13、SparkContext详解
一、SparkContext原理
1、图解
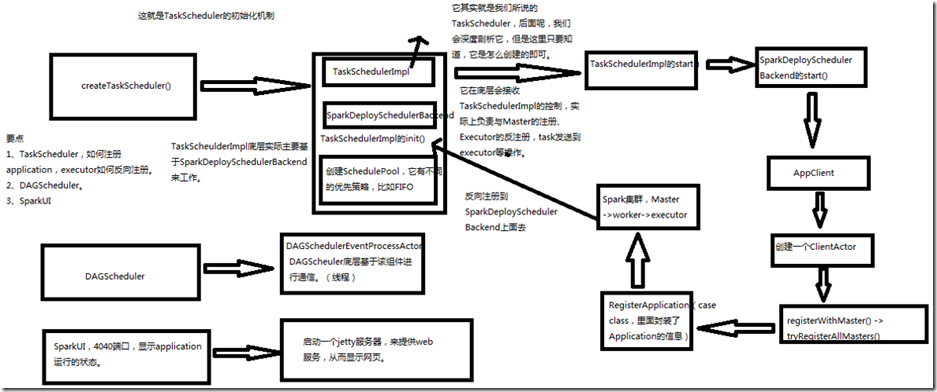
1、当driver启动后会去运行我们的application,在运行application的时候,所有spark程序的第一行都是先创建SparkContext,在创建SparkContext的时候,它的内部创建
两个非常重要的东西DAGSchedule和TaskSchedule,TaskSchedule在创建的时候就会向spark集群的master进行注册。 2、spark最核心的内部会创建3个东西,首先是会createTaskScheduler(),createTaskScheduler()里面会创建三个东西,首先是TaskSchedulerImpl(它其实就是TaskScheduler),
然后创建SparkDeploySchedulerBackend(它在底层会受TaskSchedulerImp的控制,实际上负责与Master的注册,Executor的反注册,Task发送到Executor等操作),然后调用
TaskSchedulerImpl的init()方法,创建SchedulerPool调度池 ,它有不同的优先策略,比如FIFO先进先出。 3、在创建完TaskSchedulerImpl和SparkDeploySchedulerBackend之后,是执行TaskSchedulerImpl的start()方法,这个方法内部实际上会调用SparkDeploySchedulerBackend的
start()方法,在这个start()方法里会创建AppClient,AppClient里会启动一个线程,也就是ClientActor,ClientActor会调用两个方法,registerWithMaster(),会去调用
tryRegisterAllMaster()。这两个方法会向master发送一个东西叫做RegisterApplication(case class,里面封装了application的信息),就会发送到spark集群的Master上面去,
后面回去找worker,然后启动executor,然后executor启动后会反向注册到SparkDeploySchedulerBackend上面去。这就是TaskScheduler的初始化机制。TaskSchedulerImpl底层
主要基于SparkDeploySchedulerBackend工作。 4、DAGScheduler创建的时候有一个非常重要的东西,DAGSchedulerEvenProcessActor,DAGScheduler底层基于该组件进行通讯(线程) 5、SparkUI。4040端口,线上application运行的状态,启动一个jetty服务器,来提供web服务,从而显示网页。
二、SparkContext源码
1、TaskScheduler创建
###SparkContext.scala // Create and start the scheduler
private[spark] var (schedulerBackend, taskScheduler) =
SparkContext.createTaskScheduler(this, master) //不同的提交模式,会创建不同的TaskScheduler
//standalone模式
case SPARK_REGEX(sparkUrl) =>
//TaskSchedulerImpl()底层通过操作一个SchedulerBackend,针对不同的种类的cluster(standalone、yarn和mesos),调度task。 //他也可以通过使用一个LocalBackend,并且将isLocal参数设置为true,来在本地模式下工作。 //它负责处理一些通用的逻辑,比如决定多个job的调度顺序,启动检查任务执行 //客户端首先应用调度initialize()方法和start()方法,然后通过runTasks()方法提交task sets
val scheduler = new TaskSchedulerImpl(sc)
val masterUrls = sparkUrl.split(",").map("spark://" + _)
val backend = new SparkDeploySchedulerBackend(scheduler, sc, masterUrls)
scheduler.initialize(backend)
(backend, scheduler) ###TaskSchedulerImpl.scala def initialize(backend: SchedulerBackend) {
this.backend = backend
// temporarily set rootPool name to empty
rootPool = new Pool("", schedulingMode, 0, 0)
schedulableBuilder = {
schedulingMode match {
case SchedulingMode.FIFO =>
new FIFOSchedulableBuilder(rootPool)
case SchedulingMode.FAIR =>
new FairSchedulableBuilder(rootPool, conf)
}
}
schedulableBuilder.buildPools()
}
TaskScheduler启动:
###TaskSchedulerImpl.scala
override def start() {
//重点是调用了SparkDeploySchedulerBackend类的start
backend.start()
if (!isLocal && conf.getBoolean("spark.speculation", false)) {
logInfo("Starting speculative execution thread")
import sc.env.actorSystem.dispatcher
sc.env.actorSystem.scheduler.schedule(SPECULATION_INTERVAL milliseconds,
SPECULATION_INTERVAL milliseconds) {
Utils.tryOrExit { checkSpeculatableTasks() }
}
}
}
###SparkDeploySchedulerBackend.scala
override def start() {
super.start()
// The endpoint for executors to talk to us
val driverUrl = AkkaUtils.address(
AkkaUtils.protocol(actorSystem),
SparkEnv.driverActorSystemName,
conf.get("spark.driver.host"),
conf.get("spark.driver.port"),
CoarseGrainedSchedulerBackend.ACTOR_NAME)
val args = Seq(
"--driver-url", driverUrl,
"--executor-id", "{{EXECUTOR_ID}}",
"--hostname", "{{HOSTNAME}}",
"--cores", "{{CORES}}",
"--app-id", "{{APP_ID}}",
"--worker-url", "{{WORKER_URL}}")
val extraJavaOpts = sc.conf.getOption("spark.executor.extraJavaOptions")
.map(Utils.splitCommandString).getOrElse(Seq.empty)
val classPathEntries = sc.conf.getOption("spark.executor.extraClassPath")
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
val libraryPathEntries = sc.conf.getOption("spark.executor.extraLibraryPath")
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
// When testing, expose the parent class path to the child. This is processed by
// compute-classpath.{cmd,sh} and makes all needed jars available to child processes
// when the assembly is built with the "*-provided" profiles enabled.
val testingClassPath =
if (sys.props.contains("spark.testing")) {
sys.props("java.class.path").split(java.io.File.pathSeparator).toSeq
} else {
Nil
}
// Start executors with a few necessary configs for registering with the scheduler
val sparkJavaOpts = Utils.sparkJavaOpts(conf, SparkConf.isExecutorStartupConf)
val javaOpts = sparkJavaOpts ++ extraJavaOpts
val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend",
args, sc.executorEnvs, classPathEntries ++ testingClassPath, libraryPathEntries, javaOpts)
val appUIAddress = sc.ui.map(_.appUIAddress).getOrElse("")
//ApplicationDescription非常重要,它代表了当前的这个
//application的一切情况
//包括application最大需要多少CPU core,每个slave上需要多少内存
val appDesc = new ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
appUIAddress, sc.eventLogDir, sc.eventLogCodec)
//创建APPClient
//APPClient是一个接口,它负责为application与Spark集群进行通信。
//它会接收一个Spark Master的URL,以及一个application,和
//一个集群事件的监听器,以及各种事件发生时监听器的回调函数
client = new AppClient(sc.env.actorSystem, masters, appDesc, this, conf)
client.start()
waitForRegistration()
}
2、DAGScheduler创建
###SparkContext.scala @volatile private[spark] var dagScheduler: DAGScheduler = _
try {
//DAGScheduler类实现了面向stage的调度机制的高层次的调度层,他会为每个job计算一个stage的DAG(有向无环图),
//追踪RDD和stage的输出是否被物化了(物化就是说,写入了磁盘或者内存等地方),并且寻找一个最少
//消耗(最优、最小)调度机制来运行job,它会将stage作为tasksets提交到底层的TaskSchedulerImple上,
//来在集群上运行它们(task)
//除了处理stage的DAG,它还负责决定运行每个task的最佳位置,基于当前的缓存状态,将这些最佳位置提交底层的
//TaskSchedulerImpl。此外,它会处理理由于shuffle输出文件丢失导致的失败,在这种情况下,旧的stage可能就会
//被重新提交,一个stage内部的失败,如果不是由于shuffle文件丢失所导致的,会被TAskSchedule处理,它会多次重试
//每一个task,直到最后,实在是不行了,才会去取消整个stage
dagScheduler = new DAGScheduler(this)
} catch {
case e: Exception => {
try {
stop()
} finally {
throw new SparkException("Error while constructing DAGScheduler", e)
}
}
}
3、SparkUI的创建
###SparkContext.scala // Initialize the Spark UI
private[spark] val ui: Option[SparkUI] =
if (conf.getBoolean("spark.ui.enabled", true)) {
Some(SparkUI.createLiveUI(this, conf, listenerBus, jobProgressListener,
env.securityManager,appName))
} else {
// For tests, do not enable the UI
None
} ###SparkUI.scall //默认端口
val DEFAULT_PORT = 4040
def createLiveUI(
sc: SparkContext,
conf: SparkConf,
listenerBus: SparkListenerBus,
jobProgressListener: JobProgressListener,
securityManager: SecurityManager,
appName: String): SparkUI = {
create(Some(sc), conf, listenerBus, securityManager, appName,
jobProgressListener = Some(jobProgressListener))
}
13、SparkContext详解的更多相关文章
- 在CentOS上编译安装MySQL 5.7.13步骤详解
MySQL 5.7主要特性 更好的性能 对于多核CPU.固态硬盘.锁有着更好的优化,每秒100W QPS已不再是MySQL的追求,下个版本能否上200W QPS才是用户更关心的. 更好的InnoDB存 ...
- spark[源码]-sparkContext详解[一]
spark简述 sparkContext在Spark应用程序的执行过程中起着主导作用,它负责与程序和spark集群进行交互,包括申请集群资源.创建RDD.accumulators及广播变量等.spar ...
- Java容器解析系列(13) WeakHashMap详解
关于WeakHashMap其实没有太多可说的,其与HashMap大致相同,区别就在于: 对每个key的引用方式为弱引用; 关于java4种引用方式,参考java Reference 网上很多说 弱引用 ...
- Appium自动化(13) - 详解 Keyboard 类里的方法和源码分析
如果你还想从头学起Appium,可以看看这个系列的文章哦! https://www.cnblogs.com/poloyy/category/1693896.html 前言 Keyboard 类在 a ...
- Jmeter 常用函数(13)- 详解 __machineIP
如果你想查看更多 Jmeter 常用函数可以在这篇文章找找哦 https://www.cnblogs.com/poloyy/p/13291704.html 作用 返回机器(电脑)IP 语法格式 ${_ ...
- 【小白学PyTorch】13 EfficientNet详解及PyTorch实现
参考目录: 目录 1 EfficientNet 1.1 概述 1.2 把扩展问题用数学来描述 1.3 实验内容 1.4 compound scaling method 1.5 EfficientNet ...
- Java(13)详解构造方法
作者:季沐测试笔记 原文地址:https://www.cnblogs.com/testero/p/15201600.html 博客主页:https://www.cnblogs.com/testero ...
- 13.Linux键盘驱动 (详解)
版权声明:本文为博主原创文章,未经博主允许不得转载. 在上一节分析输入子系统内的intput_handler软件处理部分后,接下来我们开始写input_dev驱动 本节目标: 实现键盘驱动,让开发板的 ...
- 【STM32H7教程】第13章 STM32H7启动过程详解
完整教程下载地址:http://forum.armfly.com/forum.php?mod=viewthread&tid=86980 第13章 STM32H7启动过程详解 本章教 ...
随机推荐
- Codechef TSUM2 Sum on Tree 点分治、李超线段树
传送门 点分治模板题都不会迟早要完 发现这道题需要统计所有路径的信息,考虑点分治统计路径信息. 点分治之后,因为路径是有向的,所以对于每一条路径都有向上和向下的两种.那么如果一条向上的路径,点数为\( ...
- 牛客挑战赛33 B-鸽天的放鸽序列
也许更好的阅读体验 \(\mathcal{Description}\) 定义一个长为\(n\)的\(01\)序列\(A_1, A_2, \dots, A_n\)的权值为\(\sum_{i=1}^n ...
- docker-compose命令使用说明
Commands: build Build or rebuild services bundle Generate a Docker bundle from the Compose file conf ...
- .net语音播放,自定义播报文字
// using System.Speech.Synthesis; SpeechSynthesizer synth = new SpeechSynthesizer(); // Configure th ...
- C#采集麦克风话筒声音
在项目中,我们会需要录制麦克风的声音.比如录制QQ聊天时自己说的话.那么如何采集呢?当然是采用SharpCapture!下面开始演示关键代码,您也可以在文末下载全部源码: 设置授权 第一步:在引用了S ...
- python day10: 反射补充,面向对象
目录 pythdon day 10 1. 反射补充 16. 面向对象 16.1 面向对象初步介绍 16.2 面向对象和面向过程区别 16.3 对象的进化 17. 类class 17.1 类的定义 17 ...
- 阅读笔记---第三章 Xen信息页
1.文件/xen/include/public/xen.h 2.第一个数据结构:启动信息页strat_info,启动信息页是GuestOS内核启动时,由Xen映射到GusetOS内存空间的一个物理页面 ...
- linux删除同目录及子目录下统一扩展名的文件
find . -name '*.csv' -type f -print -exec rm -rf {} \; 利用find去查找文件,点是指当前目录下,引号中是相应的数据的名称,自己可以定义,然后用t ...
- 快速构建ceph可视化监控系统-转载
前言 ceph的可视化方案很多,本篇介绍的是比较简单的一种方式,并且对包都进行了二次封装,所以能够在极短的时间内构建出一个可视化的监控系统 本系统组件如下: ceph-jewel版本 ceph_exp ...
- Redis一主二从Sentinel监控配置
本文基于Redis单实例安装安装.https://gper.club/articles/7e7e7f7ff7g5egc4g6b 开启哨兵模式,至少需要3个Sentinel实例(奇数个,否则无法选举Le ...