词向量---ELMO
1.ELMo(Embeddings from Language Models )
RNN-based language models(trained from lots of sentences)

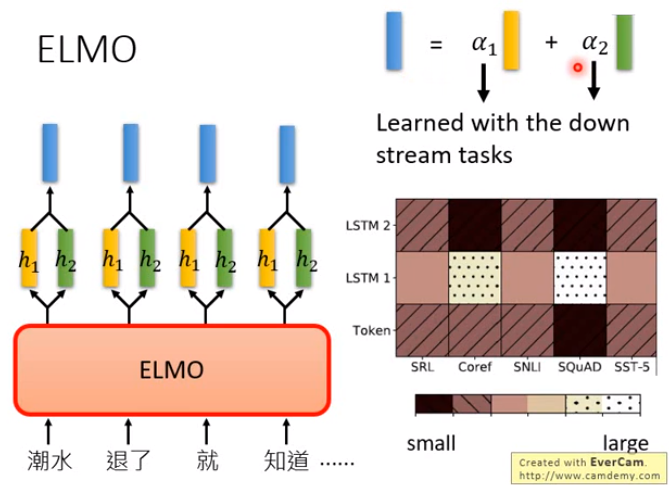
ELMo 词向量是由双向神经网络语言模型的内部多层向量的线性加权组成。
LSTM 高层状态向量捕获了上下文相关的语义信息,可以用于语义消岐等任务。 结果表明:越高层的状态向量,越能够捕获语义信息。
LSTM 底层状态向量捕获了语法信息,可以用于词性标注等任务。结果表明:越低层的状态向量,越能够捕获语法信息。
ELMo 词向量与传统的词向量(如:word2vec )不同。在ELMo 中每个单词的词向量不再是固定的,而是单词所在的句子的函数,由单词所在的上下文决定。因此ELMo 词向量可以解决多义词问题。
2.原理
给定一个句子:$\{word_{w1},...,word_{W_N}\}$,其中$w_i$属于$\{1,2,...,V\}$,N为句子的长度,用$(w_1,...,w_N)$表示该句子,则生成该句子的概率为:
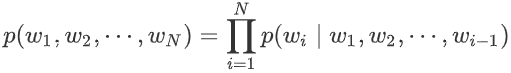
可以用一个L层的前向 LSTM 模型来实现该概率。其中:
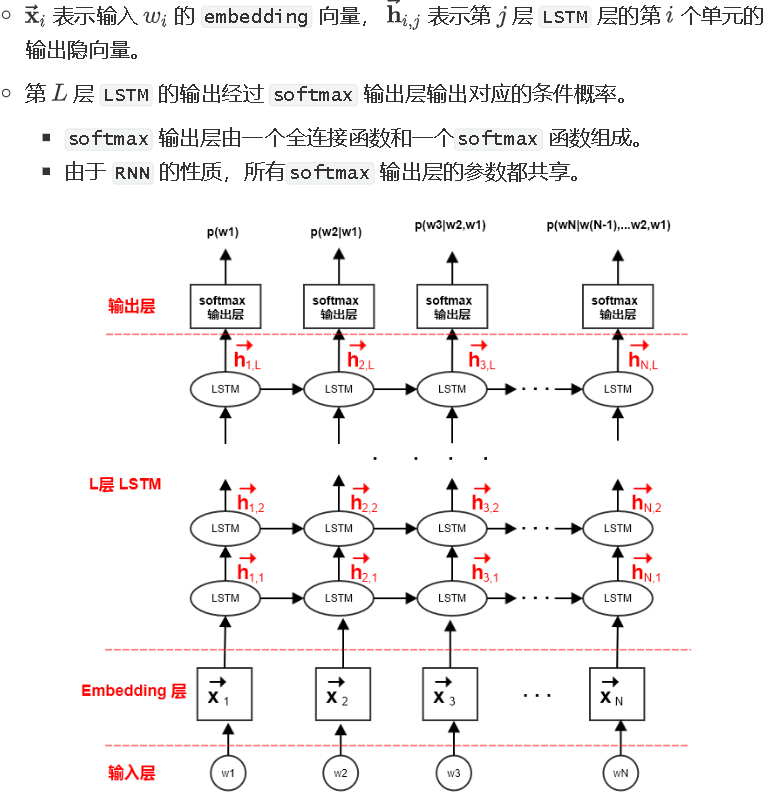
ELMo 模型采用双向神经网络语言模型,它由一个前向LSTM 网络和一个逆向 LSTM 网络组成。ELMo 最大化句子的对数前向生成概率和对数逆向生成概率。
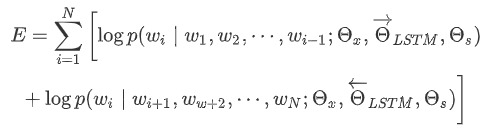

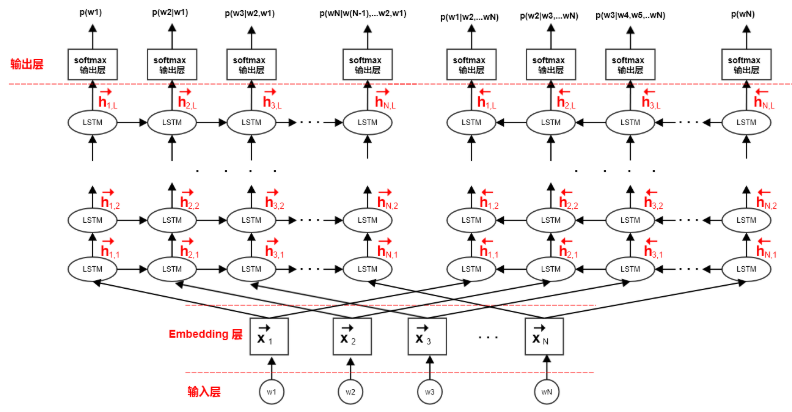
3.应用
首先训练无监督的 ELMo 模型,获取每个单词的2L+1个中间表示。然后在监督学习任务中,训练这2L+1个向量的线性组合,方法为:

实验表明:在 ELMo 中添加 dropout 是有增益的。另外在损失函数中添加正则化能使得训练到的ELMo权重倾向于接近所有ELMo权重的均值。
参考文献:
【1】李宏毅机器学习2019(国语)_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
词向量---ELMO的更多相关文章
- 第一节——词向量与ELmo(转)
最近在家听贪心学院的NLP直播课.都是比较基础的内容.放到博客上作为NLP 课程的简单的梳理. 本节课程主要讲解的是词向量和Elmo.核心是Elmo,词向量是基础知识点. Elmo 是2018年提出的 ...
- NLP直播-1 词向量与ELMo模型
翻车2次,试水2次,今天在B站终于成功直播了. 人气11万. 主要讲了语言模型.词向量的训练.ELMo模型(深度.双向的LSTM模型) 预训练与词向量 词向量的常见训练方法 深度学习与层次表示 LST ...
- NLP获取词向量的方法(Glove、n-gram、word2vec、fastText、ELMo 对比分析)
自然语言处理的第一步就是获取词向量,获取词向量的方法总体可以分为两种两种,一个是基于统计方法的,一种是基于语言模型的. 1 Glove - 基于统计方法 Glove是一个典型的基于统计的获取词向量的方 ...
- Word Representations 词向量
常用的词向量方法word2vec. 一.Word2vec 1.参考资料: 1.1) 总览 https://zhuanlan.zhihu.com/p/26306795 1.2) 基础篇: 深度学习wo ...
- 文本分类实战(一)—— word2vec预训练词向量
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- NLP之词向量
1.对词用独热编码进行表示的缺点 向量的维度会随着句子中词的类型的增大而增大,最后可能会造成维度灾难2.任意两个词之间都是孤立的,仅仅将词符号化,不包含任何语义信息,根本无法表示出在语义层面上词与词之 ...
- [Algorithm & NLP] 文本深度表示模型——word2vec&doc2vec词向量模型
深度学习掀开了机器学习的新篇章,目前深度学习应用于图像和语音已经产生了突破性的研究进展.深度学习一直被人们推崇为一种类似于人脑结构的人工智能算法,那为什么深度学习在语义分析领域仍然没有实质性的进展呢? ...
- 开源共享一个训练好的中文词向量(语料是维基百科的内容,大概1G多一点)
使用gensim的word2vec训练了一个词向量. 语料是1G多的维基百科,感觉词向量的质量还不错,共享出来,希望对大家有用. 下载地址是: http://pan.baidu.com/s/1boPm ...
- Deep Learning In NLP 神经网络与词向量
0. 词向量是什么 自然语言理解的问题要转化为机器学习的问题,第一步肯定是要找一种方法把这些符号数学化. NLP 中最直观,也是到目前为止最常用的词表示方法是 One-hot Representati ...
随机推荐
- Newcoder 小白月赛20 H 好点
Newcoder 小白月赛20 H 好点 自我感觉不错然后就拿出来了. 读读题之后我们会发现这是让我们求一堆数,然后这些数一定是递减的. 就像这样我们选的就是框起来的,然后我们可以看出来这一定是一个单 ...
- 网络1911、1912 C语言第5次作业--循环结构 批改总结
如题 一.评分规则 1.伪代码务必是文字+代码描述,直接反应代码,每题扣1分 2.提交列表没内容,或者太简单,每题得分0分.注意选择提交列表长的题目介绍. 3.代码格式不规范,包括命名随意.继续扣分. ...
- 4.Python项目实战
这里会每个周更新一个Python的大练习,作为 实战项目... elk
- 关于Windows自动化卸载软件的思路
思路 关于控制面板“卸载”关联到的exe是这样的: 注册表:HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\Uninstall ...
- 使用go-mysql-elasticsearch同步mysql数据库信息到ElasticSearch
本文介绍如何使用go-mysql-elasticsearch同步mysql数据库信息到ElasticSearch. 1.go-mysql-elasticsearch简介 go-mysql-elasti ...
- 在 Queue 中 poll()和 remove()有什么区别?
remove() ,如果队列为空的时候,则会抛出异常 而poll()只会返回null
- 分布式数据库缓存系统Apache Ignite
Apache Ignite内存数据组织是高性能的.集成化的以及分布式的内存平台,他可以实时地在大数据集中执行事务和计算,和传统的基于磁盘或者闪存的技术相比,性能有数量级的提升. 将数据存储在缓存中能够 ...
- 向github项目push代码后,Jenkins实现其自动构建
配置Jenkins(添加Github服务器) 1.进入[系统管理] --> [系统设置] ,找到[Github] 2.添加Github服务器 这里需要github提供一个密钥文本,我们去gith ...
- scala中val和var的区别
1:内容是否可变:val修饰的是不可变的,var修饰是可变的 2:val修饰的变量在编译后类似于java中的中的变量被final修饰 3:lazy修饰符可以修饰变量,但是这个变量必须是val修饰的 p ...
- Prometheus 安装Alertmanager集成
Prometheus 安装Alertmanager集成 # 下载地址 地址1:https://prometheus.io/download/ 地址2:https://github.com/promet ...