryAllocator
主要负责分配堆内内存,其主要分配long型数组,最大分配内存为16GB。
成员变量

bufferPoolBySize是一个HashMap,其内部的value里面存放的数据都是弱引用类型的数据,在JVM 发生GC时,数据可能会被回收。它里面存放的数据都是已经不用的废弃掉的内存块。
是否使用内存缓存池

申请的内存块的大小大于阀值才使用内存缓存池。
分配内存

思路:首先根据bytes大小计算处words的大小,然后字节对齐计算出对齐需要的字节,断言对齐后的字节大小大于等于之前未对齐的字节大小。为什么要对齐呢?因为长整型数组的内存大小是对齐的。
如果对齐后的字节大小满足使用缓存池的条件,则先从缓存池中弹出对应的pool,并且如果弹出的pool不为空,则逐一取出之前释放的数组,并将其封装进MmeoryBlock对象,并且使用标志位清空之前的历史数据返回之。
否则,则初始化指定的words长度的长整型数组,并将其封装进MmeoryBlock对象,并且使用标志位清空之前的历史数据返回之。总之缓存的是长整型数组,存放数据的也是长整型数组。
释放内存

首先把要释放的内存数据使用free标志位覆盖,pageNumber置为占位的page number。
然后取出其内部的长整型数组赋值给临时变量,并且把base对象置为null,offset置为0。
取出的长整型数组计算其对齐大小,内存页的大小不一定等于数组的长度 * 8,此时的size是内存页的大小,需要进行对齐操作。
对齐之后的内存页大小如果满足缓存池条件,则将其暂存缓存池,等待下次回收再用或者JVM的GC回收。
这个方法结束之后,这个长整型数组被LinkedList对象(即pool)引用,但这是一个若引用,所以说,现在这个数组是一个游离对象,当JVM回收时,会回收它。
对堆内内存的总结
对于堆内内存上的数据真实受JVM的GC影响,其真实数据的内存地址会发生改变,巧妙使用数组这种容器以及偏移量巧妙地将这个问题规避了,数据回收也可以使用缓存池机制来减少数组频繁初始化带来的开销。其内部使用虚引用来引用释放的数组,也不会导致无法回收导致内存泄漏。
UnsafeMemoryAllocator
全称:org.apache.spark.unsafe.memory.UnsafeMemoryAllocator
负责分配堆外内存。
分配内存

思路:底层使用unsafe这个类来分配堆外内存。这里的offset就是操作系统的内存地址,base对象为null。
释放内存

堆外内存的释放不能使用缓存池,因为堆外内存不受JVM的管理,将会导致遗留的不用的内存无法回收从而引发更严重的内存泄漏,更甚者堆外内存使用的是系统内存,严重的话还会导致出现系统级问题。
堆堆外内存的总结
简言之,对于堆外内存的分配和回收,都是通过java内置的Unsafe类来实现的,其统一规范中的base对象为null,其offset就是该内存页在操作系统中的真实地址。
下面剖析一下TaskMemoryManager的成员变量和核心方法。
进一步剖析TaskMemoryManager
成员变量
下面,先来看一下其成员变量,截图如下:

对主要的成员变量做如下解释:
OFFSET_BITS:是指的page number 占用的bit个数
MAXIMUM_PAGE_SIZE_BYTES:约17GB,每页最大可存内存大小
pageTable:主要用来存放内存页的
allocatedPages:主要用来追踪内存页是否为空的
memoryManager:主要负责Spark内存管理,具体细节可以参照 spark 源码分析之十五 -- Spark内存管理剖析 做进一步了解。
taskAttemptId:任务id
tungstenMemoryMode:tungsten内存模式,是堆外内存还是堆内内存
consumers:记录了任务内存的所有消费者
核心方法
所有方法如下:

下面,我们来逐一对其进行源码剖析。
1. 获取执行内存

思路:首先先去MemoryManager中去申请执行内存,如果内存不够,则获取所有的MemoryConsumer,调用其spill方法将内存数据溢出到磁盘,直到释放内存空间满足申请的内存空间则停止spill操作。
2. 释放执行内存

这其实不是真正意义上的内存释放,只是管账的把这笔内存占用划掉了,真正的内存释放还是需要调用MemoryConsumer的spill方法将内存数据溢出到磁盘来释放内存。
3. 获取内存页大小

4. 分配内存页

思路:首先获取执行内存。执行内存获取成功后,找到一个空的内存页。
如果内存页码大于指定的最大页码,则释放刚申请的内存,返回;否则使用MemoryAllocator分配内存页、初始化内存页码并将其放入page表的管理,最后返回page。关于MemoryAllocator分配内存的细节,请参照上文关于其堆内内存或堆外内存的内存分配的详细剖析。
5. 释放内存页

思路:首先调用EMmoryAllocator的free 方法来释放内存,并且调用 方法2 来划掉内存的占用情况。
6. 内存地址加密
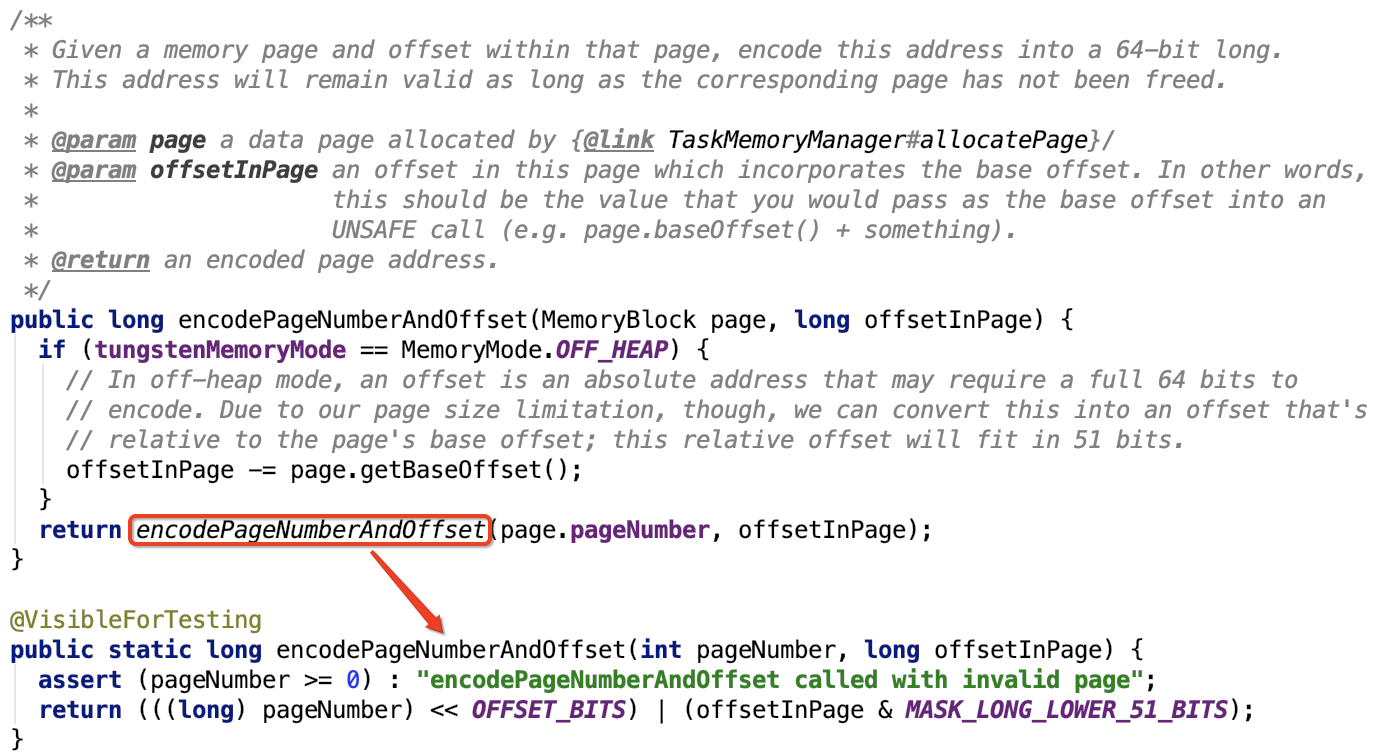
思路:高13位保存的是page number,低51位保存的是地址的offset
7.内存地址解密

思路: 跟 方法6 的编码思路相反
8.根据内存地址获取内存的base对象,前提是必须是堆内内存页,否则没有base对象。
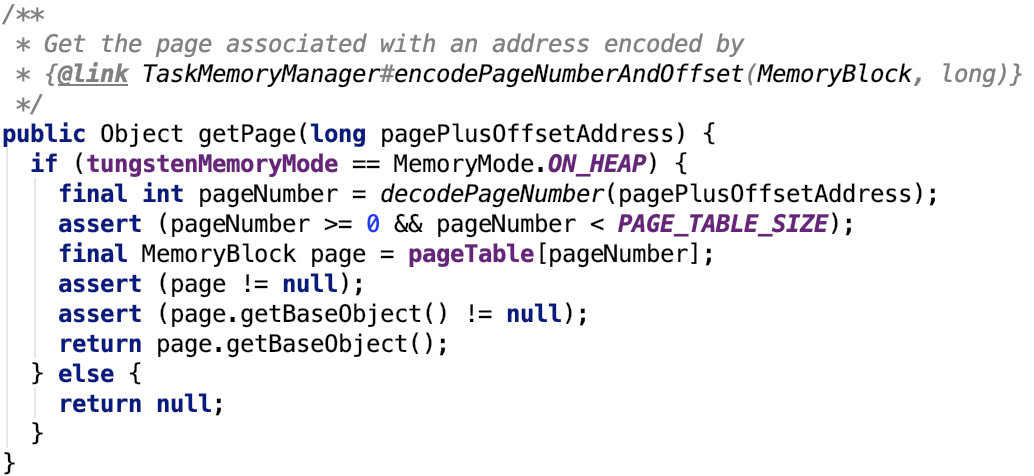
9.获取内存地址在内存页的偏移量offset

如果是堆内内存,则直接返回其解码之后的offset即可。
如果是堆外内存,分配内存时的offset + 页内的偏移量就是真正的偏移量,是针对操作系统的,也是绝对的偏移量。
10.清空所有内存页

思路:使用MemoryAllocator释放内存,并且请求管账的MemoryManager释放执行内存和task的所有内存。
11.获取单个任务的执行内存使用情况

思路:从MemoryManager处获取指定任务的执行内存使用情况。
下面看一下跟TaskMemoryManager交互的消费者对象 -- MemoryConsumer。
MemoryConsumer
类说明
全称:org.apache.spark.memory.MemoryConsumer
它是任务内存的消费者。
其类结构如下:
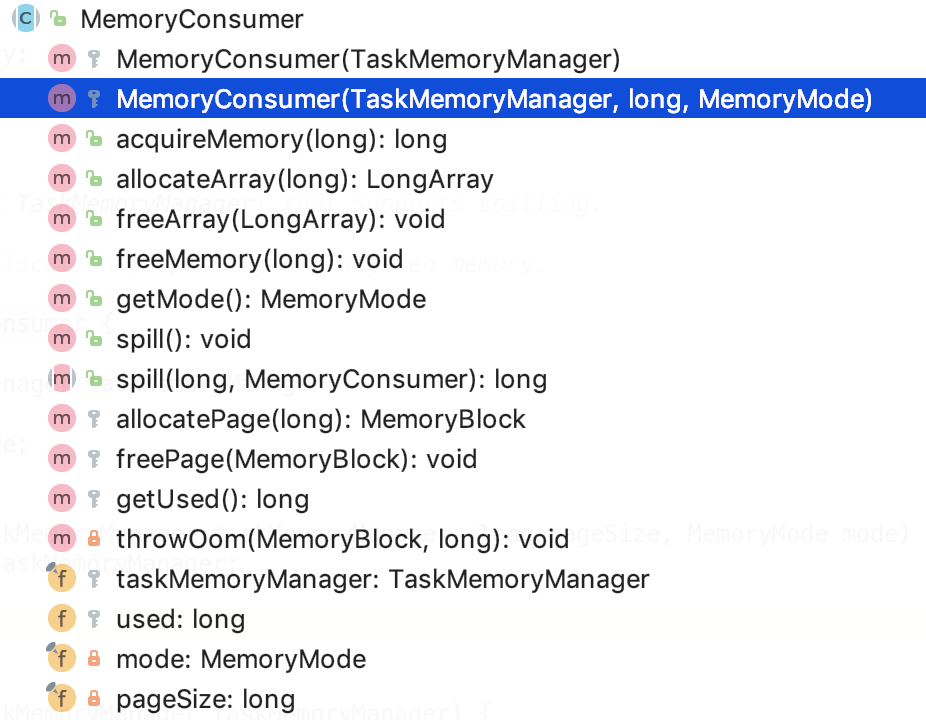
成员变量
taskMemoryManager:是负责任务内存管理。
used:表示使用的内存。
mode:表示内存的模式是堆内内存还是堆外内存。
pageSize:表示页大小。
主要方法
1. 内存数据溢出到磁盘,抽象方法,等待子类实现。

2. 申请释放内存部分,不再做详细的分析,都是依赖于 TaskMemoryManager 做的操作。
关于更多MemoryConsumer的以及其子类的相关内容,将在下一篇文章Shuffle的写操作中详细剖析。
总结
本篇文章主要剖析了Task在任务执行时内存的管理相关的内容,现在可能还看不出其重要性,后面在含有sort的shuffle过程中,会频繁的使用基于内存的sorter,此时的sorter包含大量的数据,是需要内存管理的。
spark 源码分析之二十二-- Task的内存管理的更多相关文章
- 手机自动化测试:appium源码分析之bootstrap十二
手机自动化测试:appium源码分析之bootstrap十二 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣 ...
- jQuery-1.9.1源码分析系列(十二) 筛选操作
在前面分析的时候也分析了部分筛选操作(详见),我们接着分析,把主要的几个分析一下. jQuery.fn.find( selector ) find接受一个参数表达式selector:选择器(字符串). ...
- spark 源码分析之十二 -- Spark内置RPC机制剖析之八Spark RPC总结
在spark 源码分析之五 -- Spark内置RPC机制剖析之一创建NettyRpcEnv中,剖析了NettyRpcEnv的创建过程. Dispatcher.NettyStreamManager.T ...
- spark 源码分析之二十一 -- Task的执行流程
引言 在上两篇文章 spark 源码分析之十九 -- DAG的生成和Stage的划分 和 spark 源码分析之二十 -- Stage的提交 中剖析了Spark的DAG的生成,Stage的划分以及St ...
- Spark源码分析之八:Task运行(二)
在<Spark源码分析之七:Task运行(一)>一文中,我们详细叙述了Task运行的整体流程,最终Task被传输到Executor上,启动一个对应的TaskRunner线程,并且在线程池中 ...
- Spark源码分析之六:Task调度(二)
话说在<Spark源码分析之五:Task调度(一)>一文中,我们对Task调度分析到了DriverEndpoint的makeOffers()方法.这个方法针对接收到的ReviveOffer ...
- Spark源码分析之二:Job的调度模型与运行反馈
在<Spark源码分析之Job提交运行总流程概述>一文中,我们提到了,Job提交与运行的第一阶段Stage划分与提交,可以分为三个阶段: 1.Job的调度模型与运行反馈: 2.Stage划 ...
- spark 源码分析之十八 -- Spark存储体系剖析
本篇文章主要剖析BlockManager相关的类以及总结Spark底层存储体系. 总述 先看 BlockManager相关类之间的关系如下: 我们从NettyRpcEnv 开始,做一下简单说明. Ne ...
- spark 源码分析之十九 -- DAG的生成和Stage的划分
上篇文章 spark 源码分析之十八 -- Spark存储体系剖析 重点剖析了 Spark的存储体系.从本篇文章开始,剖析Spark作业的调度和计算体系. 在说DAG之前,先简单说一下RDD. 对RD ...
随机推荐
- Hadoop 学习之路(三)—— 分布式计算框架 MapReduce
一.MapReduce概述 Hadoop MapReduce是一个分布式计算框架,用于编写批处理应用程序.编写好的程序可以提交到Hadoop集群上用于并行处理大规模的数据集. MapReduce作业通 ...
- Hadoop初步学习
我们老板理解的大数据是,从数据到知识的转化.大数据目前的应用如 支付宝金融大数据.腾讯出行大数据等. 大数据的工作就是从海量数据源中筛选,梳理对自己有用的数据,整合成合适的数据结构,存储并进行可视化. ...
- Linux下多网卡绑定bond及模式介绍
[介绍] 网卡bond一般主要用于网络吞吐量很大,以及对于网络稳定性要求较高的场景. 主要是通过将多个物理网卡绑定到一个逻辑网卡上,实现了本地网卡的冗余,带宽扩容以及负载均衡. Linux下一共有七种 ...
- jenkin+Git子模块自动拉取代码
jenkins+Git子模块自动拉取代码 添加Git子模块 先克隆想要添加子模块的仓库git clone ssh://git@ip:port/user/project.git,这个是主目录. 进入仓库 ...
- git常用总结
git 基本配置 安装git yum -y install git git全局配置 git config --global user.name "lsc" #配置git使用用户 g ...
- 使用SQL行转列函数pivot遇到的问题
背景:对投票的结果按照单位进行汇总统计,数据库中表记录的各个账号对各个选项的投票记录.马上想到一个解决方案,先根据单位和选项进行Group By,然后再行转列得出单位对各个选项的投票情况. with ...
- [apue] popen/pclose 疑点解惑
问题请看这里: [apue] 使用 popen/pclose 的一点疑问 当时怀疑是pclose关闭了使用完成的管道,因此在pclose之前加一个足够长的sleep,再次观察进程文件列表: 哈哈,这下 ...
- spark 源码分析之十二 -- Spark内置RPC机制剖析之八Spark RPC总结
在spark 源码分析之五 -- Spark内置RPC机制剖析之一创建NettyRpcEnv中,剖析了NettyRpcEnv的创建过程. Dispatcher.NettyStreamManager.T ...
- web前端css(一)
一 css的引入方式: 1) 行内样式: <p style=”color: green”>我是一个段落</p> 2) 内接样式: <style ty ...
- c++汉诺塔问题
c++解决汉诺塔问题 题目描述 约19世纪末,在欧州的商店中出售一种智力玩具,在一块铜板上有三根杆,最左边的杆上自上而下.由小到大顺序串着由64个圆盘构成的塔.目的是将最左边杆上的盘全部移到中间的杆上 ...