scrapy实战4 GET方法抓取ajax动态页面(以糗事百科APP为例子):
一般来说爬虫类框架抓取Ajax动态页面都是通过一些第三方的webkit库去手动执行html页面中的js代码, 最后将生产的html代码交给spider分析。本篇文章则是通过利用fiddler抓包获取json数据分析Ajax页面的具体请求内容,找到获取数据的接口url,直接调用该接口获取数据,省去了引入python-webkit库的麻烦,而且由于一般ajax请求的数据都是结构化数据,这样更省去了我们利用xpath解析html的痛苦。
手机打开糗事百科APP ,利用fiddler抓包获取json数据 检查 得到的接口url是否能正常访问 如果能访问在换个浏览器试试 如图
打开之后的json数据如图推荐用json—handle插件(chrome安装)打开
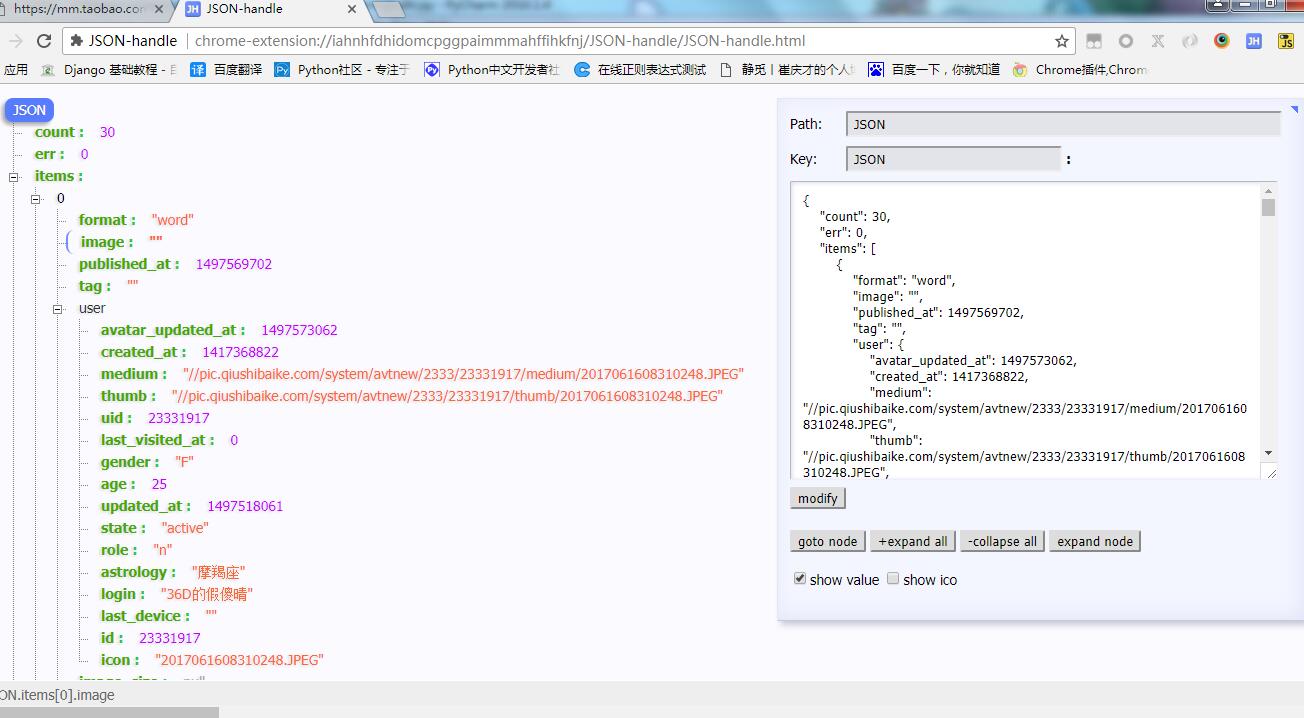
代码实现:以99页为例
items.py
import scrapy class QiushibalkeItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
uid=scrapy.Field()
nickname = scrapy.Field()
gender=scrapy.Field() astrology=scrapy.Field() content=scrapy.Field()
crawl_time=scrapy.Field()
spiders/qiushi.py
# -*- coding: utf-8 -*-
import scrapy
import json
from qiushibalke.items import QiushibalkeItem
from datetime import datetime
class QiushiSpider(scrapy.Spider):
name = "qiushi"
allowed_domains = ["m2.qiushibaike.com"]
def start_requests(self):
for i in range(1,100):
url = "https://m2.qiushibaike.com/article/list/text?page={}".format(i)
yield scrapy.Request(url,callback=self.parse_item) def parse_item(self, response):
datas = json.loads(response.text)["items"]
print(datas)
for data in datas:
# print(data['votes']['up'])
# print(data['user']['uid'])
# print(data['user']["login"])
# print(data['user']["gender"])
# print(data['user']["astrology"]) item = QiushibalkeItem()
item["uid"]= data['user']["uid"] item["nickname"] = data['user']["login"]
item["gender"] = data['user']["gender"] item["astrology"] = data['user']["astrology"]
item["content"]=data["content"]
item["crawl_time"] = datetime.now() yield item
pipelines.py
import pymysql
class QiushibalkePipeline(object):
def process_item(self, item, spider):
con = pymysql.connect(host="127.0.0.1", user="youusername", passwd="youpassword", db="qiushi", charset="utf8")
cur = con.cursor()
sql = ("insert into baike(uid,nickname,gender,astrology,content,crawl_time)"
"VALUES(%s,%s,%s,%s,%s,%s)")
lis = (item["uid"],item["nickname"],item["gender"],item["astrology"],item["content"],item["crawl_time"])
cur.execute(sql, lis)
con.commit()
cur.close()
con.close() return item
settings.py
BOT_NAME = 'qiushibalke' SPIDER_MODULES = ['qiushibalke.spiders']
NEWSPIDER_MODULE = 'qiushibalke.spiders'
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 5
COOKIES_ENABLED = False
DEFAULT_REQUEST_HEADERS = {
"User-Agent":"qiushibalke_10.13.0_WIFI_auto_7",
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
}
ITEM_PIPELINES = {
'qiushibalke.pipelines.QiushibalkePipeline': 300,
# 'scrapy_redis.pipelines.RedisPipeline':300,
}
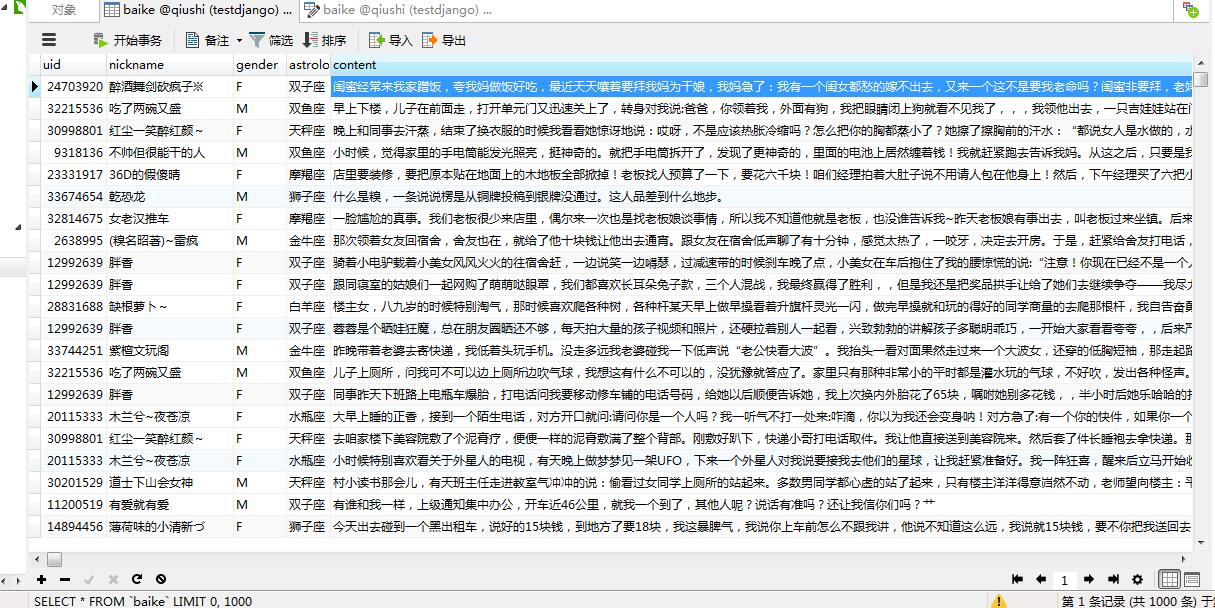
数据如图:
scrapy实战4 GET方法抓取ajax动态页面(以糗事百科APP为例子):的更多相关文章
- scrapy实战5 POST方法抓取ajax动态页面(以慕课网APP为例子):
在手机端打开慕课网,fiddler查看如图注意圈起来的位置 经过分析只有画线的page在变化 上代码: items.py import scrapy class ImoocItem(scrapy.It ...
- C#利用phantomJS抓取AjAX动态页面
在C#中,一般常用的请求方式,就是利用HttpWebRequest创建请求,返回报文.但是有时候遇到到动态加载的页面,却只能抓取部分内容,无法抓取到动态加载的内容. 如果遇到这种的话,推荐使用phan ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- Python爬虫实战之爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- Python爬虫实战之爬取糗事百科段子【华为云技术分享】
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- 芝麻HTTP:Python爬虫实战之爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- Scrapy爬虫框架教程(四)-- 抓取AJAX异步加载网页
欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章 sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
随机推荐
- Nginx 设置cors跨域
在我们的开发中,经常遇到跨域,这个时候,可以通过cors来解决. 解决的方法可以在服务端的代码层或者在web服务器进行设置 在web服务器上进行设置cors 跨域,这样就不必改动代码.以nginx为例 ...
- linux C 内存管理方式之半动态
看到半动态申请内存,第一反应这是什么鬼? 实际上半动态内存申请很容易理解,在GNU C中使用alloca函数来实现 #include <stdlib.h> void *alloca (si ...
- iOS9 Spotlight使用
1.Spotloight是什么? Spotlight在iOS9上做了一些新的改进, 也就是开放了一些新的API, 通过Core Spotlight Framework你可以在你的app中集成Spotl ...
- UWP开发学习笔记2
RelativePanel控件: 用法 描述 RelativePanel.Above 设置当前element为目标element的上方 RelativePanel.AlignBottomWith 设置 ...
- 微信小程序把玩(三十七)location API
原文:微信小程序把玩(三十七)location API location API也就分这里分两种wx.getLocation(object)获取当前位置和wx.openLocation(object) ...
- fatal error LNK1169:找到一个或多个重定义的符号
这个算是个比较基础的问题,由于我不是C程序员,本行java,临时拉来做的,所以有些坑还得自己走出来. 这个问题是由于,全局变量在a.h中定义,在两个源文件a.cpp和b.cpp中引用,之后被编译器认为 ...
- Microsoft.Ace.OleDb.12.0 操作excel
在用c#操作excel的时候,碰到了一下的问题: 1.Microsoft.Ace.OleDb.12.0未安装,可以到下载2007 Office system 驱动程序AccessDatabaseEng ...
- 修改zookeeper jvm参数
在zkServer.sh中,增加以下参数: start) echo -n "Starting zookeeper ... " if [ -f $ZOOPIDFILE ...
- Flask学习之旅--数据库
一.写在前面 在Web开发中,数据库操作是很重要的一部分,因为网站的很多重要信息都保存在数据库之中.而Flask在默认情况下是没有数据库.表单验证等功能的,但是可以用Flask-extension为W ...
- C#中await/async闲说
自从C#5.0增加异步编程之后,异步编程越来越简单,async和await用的地方越来越多,越来越好用,只要用异步的地方都是一连串的异步,如果想要异步编程的时候,需要从底层开始编写,这样后边使用的时候 ...