HDFS集群中DataNode的上线与下线
在HDFS集群的运维过程中,肯定会遇到DataNode的新增和删除,即上线与下线。这篇文章就详细讲解下DataNode的上线和下线的过程。
背景
在我们的微职位视频课程中,我们已经安装了3个节点的HDFS集群,master机器上安装了NameNode和SecondaryNameNode角色,slave1和slave2两台机器上分别都安装了DataNode角色。
我们现在来给这个HDFS集群新增一个DataNode,这个DataNode是安装在master机器上
我们需要说明的是:在实际环境中,NameNode和DataNode最好是不在一台机器上的,我们这里都放在master上,是因为我们的虚拟机资源有限。
我们现在启动master、slave1和slave2三台虚拟机,然后启动HDFS集群,我们在HDFS的Web UI上可以看到有两个DataNode:

DataNode上线
在NameNode所在的机器(master)上的配置文件hdfs-site.xml中增加"白名单"配置:
<property>
<!-- 白名单信息-->
<name>dfs.hosts</name>
<value>/home/hadoop-twq/bigdata/hadoop-2.7.5/etc/hadoop/dfs.include</value>
</property>
在master机器上执行下面的命令:
## 创建白名单文件
touch /home/hadoop-twq/bigdata/hadoop-2.7.5/etc/hadoop/dfs.include
在/home/hadoop-twq/bigdata/hadoop-2.7.5/etc/hadoop/dfs.include文件中增加如下内容:
slave1其中,上面的
slave2
mastermaster是新增的DataNode所在的机器
在/home/hadoop-twq/bigdata/hadoop-2.7.5/etc/hadoop/slaves文件中新增:
master
3.然后在NameNode所在的机器(master)上执行如下的命令:
hdfs dfsadmin -refreshNodes
然后,我们在HDFS的Web UI上查看DataNode的信息:

可以看出,多了一个状态为Dead的DataNode
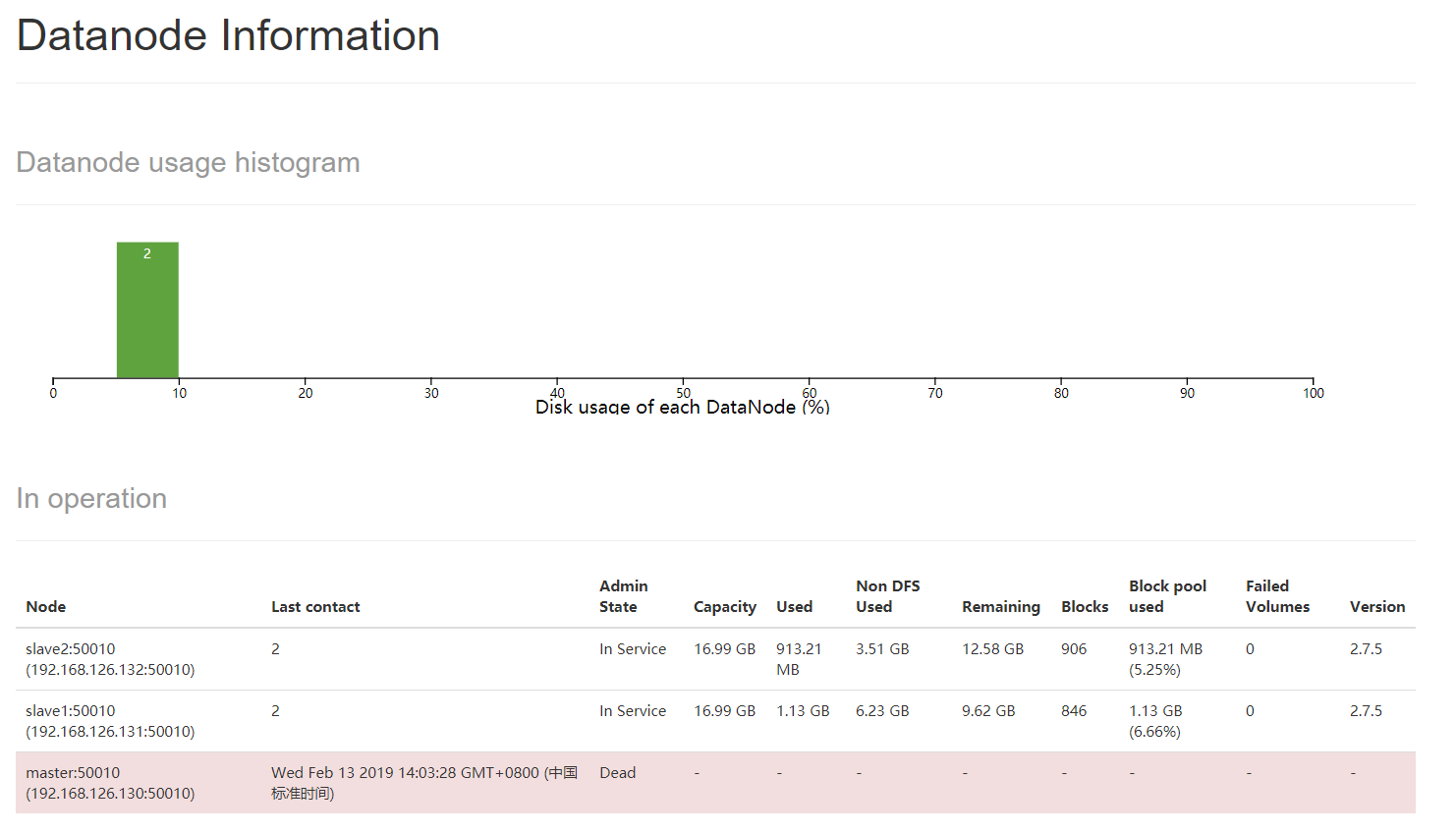
可以看出,多了一个状态为Dead的DataNode
4.在master机器上启动DataNode:
hadoop-daemon.sh start datanode
然后我们刷新HDFS的Web UI的DataNode信息,如下图:

可以看出,DataNode现在是3个了,master上的DataNode已经启动起来,并且加入集群中
DataNode的下线
我们现在下线master上的DataNode,步骤如下:
- 在NameNode所在的机器(master)上的配置文件hdfs-site.xml中增加"黑名单"配置:
<property>
<!-- 黑名单信息-->
<name>dfs.hosts.exclude</name>
<value>/home/hadoop-twq/bigdata/hadoop-2.7.5/etc/hadoop/dfs.exclude</value>
</property>
在master机器上执行下面的命令:
## 创建黑名单文件
touch /home/hadoop-twq/bigdata/hadoop-2.7.5/etc/hadoop/dfs.exclude
在/home/hadoop-twq/bigdata/hadoop-2.7.5/etc/hadoop/dfs.exclude文件中增加如下内容:
master
其中,上面的master是需要下线的DataNode所在的机器
在/home/hadoop-twq/bigdata/hadoop-2.7.5/etc/hadoop/slaves文件中删除master行
然后在NameNode所在的机器(master)上执行如下的命令:
hdfs dfsadmin -refreshNodes
然后我们刷新HDFS的Web UI的DataNode信息,如下图:

这个时候,master上的DataNode的状态变为Decommission In Progress。这个时候,在master上的DataNode的数据都在复制转移到其他的DataNode上,当数据转移完后,我们再刷新HDFS Web UI后,可以看到DataNode的状态变为Decommissioned,表示这个DataNode已经下线,如下图:

4. 在master上停止DataNode:
hadoop-daemon.sh stop datanode
5.刷新DataNode:
hdfs dfsadmin -refreshNodes
HDFS集群中DataNode的上线与下线的更多相关文章
- Hadoop(八)Java程序访问HDFS集群中数据块与查看文件系统
前言 我们知道HDFS集群中,所有的文件都是存放在DN的数据块中的.那我们该怎么去查看数据块的相关属性的呢?这就是我今天分享的内容了 一.HDFS中数据块概述 1.1.HDFS集群中数据块存放位置 我 ...
- 在Hadoop集群中添加机器和删除机器
本文转自:http://www.cnblogs.com/gpcuster/archive/2011/04/12/2013411.html 无论是在Hadoop集群中添加机器和删除机器,都无需停机,整个 ...
- Hadoop(五)搭建Hadoop与Java访问HDFS集群
前言 上一篇详细介绍了HDFS集群,还有操作HDFS集群的一些命令,常用的命令: hdfs dfs -ls xxx hdfs dfs -mkdir -p /xxx/xxx hdfs dfs -cat ...
- Hadoop(五)搭建Hadoop客户端与Java访问HDFS集群
阅读目录(Content) 一.Hadoop客户端配置 二.Java访问HDFS集群 2.1.HDFS的Java访问接口 2.2.Java访问HDFS主要编程步骤 2.3.使用FileSystem A ...
- Hadoop基础-HDFS集群中大数据开发常用的命令总结
Hadoop基础-HDFS集群中大数据开发常用的命令总结 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本盘博客仅仅列出了我们在实际生成环境中常用的hdfs命令,如果想要了解更多, ...
- Hadoop学习之路(十二)分布式集群中HDFS系统的各种角色
NameNode 学习目标 理解 namenode 的工作机制尤其是元数据管理机制,以增强对 HDFS 工作原理的 理解,及培养 hadoop 集群运营中“性能调优”.“namenode”故障问题的分 ...
- Hadoop(五)分布式集群中HDFS系统的各种角色
NameNode 学习目标 理解 namenode 的工作机制尤其是元数据管理机制,以增强对 HDFS 工作原理的 理解,及培养 hadoop 集群运营中“性能调优”.“namenode”故障问题的分 ...
- hadoop集群中动态添加新的DataNode节点
集群中现有的计算能力不足,须要另外加入新的节点时,使用例如以下方法就能动态添加新的节点: 1.在新的节点上安装hadoop程序,一定要控制好版本号,能够从集群上其它机器cp一份改动也行 2.把name ...
- vivo 万台规模 HDFS 集群升级 HDFS 3.x 实践
vivo 互联网大数据团队-Lv Jia Hadoop 3.x的第一个稳定版本在2017年底就已经发布了,有很多重大的改进. 在HDFS方面,支持了Erasure Coding.More than 2 ...
随机推荐
- php_mvc实现步骤三,四
3.match_mvc MVC 以ecshop的前台为例: 功能一: 首页 购物车数据,商品分类数据,其他的首页需要的数据 功能二: 拍卖活动 购物车数据,商品分类数据,拍卖相关数据 功能三: 团购商 ...
- Mechanical Simulation借助UE发力自动驾驶仿真
Source https://www.unrealengine.com/en-US/blog/making-autonomous-vehicles-safer-before-they-hit-the- ...
- PHP 批量删除的实现
布局效果 布局代码 <button type="button" class="btn btn-sm btn-danger btn-erbi-danger" ...
- 【转帖】处理器史话 | 当Power架构的发展之路遭遇“滑铁卢”
处理器史话 | 当Power架构的发展之路遭遇“滑铁卢” https://www.eefocus.com/mcu-dsp/366740 (8)Power8:决定了 Power 平台的未来发展 2014 ...
- win10 远程连接怎么设置快捷方式
在桌面空白处右键,选择新建快捷方式,然后输入命令:C:\windows\system32\mstsc.exe,点击下一步,然后输入快捷方式名称:远程连接,点击确定即可.
- 遇到了NameError: name ‘name’ is not defined 这样的错误。
改正:__name__ == "__main__" name的左右两边各有两条下划线,不是左右两边各有一条
- Go语言( 函数)
函数是组织好的.可重复使用的.用于执行指定任务的代码块.本文介绍了Go语言中函数的相关内容. 函数 Go语言中支持函数.匿名函数和闭包,并且函数在Go语言中属于“一等公民”. 函数定义 Go语言中定义 ...
- L2R 二:常用评价指标之AUC
零零散散写了一些,主要是占个坑: AUC作为一个常用的评价指标,无论是作为最后模型效果评价还是前期的特征选择,都发挥着不可替代的作用,下面我们详细介绍下这个指标. 1.定义 2.实现 # coding ...
- Codeforces Round #568 Div. 2
没有找到这场div3被改成div2的理由. A:签到. #include<bits/stdc++.h> using namespace std; #define ll long long ...
- 查看线程CPU利用率
查看线程CPU利用率 方法1:利用ps命令查看对应的线程 1. ps -ef | grep 进程名称 2. ps -mp 进程ID -o THREAD,pid,tid,cmd,time,%cpu,%m ...