scrapy实战4 GET方法抓取ajax动态页面(以糗事百科APP为例子):
一般来说爬虫类框架抓取Ajax动态页面都是通过一些第三方的webkit库去手动执行html页面中的js代码, 最后将生产的html代码交给spider分析。本篇文章则是通过利用fiddler抓包获取json数据分析Ajax页面的具体请求内容,找到获取数据的接口url,直接调用该接口获取数据,省去了引入python-webkit库的麻烦,而且由于一般ajax请求的数据都是结构化数据,这样更省去了我们利用xpath解析html的痛苦。
手机打开糗事百科APP ,利用fiddler抓包获取json数据 检查 得到的接口url是否能正常访问 如果能访问在换个浏览器试试 如图
打开之后的json数据如图推荐用json—handle插件(chrome安装)打开
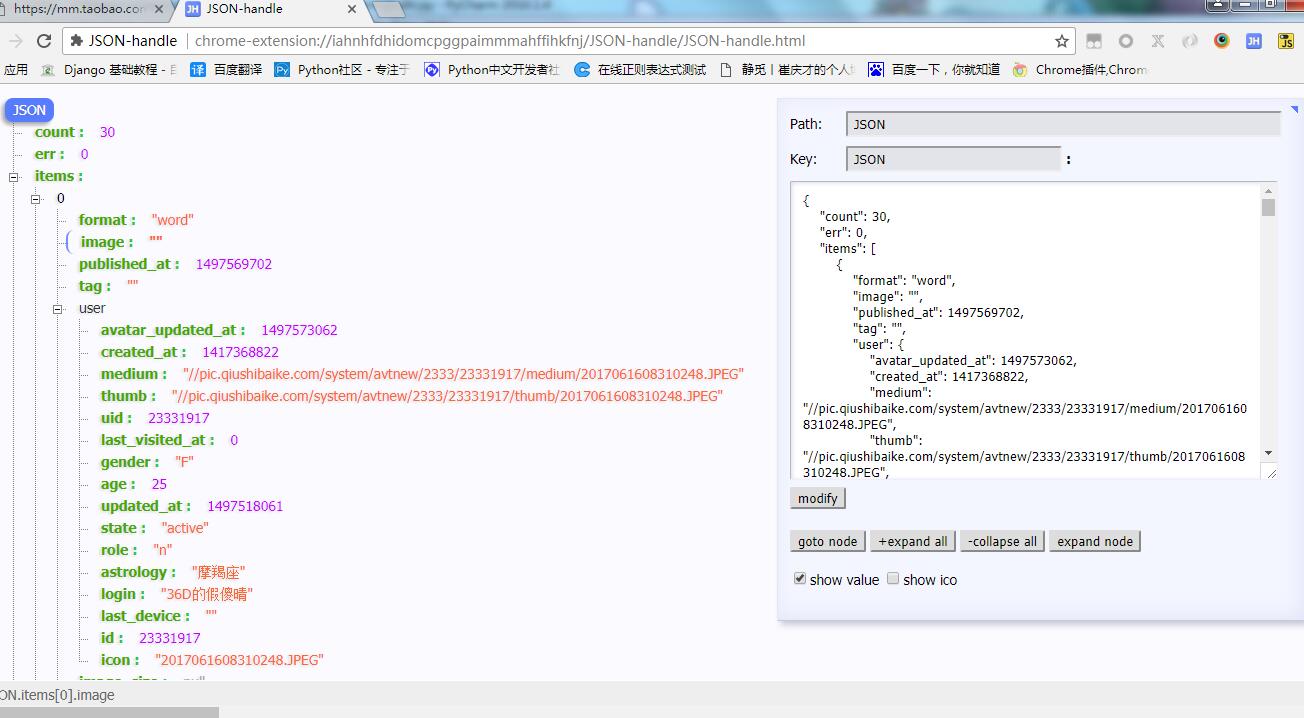
代码实现:以99页为例
items.py
import scrapy class QiushibalkeItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
uid=scrapy.Field()
nickname = scrapy.Field()
gender=scrapy.Field() astrology=scrapy.Field() content=scrapy.Field()
crawl_time=scrapy.Field()
spiders/qiushi.py
# -*- coding: utf-8 -*-
import scrapy
import json
from qiushibalke.items import QiushibalkeItem
from datetime import datetime
class QiushiSpider(scrapy.Spider):
name = "qiushi"
allowed_domains = ["m2.qiushibaike.com"]
def start_requests(self):
for i in range(1,100):
url = "https://m2.qiushibaike.com/article/list/text?page={}".format(i)
yield scrapy.Request(url,callback=self.parse_item) def parse_item(self, response):
datas = json.loads(response.text)["items"]
print(datas)
for data in datas:
# print(data['votes']['up'])
# print(data['user']['uid'])
# print(data['user']["login"])
# print(data['user']["gender"])
# print(data['user']["astrology"]) item = QiushibalkeItem()
item["uid"]= data['user']["uid"] item["nickname"] = data['user']["login"]
item["gender"] = data['user']["gender"] item["astrology"] = data['user']["astrology"]
item["content"]=data["content"]
item["crawl_time"] = datetime.now() yield item
pipelines.py
import pymysql
class QiushibalkePipeline(object):
def process_item(self, item, spider):
con = pymysql.connect(host="127.0.0.1", user="youusername", passwd="youpassword", db="qiushi", charset="utf8")
cur = con.cursor()
sql = ("insert into baike(uid,nickname,gender,astrology,content,crawl_time)"
"VALUES(%s,%s,%s,%s,%s,%s)")
lis = (item["uid"],item["nickname"],item["gender"],item["astrology"],item["content"],item["crawl_time"])
cur.execute(sql, lis)
con.commit()
cur.close()
con.close() return item
settings.py
BOT_NAME = 'qiushibalke' SPIDER_MODULES = ['qiushibalke.spiders']
NEWSPIDER_MODULE = 'qiushibalke.spiders'
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 5
COOKIES_ENABLED = False
DEFAULT_REQUEST_HEADERS = {
"User-Agent":"qiushibalke_10.13.0_WIFI_auto_7",
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
}
ITEM_PIPELINES = {
'qiushibalke.pipelines.QiushibalkePipeline': 300,
# 'scrapy_redis.pipelines.RedisPipeline':300,
}
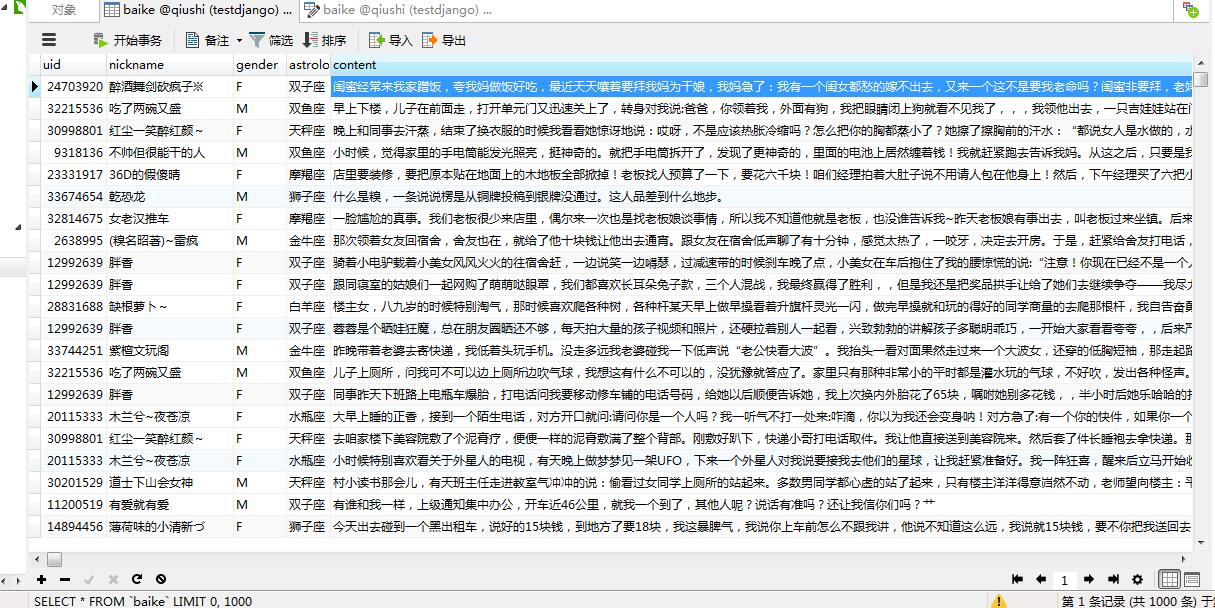
数据如图:
scrapy实战4 GET方法抓取ajax动态页面(以糗事百科APP为例子):的更多相关文章
- scrapy实战5 POST方法抓取ajax动态页面(以慕课网APP为例子):
在手机端打开慕课网,fiddler查看如图注意圈起来的位置 经过分析只有画线的page在变化 上代码: items.py import scrapy class ImoocItem(scrapy.It ...
- C#利用phantomJS抓取AjAX动态页面
在C#中,一般常用的请求方式,就是利用HttpWebRequest创建请求,返回报文.但是有时候遇到到动态加载的页面,却只能抓取部分内容,无法抓取到动态加载的内容. 如果遇到这种的话,推荐使用phan ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- Python爬虫实战之爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- Python爬虫实战之爬取糗事百科段子【华为云技术分享】
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- 芝麻HTTP:Python爬虫实战之爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- Scrapy爬虫框架教程(四)-- 抓取AJAX异步加载网页
欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章 sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
随机推荐
- docker include not found: networks
启动clickhouse的docker镜像时,出现了以下错误 include not found: networks google之后发现是因为可能不支持ipv6导致的解决方法 就是通过设置 /etc ...
- DB First .edmx
DB First查看Entity相互关系.edmx 图表 .edmx源代码——xml文件右键,打开方式 xml内容 详细查看DB:.edmx—Model Browser(模型浏 ...
- MVC 创建强类型视图
•在ViewModel中创建一个类型 •在Action中为ViewData.Model赋值 •在View中使用"@model类型"设置 14 手动创建强类型视图 •在ViewMod ...
- AY写给国人的教程- VS2017 Live Unit Testing[1/2]-C#人爱学不学-aaronyang技术分享
原文:AY写给国人的教程- VS2017 Live Unit Testing[1/2]-C#人爱学不学-aaronyang技术分享 谢谢大家观看-AY的 VS2017推广系列 Live Unit Te ...
- Java FTP 基本操作
最近工作中用到了 FTP 相关的操作,所以借此机会了解了下具体内容. FTP基础 关于 FTP 基础推荐阅读<使用 Socket 通信实现 FTP 客户端程序>,其中需要特别注意的是主动模 ...
- Socket 专题
Socket小白篇-附加TCP/UDP简介 Socket 网络通信的要素 TCP和UDP Socket的通信流程图 1.Socket 什么是Socket Socket:又称作是套接字,网络上的两个程序 ...
- js 跨域访问 获取验证码图片 获取header 自定义属性
1.net core web api 后端 /// <summary> /// 图形验证码 /// </summary> [HttpGet] public IActionRes ...
- 【C++】小心使用文件读写模式:回车('\r') 换行('\n')问题的一次纠结经历
原来没有仔细注意C++读写文件的二进制模式和文本模式,这次吃了大亏.(平台:windows VS2012) BUG出现: 写了一个程序A,生成一个文本文件F保存在本地,然后用程序B读取此文件计算MD ...
- C#破解access数据库密码方法
原文:C#破解access数据库密码方法 using System; using System.Collections.Generic; using System.IO; using System.L ...
- Android零基础入门第79节:Intent 属性详解(上)
Android应用将会根据Intent来启动指定组件,至于到底启动哪个组件,则取决于Intent的各属性.本期将详细介绍Intent的各属性值,以及 Android如何根据不同属性值来启动相应的组件. ...