HBase二级索引的设计(案例讲解)
摘要
最近做的一个项目涉及到了多条件的组合查询,数据存储用的是HBase,恰恰HBase对于这种场景的查询特别不给力,一般HBase的查询都是通过RowKey(要把多条件组合查询的字段都拼接在RowKey中显然不太可能),或者全表扫描再结合过滤器筛选出目标数据(太低效),所以通过设计HBase的二级索引来解决这个问题
查询需求
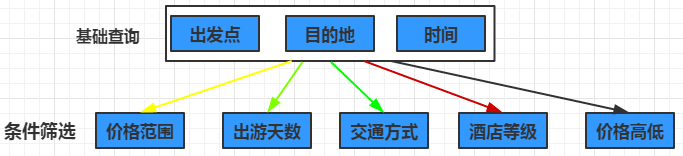
多个查询条件构成多维度的组合查询,需要根据不同组合查询出符合查询条件的数据
HBase的局限性
HBase本身只提供基于行键和全表扫描的查询,而行键索引单一,对于多维度的查询困难(如:对于价格+天数+酒店+交通的多条件组合查询困难),全表扫描效率低下。
二级索引的设计
设计思路
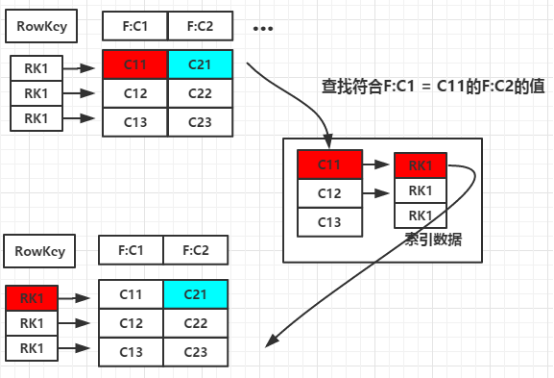
(图1)设计思路
二级索引的本质就是建立各列值与行键之间的映射关系
如(图1),当要对F:C1这列建立索引时,只需要建立F:C1各列值到其对应行键的映射关系,如C11->RK1等,这样就完成了对F:C1列值的二级索引的构建,当要查询符合F:C1=C11对应的F:C2的列值时(即根据C1=C11来查询C2的值,图1青色部分)其查询步骤如下: 1. 根据C1=C11到索引数据中查找其对应的RK,查询得到其对应的RK=RK1 2. 得到RK1后就自然能根据RK1来查询C2的值了 这是构建二级索引大概思路,其他组合查询的联合索引的建立也类似。
逻辑视图
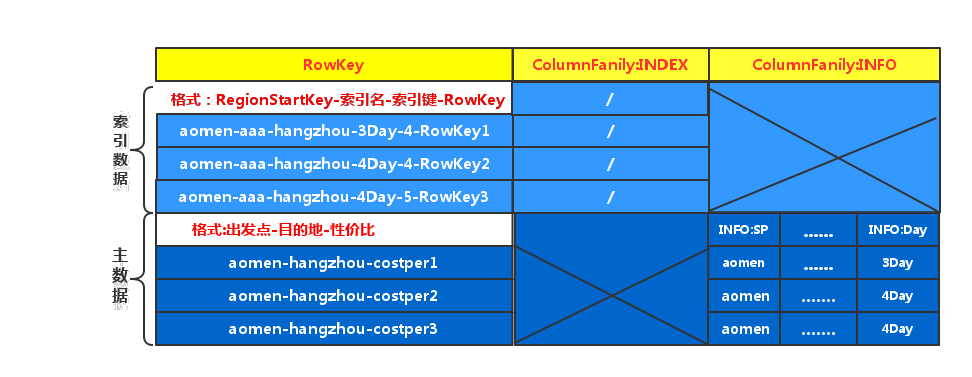
(图2) 部分数据在HBase中存储的逻辑视图
表中有两个列族,其中一个是列族INDEX,其并不存储任何的数据,仅仅是为了将索引数据与主数据分开存储(因为在HBase中同一列族的数据会被压缩在一起存储),索引数据的行键格式为:RegionStartKey-索引名-索引键-Rowkwy,其他RegionStartKey就是出发点,因为在创建HBase表时就对表根据出发点进行了预分区,索引键为主数据中某列(可能是多列)的列值,Rowkey对应主数据的行键;主数据的行键格式为:出发点-目的地-性价比,所以在存储数据时,同一出发点 目的地的数据默认是按性价比排序的;索引数据的行键和主数据的行键的前缀都是出发点,所以在存储时相同出发点的索引数据和主数据是存储在同一个Region中的,这样避免了在通过索引得到RK后又去其他Region上查询目标数据,提高了查询效率。
数据的查询过程
假设查询的条件:
出发点:澳门
目的地:杭州
出游天数:3天
酒店等级:4
其查询步骤如下:
首先根据查询条件来确定索引名,根据其查询条件为出游天数据 酒店等级确定索引名为aaa,这样就将查询的范围缩小在索引名为aaa的索引数据区内
根据出游天数的值为3天,酒店等级的值为4,结合Phoenix的模糊查询就能确定符合这两个查询条件的索引数据的行键
得到索引数据行键后就截取其最后的RowKey
最关键的Rowkey得到后就能轻易的获得其对应的列值了,整个查询过程就结束了。
对于其他更为复杂的组合查询的二级索引设计如类似。
缺点
需要额外的存储空间,属 一种以空间换时间的方式。
注意
1.将查询条件中的可选字段转换成数字能节省存储空间,如交通工具中的飞机,高铁,火车,轮船,汽车分别转换成5,4,3,2,1
2.将汉字转换成拼音才能保证数据按HBase的排序规则排序
3.如果数据量在百万级别以下可使用Phoenix(HBase的SQL查询引擎)模糊查询功能减少索引行键的设计
参考资料
HBase二级索引的设计(案例讲解)的更多相关文章
- HBase之八--(1):HBase二级索引的设计(案例讲解)
摘要 最近做的一个项目涉及到了多条件的组合查询,数据存储用的是HBase,恰恰HBase对于这种场景的查询特别不给力,一般HBase的查询都是通过RowKey(要把多条件组合查询的字段都拼接在RowK ...
- HBase二级索引的设计
摘要 最近做的一个项目涉及到了多条件的组合查询,数据存储用的是HBase,恰恰HBase对于这种场景的查询特别不给力,一般HBase的查询都是通过RowKey(要把多条件组合查询的字段都拼接在RowK ...
- HBase学习(四) 二级索引 rowkey设计
HBase学习(四) 一.HBase的读写流程 画出架构 1.1 HBase读流程 Hbase读取数据的流程:1)是由客户端发起读取数据的请求,首先会与zookeeper建立连接2)从zookeepe ...
- HBase二级索引方案总结
转自:http://blog.sina.com.cn/s/blog_4a1f59bf01018apd.html 附hbase如何创建二级索引以及创建二级索引实例:http://www.aboutyun ...
- HBase二级索引、读写流程
HBase二级索引.读写流程 一.HBse二级索引方案 1.1 基于Coprocessor方案 1.2 Phoenix二级索引特点 1.3 Phoenix 二级索引方案 二.HBase读写流程 2.1 ...
- hbase 二级索引创建
在单机上运行hbase 二级索引: import java.io.IOException; import java.util.HashMap; import java.util.Map; import ...
- HBase 二级索引与Join
二级索引与索引Join是Online业务系统要求存储引擎提供的基本特性.RDBMS支持得比较好,NOSQL阵营也在摸索着符合自身特点的最佳解决方案. 这篇文章会以HBase做为对象来探讨如何基于Hba ...
- HBase二级索引与Join
转自:http://www.oschina.net/question/12_32573 二级索引与索引Join是Online业务系统要求存储引擎提供的基本特性.RDBMS支持得比较好,NOSQL阵营也 ...
- HBase之八--(2):HBase二级索引之Phoenix
1. 介绍 Phoenix 是 Salesforce.com 开源的一个 Java 中间件,可以让开发者在Apache HBase 上执行 SQL 查询.Phoenix完全使用Java编写,代码位于 ...
随机推荐
- 再探java基础——对面向对象的理解(1)
对象 对象是人们要进行研究的任何事物,从最简单的整数到复杂的飞机等均可看作对象,它不仅能表示具体的事物,还能表示抽象的规则.计划或事件.对象具有属性和行为,在程序设计中对象实现了数据和操作的结合,使数 ...
- 百度之星资格赛 hdu 4826 Labyrinth 动态规划
/********************* Problem Description 是一仅仅喜欢探险的熊.一次偶然落进了一个m*n矩阵的迷宫,该迷宫仅仅能从矩阵左上角第一个方格開始走,仅仅有走到右上 ...
- TypedArray和obtainStyledAttributes使用
在编写Android自定义按钮示例基础上,如果要指定字体大小产生这样的效果: 其实是不需要自定义变量的,可以直接使用TextView的配置属性: <com.easymorse.textbutto ...
- 一个小的程序--实现中英文切换(纯css)
<!doctype html><html lang="en"> <head> <meta charset="UTF-8" ...
- Char Tools,方便的字符编码转换小工具
工作关系,常有字符编码转换方面的需要,写了这个小工具 Char Tools是一款方便的字符编码转换小工具,基于.Net Framework 2.0 Winform开发 主要功能 URL编码:URLEn ...
- 解决Android SDK Manager下载太慢问题(转)
1.打开android sdk manager 2.打开tool->options,如图所示 3.将Proxy Settings 里的HTTP Proxy Server和HTTP Proxy P ...
- 如何获取外网Ip呢, 终于找到方法了
临时更换网址:http://20140507.ip138.com/ic.asp 这个网址能同时获取ip和城市名字 上面的网址如何来的呢,其实很简单,随便打开一个获取Ip的网站,比如http://www ...
- android 自定义view之 TypeArray
在定义view的时候,我们可以使用系统提供的属性,也可以自定义些额外的属性来设置自定义view的样式,这个时候,我们就需要TypeArray,字面意思就是Type 数组. 今天我们就讲讲如何自定义Vi ...
- iOS 中实现随机颜色
开发中为了测试能够快速看到效果很多时候我们对颜色采用随机颜色 代码块如下 UIColor * randomColor= [UIColor colorWithRed:((float)arc4random ...
- 如何改写WebApi部分默认规则
为什么要改 最近公司在推广SOA框架,第一次正经接触这种技术(之前也有但还是忽略掉吧),感觉挺好,就想自己也折腾一下,实现一个简单的SOA框架 用过mvc进行开发,印象之中WebApi和Mvc好像是一 ...