HBase二级索引的设计(案例讲解)
摘要
最近做的一个项目涉及到了多条件的组合查询,数据存储用的是HBase,恰恰HBase对于这种场景的查询特别不给力,一般HBase的查询都是通过RowKey(要把多条件组合查询的字段都拼接在RowKey中显然不太可能),或者全表扫描再结合过滤器筛选出目标数据(太低效),所以通过设计HBase的二级索引来解决这个问题
查询需求
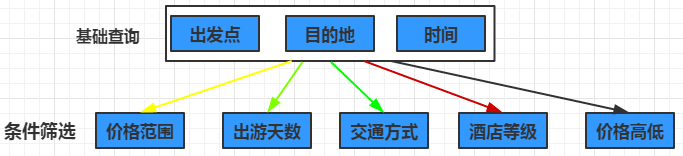
多个查询条件构成多维度的组合查询,需要根据不同组合查询出符合查询条件的数据
HBase的局限性
HBase本身只提供基于行键和全表扫描的查询,而行键索引单一,对于多维度的查询困难(如:对于价格+天数+酒店+交通的多条件组合查询困难),全表扫描效率低下。
二级索引的设计
设计思路
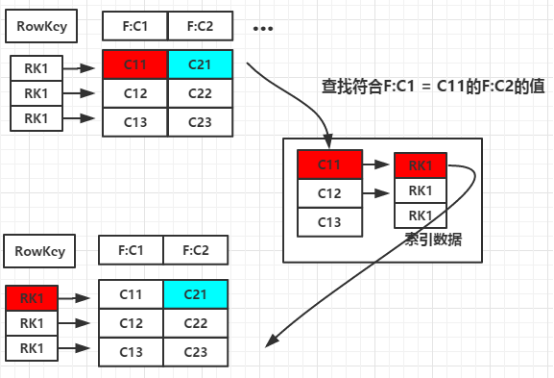
(图1)设计思路
二级索引的本质就是建立各列值与行键之间的映射关系
如(图1),当要对F:C1这列建立索引时,只需要建立F:C1各列值到其对应行键的映射关系,如C11->RK1等,这样就完成了对F:C1列值的二级索引的构建,当要查询符合F:C1=C11对应的F:C2的列值时(即根据C1=C11来查询C2的值,图1青色部分)其查询步骤如下: 1. 根据C1=C11到索引数据中查找其对应的RK,查询得到其对应的RK=RK1 2. 得到RK1后就自然能根据RK1来查询C2的值了 这是构建二级索引大概思路,其他组合查询的联合索引的建立也类似。
逻辑视图
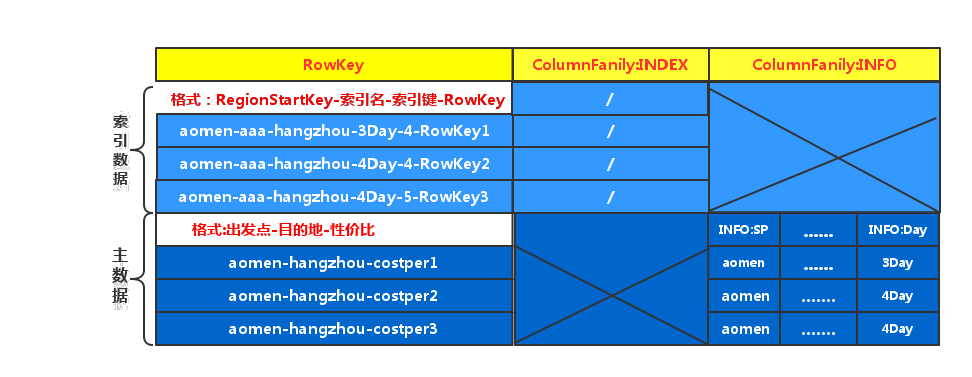
(图2) 部分数据在HBase中存储的逻辑视图
表中有两个列族,其中一个是列族INDEX,其并不存储任何的数据,仅仅是为了将索引数据与主数据分开存储(因为在HBase中同一列族的数据会被压缩在一起存储),索引数据的行键格式为:RegionStartKey-索引名-索引键-Rowkwy,其他RegionStartKey就是出发点,因为在创建HBase表时就对表根据出发点进行了预分区,索引键为主数据中某列(可能是多列)的列值,Rowkey对应主数据的行键;主数据的行键格式为:出发点-目的地-性价比,所以在存储数据时,同一出发点 目的地的数据默认是按性价比排序的;索引数据的行键和主数据的行键的前缀都是出发点,所以在存储时相同出发点的索引数据和主数据是存储在同一个Region中的,这样避免了在通过索引得到RK后又去其他Region上查询目标数据,提高了查询效率。
数据的查询过程
假设查询的条件:
出发点:澳门
目的地:杭州
出游天数:3天
酒店等级:4
其查询步骤如下:
首先根据查询条件来确定索引名,根据其查询条件为出游天数据 酒店等级确定索引名为aaa,这样就将查询的范围缩小在索引名为aaa的索引数据区内
根据出游天数的值为3天,酒店等级的值为4,结合Phoenix的模糊查询就能确定符合这两个查询条件的索引数据的行键
得到索引数据行键后就截取其最后的RowKey
最关键的Rowkey得到后就能轻易的获得其对应的列值了,整个查询过程就结束了。
对于其他更为复杂的组合查询的二级索引设计如类似。
缺点
需要额外的存储空间,属 一种以空间换时间的方式。
注意
1.将查询条件中的可选字段转换成数字能节省存储空间,如交通工具中的飞机,高铁,火车,轮船,汽车分别转换成5,4,3,2,1
2.将汉字转换成拼音才能保证数据按HBase的排序规则排序
3.如果数据量在百万级别以下可使用Phoenix(HBase的SQL查询引擎)模糊查询功能减少索引行键的设计
参考资料
HBase二级索引的设计(案例讲解)的更多相关文章
- HBase之八--(1):HBase二级索引的设计(案例讲解)
摘要 最近做的一个项目涉及到了多条件的组合查询,数据存储用的是HBase,恰恰HBase对于这种场景的查询特别不给力,一般HBase的查询都是通过RowKey(要把多条件组合查询的字段都拼接在RowK ...
- HBase二级索引的设计
摘要 最近做的一个项目涉及到了多条件的组合查询,数据存储用的是HBase,恰恰HBase对于这种场景的查询特别不给力,一般HBase的查询都是通过RowKey(要把多条件组合查询的字段都拼接在RowK ...
- HBase学习(四) 二级索引 rowkey设计
HBase学习(四) 一.HBase的读写流程 画出架构 1.1 HBase读流程 Hbase读取数据的流程:1)是由客户端发起读取数据的请求,首先会与zookeeper建立连接2)从zookeepe ...
- HBase二级索引方案总结
转自:http://blog.sina.com.cn/s/blog_4a1f59bf01018apd.html 附hbase如何创建二级索引以及创建二级索引实例:http://www.aboutyun ...
- HBase二级索引、读写流程
HBase二级索引.读写流程 一.HBse二级索引方案 1.1 基于Coprocessor方案 1.2 Phoenix二级索引特点 1.3 Phoenix 二级索引方案 二.HBase读写流程 2.1 ...
- hbase 二级索引创建
在单机上运行hbase 二级索引: import java.io.IOException; import java.util.HashMap; import java.util.Map; import ...
- HBase 二级索引与Join
二级索引与索引Join是Online业务系统要求存储引擎提供的基本特性.RDBMS支持得比较好,NOSQL阵营也在摸索着符合自身特点的最佳解决方案. 这篇文章会以HBase做为对象来探讨如何基于Hba ...
- HBase二级索引与Join
转自:http://www.oschina.net/question/12_32573 二级索引与索引Join是Online业务系统要求存储引擎提供的基本特性.RDBMS支持得比较好,NOSQL阵营也 ...
- HBase之八--(2):HBase二级索引之Phoenix
1. 介绍 Phoenix 是 Salesforce.com 开源的一个 Java 中间件,可以让开发者在Apache HBase 上执行 SQL 查询.Phoenix完全使用Java编写,代码位于 ...
随机推荐
- 杭州电 1372 Knight Moves(全站搜索模板称号)
http://acm.hdu.edu.cn/showproblem.php?pid=1372 Knight Moves Time Limit: 2000/1000 MS (Java/Others) ...
- Bitmap的一些操作
1.截取 Bitmap 的部分区域 mBitmap = Bitmap.createBitmap(bmp, 100, 100, 120, 120); 这句代码从 bmp 的 (100,100) 处截取 ...
- Android 屏幕适配方案
转载请标明出处: http://blog.csdn.net/lmj623565791/article/details/45460089: 本文出自:[张鸿洋的博客] 1.概述 大家在Android开发 ...
- 服务 Service 基本介绍
Activity public class MainActivity extends ListActivity { private boolean flag;//是否开启线程 publ ...
- (二)一个工作任务引起的乱战——C++程序编译为dll,让C#调用
C++程序编译为C#可调用的dll的过程: 1.新建一个Win32 Console Application 项目,项目名为:DLLDemo,下一步选择Application type为DLL; 2.在 ...
- easyui 点击combox 文本框 显示下拉 panel
$(".combo-text").click(function () { var mid = $(this).parent().parent().find("select ...
- JS 函数参数
1.简单的无参函数调用 function Test1(Func) { Func(); } function Test2() { alert("我要被作为函数参数啦!"); } // ...
- .net web api 的route理解
.NET web api 的特性是和MVC一样,通过Route 来控制action的访问方式.Route匹配规则是个奇特的方式,首先看一段Route的模板 Routes.MapHttpRoute( n ...
- Swift中的协议
协议: 1.Swift协议用于定义多个类型应该遵守的规范 2.协议定义了一种规范, 不提供任何实现 3.协议统一了属性名, 方法, 下标, 但是协议并不提供任何实现 4.语法格式: [修饰符] pro ...
- 【C#】.NET中设置代理服务器浏览网页的实现--转载
目前很多种类的浏览器中都有代理服务器的设置,用户可以通过浏览器自定义更换自己的IP,实现在线代理翻(河蟹)墙浏览网页. 而在.NET中,亦可以通过调用API函数InternetSetOption来实现 ...