redis持久化rdb和aof之间的优势劣势
1、RDB(Redis Database)
a、基本概念
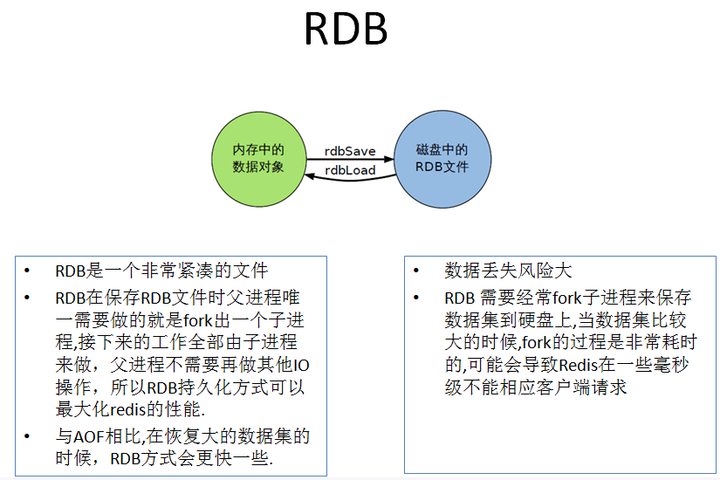
概念: 在指定的时间间隔内将内存中的数据集快照写入磁盘, 也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里。
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到 一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。 整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能 如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方 式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等) 数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程。
rdb 保存的是dump.rdb文件
b、如何触发RDB快照
①配置文件中默认的快照配置,冷拷贝后重新使用,可以cp dump.rdb dump_new.rdb。然后要还原数据的时候就将dump_new.rdb还原成dump.rdb,然后重新启动的时候就会自动加载。
②命令save或者是bgsave,这个会强制的备份。
Save:save时只管保存,其它不管,全部阻塞。BGSAVE:Redis会在后台异步进行快照操作, 快照同时还可以响应客户端请求。可以通过lastsave 命令获取最后一次成功执行快照的时间。- 执行flushall命令,也会产生
dump.rdb文件,但里面是空的,无意义 (当时还挖了一个坑)。
即: 调用
save也就是立刻、马上备份。flushAll也可以马上形成备份,但是没有意义。
redis.conf相关文件关于 RDB的配置:
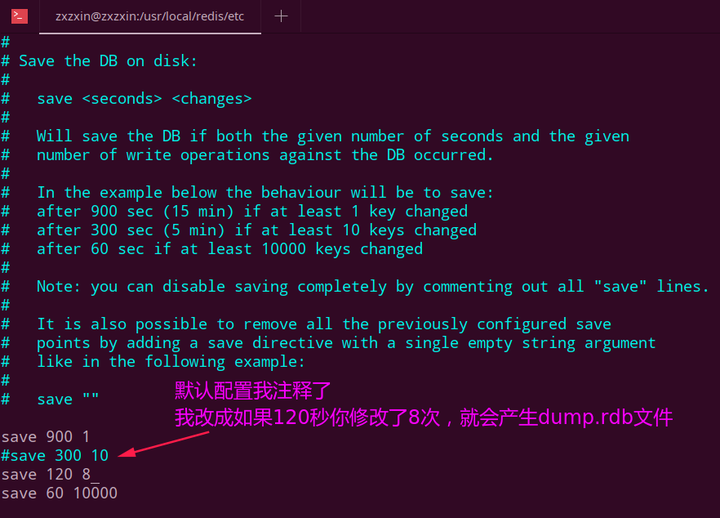
save配置:RDB是整个内存的压缩过的Snapshot,RDB的数据结构,可以配置复合的快照触发条件。默认是1分钟内改了1万次,
或5分钟内改了10次,
或15分钟内改了1次。stop-writes-on-bgsave-error: 如果配置成no,表示你不在乎数据不一致或者有其他的手段发现和控制。rdbcompression:rdbcompression:对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩。如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能。dbfilename: 默认是dump.rdb。dir: 生成dump.rdb的默认目录。
c、如何恢复
将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可。
CONFIG GET dir获取目录
d、优势和劣势
优势:
- 适合大规模的数据恢复;
- 对数据完整性和一致性要求不高;
劣势:
- 在一定间隔时间做一次备份,所以如果redis意外down掉的话,就 会丢失最后一次快照后的所有修改;
- fork的时候,内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑;
e、如何停止
动态所有停止RDB保存规则的方法:redis-cli config set save ""。
实战: 更换默认save,并使用dump.rdb恢复配置文件(后面未做了)
2、AOF(Append Only File)
a、基本概念
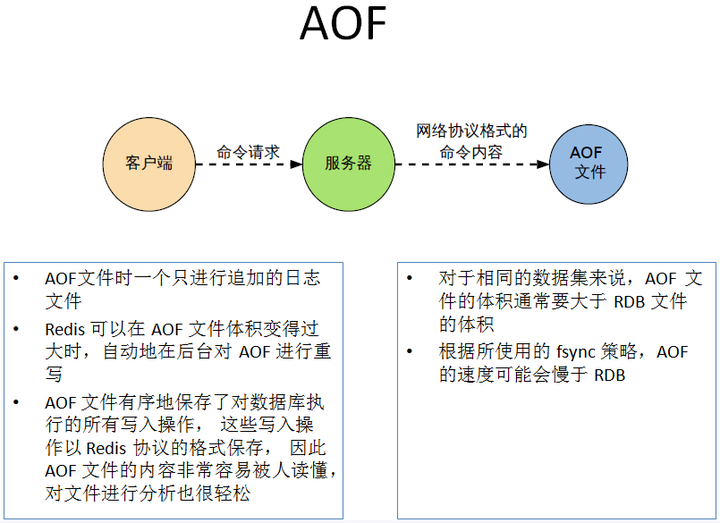
以日志的形式来记录每个写操作。
将Redis执行过的所有写指令记录下来(读操作不记录), 只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据,换言之,redis 重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
Aof保存的是appendonly.aof文件。
b、配置位置
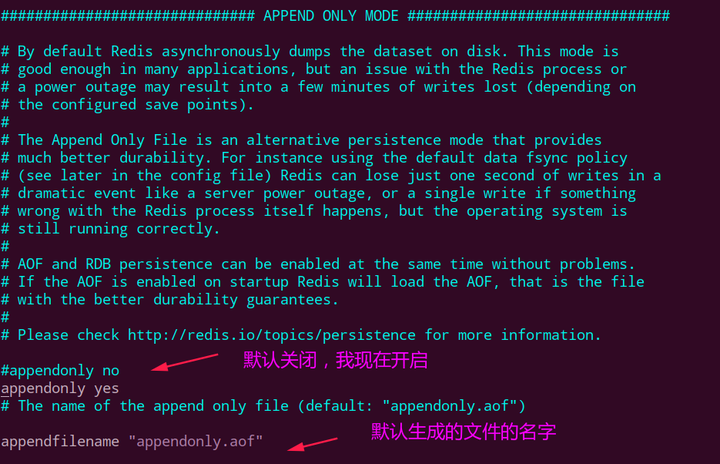
appendonly,默认是no,我们要改成yes才会有作用;appendfilename,默认是appendonly.aof;appendfsync:- always:同步持久化 每次发生数据变更会被立即记录到磁盘 性能较差但数据完整性比较好;
- everysec:出厂默认推荐,异步操作,每秒记录 如果一秒内宕机,有数据丢失;
- no;
no-appendfsync-on-rewrite:重写时是否可以运用Appendfsync,用默认no即可,保证数据安全性;auto-aof-rewrite-min-size:设置重写的基准值;auto-aof-rewrite-percentage:设置重写的基准值;
c、 AOF启动、恢复、修复
正常恢复:
- 启动:设置Yes, –> 修改默认的
appendonly no,改为yes。 - 将有数据的aof文件复制一份保存到对应目录(
config get dir); - 恢复:重启redis然后重新加载。
异常恢复(就是下面的搞破坏)
- 启备份被写坏的AOF文件;
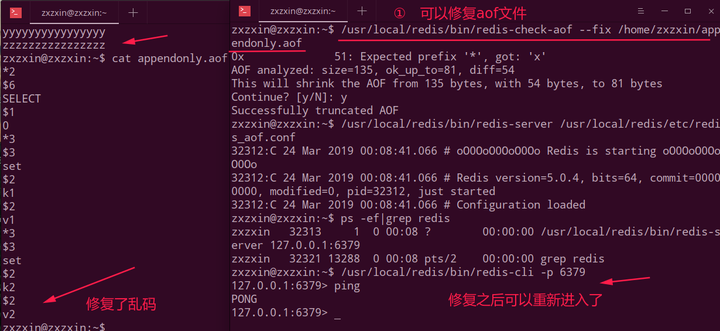
redis-check-aof --fix进行修复;
第一步: 启动redis-server之前和之后的,启动之后就会生成appendonly.aof文件:
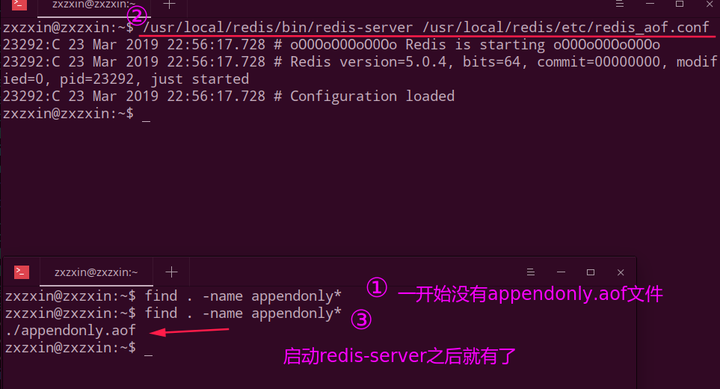
第二步: 进行相关操作并且查看更新之后的appendonly.aof文件:
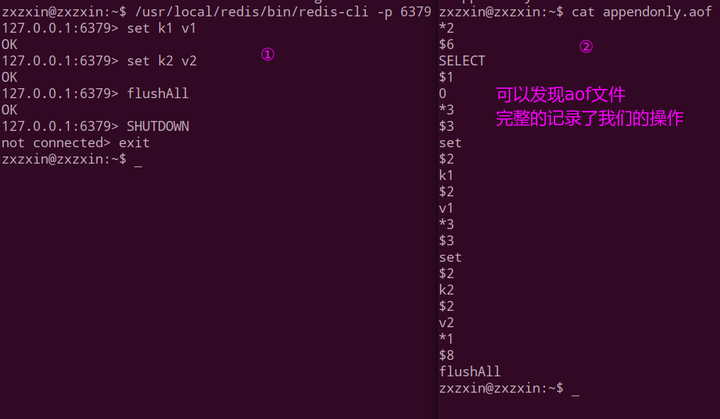
但是上述文件不能还原我们之前的数据,因为最后一样有一个flushAll,还原的时候也会执行这个,所以不能用这个还原,但是我们可以手动的编辑appendonly.aof文件,从而还原我们的数据库。
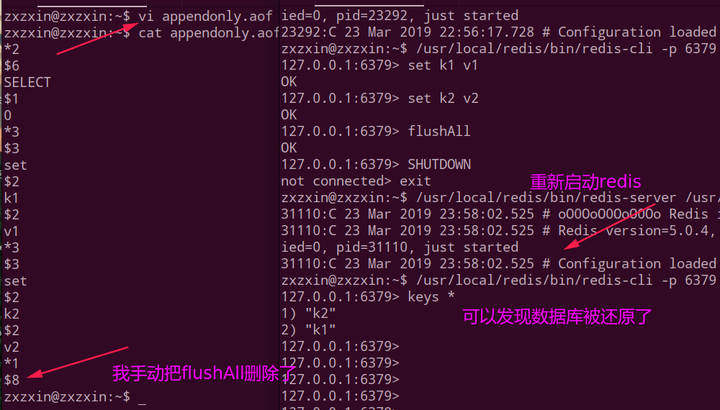
但是如果我们的appendonly.aof文件被破坏了,例如我随便加了一些乱码进去,这就会导致redis启动不了。
如下,虽然appendonly.aof和dump.rdb可以共存,但是会优先加载appendonly.aof,所以导致不能启动:
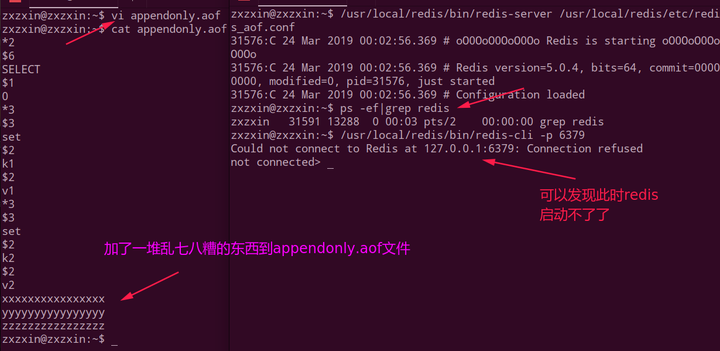
此时我们可以使用redis-check-aof --fix appendonly.aof来修复乱码文件:
d、重写rewrite
概念: AOF采用文件追加方式,文件会越来越大为避免出现此种情况,新增了重写机制, 当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的内容压缩, 只保留可以恢复数据的最小指令集.可以使用命令bgrewriteaof。
原理:
AOF文件持续增长而过大时,会fork出一条新进程来将文件重写(也是先写临时文件最后再rename), 遍历新进程的内存中数据,每条记录有一条的Set语句。重写aof文件的操作,并没有读取旧的aof文件, 而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似。
触发机制:
Redis会记录上次重写时的AOF大小,默认配置是当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发。
e、优势和劣势
优势:
- 每修改同步:
appendfsync always同步持久化 每次发生数据变更会被立即记录到磁盘 性能较差但数据完整性比较好。 - 每秒同步:
appendfsync everysec异步操作,每秒记录 如果一秒内宕机,有数据丢失。 - 不同步:
appendfsync no从不同步。
劣势:
- 相同数据集的数据而言aof文件要远大于rdb文件,恢复速度慢于rdb;
- aof运行效率要慢于rdb,每秒同步策略效率较好,不同步效率和rdb相同;
3、RDB和AOF对比和选择
- RDB持久化方式能够在指定的时间间隔能对你的数据进行快照存储。
- AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些 命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾. Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。
- 只做缓存:如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化方式。
- 同时开启:
- 在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据, 因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。
- RDB的数据不实时,同时使用两者时服务器重启也只会找AOF文件。那要不要只使用AOF呢? 作者建议不要,因为RDB更适合用于备份数据库(AOF在不断变化不好备份), 快速重启,而且不会有AOF可能潜在的bug,留着作为一个万一的手段。
性能建议:
因为RDB文件只用作后备用途,建议只在Slave上持久化RDB文件,而且只要15分钟备份一次就够了,只保留save 900 1这条规则。
如果Enalbe AOF,好处是在最恶劣情况下也只会丢失不超过两秒数据,启动脚本较简单只load自己的AOF文件就可以了。代价一是带来了持续的IO,二是AOF rewrite的最后将rewrite过程中产生的新数据写到新文件造成的阻塞几乎是不可避免的。只要硬盘许可,应该尽量减少AOF rewrite的频率,AOF重写的基础大小默认值64M太小了,可以设到5G以上。默认超过原大小100%大小时重写可以改到适当的数值。
如果不Enable AOF ,仅靠Master-Slave Replication 实现高可用性也可以。能省掉一大笔IO也减少了rewrite时带来的系统波动。代价是如果Master/Slave同时倒掉,会丢失十几分钟的数据,启动脚本也要比较两个Master/Slave中的RDB文件,载入较新的那个。新浪微博就选用了这种架构。
原文:http://www.java520.cn/redis/33.html
免费Java高级资料需要自己领取,涵盖了Java、Redis、MongoDB、MySQL、Zookeeper、Spring Cloud、Dubbo高并发分布式等教程,一共30G。
传送门:https://mp.weixin.qq.com/s/JzddfH-7yNudmkjT0IRL8Q
redis持久化rdb和aof之间的优势劣势的更多相关文章
- Linux - redis持久化RDB与AOF
目录 Linux - redis持久化RDB与AOF RDB持久化 redis持久化之AOF redis不重启,切换RDB备份到AOF备份 确保redis版本在2.2以上 实验环境准备 备份这个rdb ...
- redis持久化 RDB与AOF
redis持久化 RDB与AOF RDB与AOF区别 rdb: 基于快照的持久化,速度更快,一般用做备份,主从复制也是依赖于rdb持久化功能 aof:以追加的方式记录redis操作日志的文件,可以最大 ...
- redis持久化RDB和AOF
Redis 持久化: 提供了多种不同级别的持久化方式:一种是RDB,另一种是AOF. RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot). AO ...
- 配置方案:Redis持久化RDB和AOF
Redis持久化方案 Redis是内存数据库,数据都是存储在内存中,为了避免进程退出导致数据的永久丢失,需要定期将Redis中的数据以某种形式(数据或命令)从内存保存到硬盘.当下次Redis重启时,利 ...
- Redis持久化----RDB和AOF 的区别
关于Redis说点什么,目前都是使用Redis作为数据缓存,缓存的目标主要是那些需要经常访问的数据,或计算复杂而耗时的数据.缓存的效果就是减少了数据库读的次数,减少了复杂数据的计算次数,从而提高了服务 ...
- Redis(二)、Redis持久化RDB和AOF
一.Redis两种持久化方式 对Redis而言,其数据是保存在内存中的,一旦机器宕机,内存中的数据会丢失,因此需要将数据异步持久化到硬盘中保存.这样,即使机器宕机,数据能从硬盘中恢复. 常见的数据持久 ...
- Redis持久化RDB、AOF
持久化的意思就是保存,保存到硬盘.第一次接触这个词是在几年前学习EF. 为什么要持久化 redis定义:Redis是一个开源(BSD许可),内存存储的数据结构服务器,可用作数据库,高速缓存和消息队列代 ...
- redis 之redis持久化rdb与aof
redis是内存型的数据库 重启服务器丢失数据 重启redis服务丢失数据 断电丢失数据 Redis是一种内存型数据库,一旦服务器进程退出,数据库的数据就会丢失,为了解决这个问题,Redis提供了两种 ...
- redis 持久化RDB、AOF
1.redis持久化简介 Redis是一种高级key-value数据库.它跟memcached类似,不过数据可以持久化,而且支持的数据类型很丰富.有字符串,链表,集合和有序集合.支持在服务器端计算集合 ...
随机推荐
- jenkins如何构建C#代码写的网站
纯粹是因为同事习惯了写C#代码,开发的网站用C#编译, 对于习惯了用Maven编译的测试人员,真是一头雾水.不用jenkins吧,效率特别低,每次收到开发发过来的版本,还要进行数据库相关配置,是非常累 ...
- 网络流之最大流EK --- poj 1459
题目链接 本篇博客延续上篇博客(最大流Dinic算法)的内容,此次使用EK算法解决最大流问题. EK算法思想:在图中搜索一条从源点到汇点的扩展路,需要记录这条路径,将这条路径的最大可行流量 liu 增 ...
- MongoDB 之pymongodb
import pymongo import json from bson import ObjectId mongoclient = pymongo.MongoClient(host="12 ...
- 网络编程ssh,粘包
1.什么是socket? TCP,可靠地,面向连接协议,有阻塞rect udp,不可靠的,无线连接的服务 这里因为不需要阻塞,所以速度会很快,但安全性不高 2.关于客户端退出而服务器未退出的解决办法 ...
- Graph Embedding Review:Graph Neural Network(GNN)综述
作者简介: 吴天龙 香侬科技researcher 公众号(suanfarensheng) 导言 图(graph)是一个非常常用的数据结构,现实世界中很多很多任务可以描述为图问题,比如社交网络,蛋白体 ...
- haproxy是什么以及作用?
HAProxy 是一款提供高可用性.负载均衡以及基于TCP(第四层)和HTTP(第七层)应用的代理软件,支持虚拟主机,它是免费.快速并且可靠的一种解决方案. HAProxy特别适用于那些负载特大的we ...
- elasticsearch入门及安装
参考教程 elasticsearch入门教程:https://www.yiibai.com/elasticsearch/elasticsearch-getting-start.html Java JD ...
- Django2.2 Vue 前后端分离 无法访问Cookie
个人验证后可用配置如下: 环境: - Django 2.2 - djangorestframework 3.9 - django-cors-headers 2.5.3 INSTALLED_APPS = ...
- [NOIP2015]运输计划 线段树or差分二分
目录 [NOIP2015]运输计划 链接 思路1 暴力数据结构 思路2 二分树上差分 总的 代码1 代码2 [NOIP2015]运输计划 链接 luogu 好久没写博客了,水一篇波. 思路1 暴力数据 ...
- 修改hadoop/hbase/spark的pid文件位置
1.说明 当不修改PID文件位置时,系统默认会把PID文件生成到/tmp目录下,但是/tmp目录在一段时间后会被删除,所以以后当我们停止HADOOP/HBASE/SPARK时,会发现无法停止相应的进程 ...