机器学习-EM算法笔记
EM算法也称期望最大化(Expectation-Maximum,简称EM)算法,它是一个基础算法,是很多机器学习领域算法的基础,比如隐式马尔科夫算法(HMM), LDA主题模型的变分推断,混合高斯模型GMM,基于概率统计的pLSA模型。
EM算法概述(原文)
我们经常会从样本观察数据中,找出样本的模型参数。 最常用的方法就是极大化模型分布的对数似然函数。
但是在一些情况下,我们得到的观察数据有未观察到的隐含数据,此时我们未知的有隐含数据和模型参数,因而无法直接用极大化对数似然函数得到模型分布的参数。这时可以使用EM算法。
EM算法解决这个的思路是使用启发式的迭代方法,既然我们无法直接求出模型分布参数,那么我们可以先猜想隐含数据(EM算法的E步),接着基于观察数据和猜测的隐含数据一起来极大化对数似然,求解我们的模型参数(EM算法的M步)。由于我们之前的隐藏数据是猜测的,所以此时得到的模型参数一般还不是我们想要的结果。不过没关系,我们基于当前得到的模型参数,继续猜测隐含数据(EM算法的E步),然后继续极大化对数似然,求解我们的模型参数(EM算法的M步)。以此类推,不断的迭代下去,直到模型分布参数基本无变化,算法收敛,找到合适的模型参数。
从上面的描述可以看出,EM算法是迭代求解最大值的算法,同时算法在每一次迭代时分为两步,E步和M步。一轮轮迭代更新隐含数据和模型分布参数,直到收敛,即得到我们需要的模型参数。
一个最直观了解EM算法思路的是K-Means算法。在K-Means聚类时,每个聚类簇的质心是隐含数据。我们会假设K个初始化质心,即EM算法的E步;然后计算得到每个样本最近的质心,并把样本聚类到最近的这个质心,即EM算法的M步。重复这个E步和M步,直到质心不再变化为止,这样就完成了K-Means聚类。
当然,K-Means算法是比较简单的,实际中的问题往往没有这么简单。上面对EM算法的描述还很粗糙,我们需要用数学的语言精准描述。
EM算法的推导
对于m个样本观察数据x=(x(1),x(2),...x(m))中,找出样本的模型p(x,z)参数θ, 对数似然函数如下:

模型中存在隐函数z=(z(1),z(2),...z(m))随机变量,不方便直接找到参数估计,所以这时候引入Q(Z(i)),注意不是随便引入一个函数的,这个函数是Z的一个分布,且Q(Z(i))≥0,这时为了让原来的对数似然函数不变,我们可以作出如下(2)变换公式:
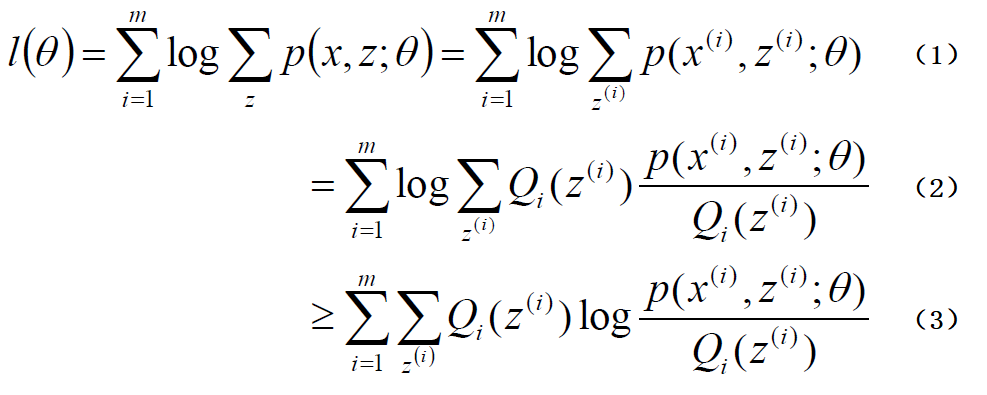
第(3)步利用了Jensen不等式。
Jensen不等式:若f是凸函数:
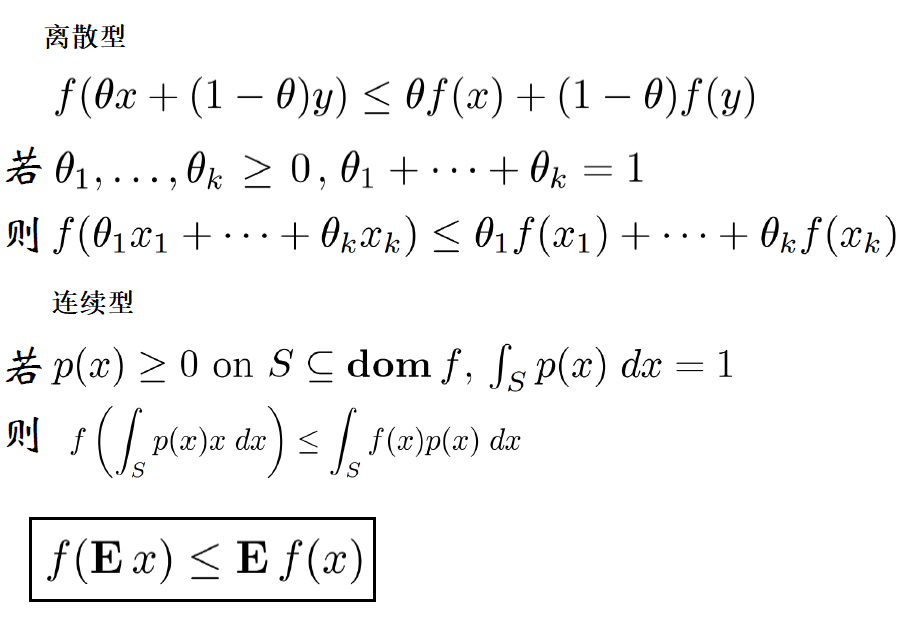
对于第(3)步中不等式中,若要满足相等的情况,需要满足条件:

c为常数,又因为:
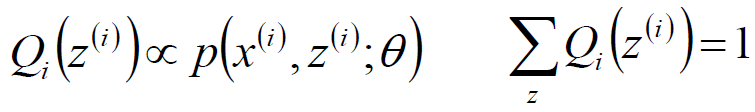
所以可以推出:
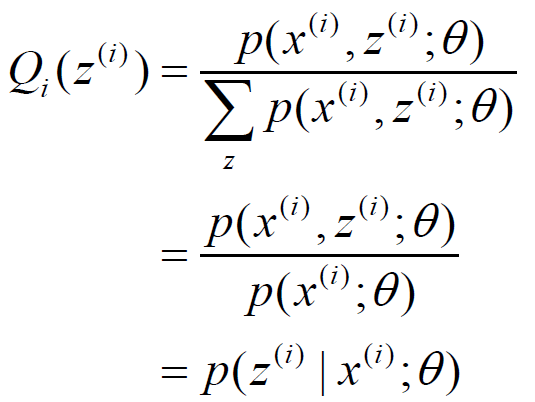
如果Qi(z(i))=P(z(i)|x(i);θ)), 则第(3)式是我们的包含隐藏数据的对数似然的一个下界。如果我们能极大化这个下界,则也在尝试极大化我们的对数似然。即我们需要最大化下式:
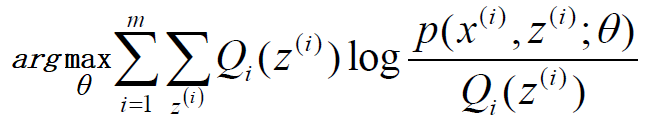
去掉上式中为常数的部分,则我们需要极大化的对数似然下界为:
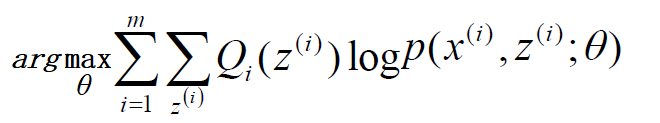
上式也就是我们的EM算法的M步,那E步呢?注意到上式中Qi(z(i))是一个分布,因此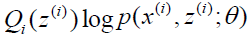 可以理解为logP(x(i),z(i);θ)基于条件概率分布Qi(z(i))的期望。
可以理解为logP(x(i),z(i);θ)基于条件概率分布Qi(z(i))的期望。
EM算法的流程总结:
输入:观察数据x=(x(1),x(2),...x(m)),联合分布p(x,z;θ), 条件分布p(z|x;θ), 最大迭代次数J。
1) 随机初始化模型参数θ的初值θ0。
2) for j from 1 to J开始EM算法迭代:
a) E步:计算联合分布的条件概率期望:
Qi(z(i))=P(z(i)|x(i),θj)

b) M步:极大化L(θ,θj),得到θj+1:

c) 如果θj+1已收敛,则算法结束。否则继续回到步骤a)进行E步迭代。
输出:模型参数θ。
关于EM算法的收敛性可以参照此博文的EM算法的收敛性思考。
补充:
如果我们从算法思想的角度来思考EM算法,我们可以发现我们的算法里已知的是观察数据,未知的是隐含数据和模型参数,在E步,我们所做的事情是固定模型参数的值,优化隐含数据的分布,而在M步,我们所做的事情是固定隐含数据分布,优化模型参数的值。
机器学习-EM算法笔记的更多相关文章
- 机器学习-EM算法-pLSA模型笔记
pLSA模型--基于概率统计的pLSA模型(probabilistic Latent Semantic Analysis,概率隐语义分析),增加了主题模型,形成简单的贝叶斯网络,可以使用EM算法学习模 ...
- EM算法笔记
EM算法在很多地方都用使用到,比如简单的K-means算法,还有在隐马尔可夫里面,也涉及到了EM算法,可见EM算法在机器学习领域的重要地位.在这里就写一下我对于EM算法的一些理解笔记.后续有新的理解也 ...
- 读吴恩达算-EM算法笔记
最近感觉对EM算法有一点遗忘,在表述的时候,还是有一点说不清,于是重新去看了这篇<CS229 Lecture notes>笔记. 于是有了这篇小札. 关于Jensen's inequali ...
- 机器学习——EM算法
1 数学基础 在实际中,最小化的函数有几个极值,所以最优化算法得出的极值不确实是否为全局的极值,对于一些特殊的函数,凸函数与凹函数,任何局部极值也是全局极致,因此如果目标函数是凸的或凹的,那么优化算法 ...
- 机器学习-EM算法
最大期望算法 EM算法的正式提出来自美国数学家Arthur Dempster.Nan Laird和Donald Rubin,其在1977年发表的研究对先前出现的作为特例的EM算法进行了总结并给出了标准 ...
- 机器学习-EM算法的收敛证明
上一篇开头说过1983年,美国数学家吴建福(C.F. Jeff Wu)给出了EM算法在指数族分布以外的收敛性证明. EM算法的收敛性只要我们能够证明对数似然函数的值在迭代的过程中是增加的 即可: 证明 ...
- 机器学习——EM算法与GMM算法
目录 最大似然估计 K-means算法 EM算法 GMM算法(实际是高斯混合聚类) 中心思想:①极大似然估计 ②θ=f(θold) 此算法非常老,几乎不会问到,但思想很重要. EM的原理推导还是蛮复杂 ...
- 机器学习-EM算法-GMM模型笔记
GMM即高斯混合模型,下面根据EM模型从理论公式推导GMM: 随机变量X是有K个高斯分布混合而成,取各个高斯分布的概率为φ1,φ2,... ,φK,第i个高斯分布的均值为μi,方差为Σi.若观测到随机 ...
- 机器学习经典算法笔记-Support Vector Machine SVM
可供使用现成工具:Matlab SVM工具箱.LibSVM.SciKit Learn based on python 一 问题原型 解决模式识别领域中的数据分类问题,属于有监督学习算法的一种. 如图所 ...
随机推荐
- ORACLE数据库特性
目录 ORACLE数据库特性 一.学习路径 二.ORACLE的进程情况 三.ORACLE服务器的启动和关闭 (SQLPLUS环境挂起和恢复等) 连接Oracle的几种方式 四.几个关注点 1. ORA ...
- java输出程序运行时间
做了一个MapReduce的小练习,想测试一下程序运行时间: 代码: long start = System.currentTimeMillis(); /*运行的程序主体*/ long end = S ...
- Vue基础学习 --- 全局组件与局部组件
组件分为 全局组件 局部组件 全局组件 // 语法---Vue.component('组件名', {组件参数}) Vue.component('com1', { template: '<butt ...
- CNS、ENS和PNS的发育过程
central nervous system (CNS) peripheral nervous system (PNS) enteric nervous system (ENS) 做这部分的科研必须要 ...
- vuejs2从入门到精通视频教程
https://www.cnblogs.com/web-666/p/8648607.html 一.基础部分 0.课件 1.介绍 2.vue实例 3.模板语法 4.计算属性和观察者 5.Class与St ...
- 如何使用eclipse创建简单的servlet
Servlet是一种基于java开发的服务器程序,可以对外公布服务,如果是浏览器应用,可以通过浏览器打开网址的方式查看服务.创建servlet要继承httpservlet,并且在web.xml中配置拦 ...
- 阿里云配置WAF的步骤
date:2019-07-04 17:59:19 author: headsen chen 配置WAF防护策略 本页目录 操作步骤 网站接入Web应用防火墙(WAF)后,WAF以默认防护策略为其过滤 ...
- 【转载】 漫谈Code Review的错误实践
原文地址: https://www.cnblogs.com/chaosyang/p/code-review-wrong-practices.html ------------------------- ...
- ubuntu 关于curses头文件问题
执行编译gcc -o badterm badterm.c -lcurses后报错情报如下:term.h: 没有那个文件或目录curses.h: 没有那个文件或目录很明显,程序找不到term.h和cur ...
- Linux记录-批量安装ssh(转载)
首先,需要检查expect是否安装:rpm -qa|grep expect 然后,在操作机上创建公钥:ssh-keygen 一路回车即可 创建好之后到/root/.ssh/下就可以看到id开头的2个文 ...