rabbitmq在linux下单节点部署和基本使用
RabbitMQ是基于erlang开发的消息服务,官网为:https://www.rabbitmq.com,RabbitMQ要依赖erlang运行,所以要先安装erlang环境,rabbitmq可以用rpm或通用二进制包安装,这里使用二进制包的方式安装,版本为3.8.1,对应的erlang版本为22.1,注意版本的对应关系,如果相差太大可能会无法启动服务,rabbit和erlang的版本对应关系参考:https://www.rabbitmq.com/which-erlang.html
首先安装erlang,在centos下使用yum安装的erlang版本太低,rabbitmq无法启动,这里使用编译源码的方式安装,参考文档为:https://github.com/erlang/otp/blob/maint/HOWTO/INSTALL.md,文档写的很详细,erlang包下载地址:https://www.erlang.org/downloads,这里下载的包为:otp_src_22.1.tar.gz,安装之前注意下面的一些必要环境:
1. GNU make,这个一般机器都有
2. gcc编译环境,这里用的4.8版本
3. Perl 5,默认是5.16
4. ncurses-devel开发包,安装命令: yum install ncurses-devel
5. sed命令,几乎所有linux系统都有
6. openssl开发包,版本要大于0.9.8,安装命令: yum install openssl-devel
基本上上面这些就够了,其他的都是一些附加的扩展或者编译文档用到的,具体组件参考上面的安装链接页面
执行下面的命令解压erlang源码:
tar -xvzf otp_src_22..tar.gz
cd otp_src_22./
export ERL_TOP=`pwd`
开始编译源码,安装目录设置为:/usr/local/erlang
./configure --prefix=/usr/local/erlang
make
make install
现在erlang就安装到/usr/local/erlang了,这时候要配置环境变量方便直接调用erl命令,导入变量命令: export PATH=$PATH:/usr/local/erlang/bin ,可以将这条指令添加到profile配置文件然后source永久生效,添加变量后执行erl如果正常进入提示符说明环境可以了:
然后下一步开始安装rabbitmq,这里安装包的名称为:rabbitmq-server-generic-unix-3.8.1.tar.xz,需要先用xz命令进行解压:
xz -d rabbitmq-server-generic-unix-3.8..tar.xz
tar -xvf rabbitmq-server-generic-unix-3.8..tar
执行之后当前目录下会解压出来rabbitmq_server-3.8.1这个目录,直接移动到安装的位置即可,比如: mv rabbitmq_server-3.8. /usr/local 将rabbitmq安装到/usr/local/下,在rabbitmq服务启动前可以手动去调整系统最大文件数等参数来优化mq的性能,具体参考:https://www.rabbitmq.com/install-generic-unix.html,同样为了方便可以将/usr/local/rabbitmq_server-3.8.1/sbin目录添加到环境变量
其实现在已经可以启动服务了,目前参数都是默认的,要配置自定义参数还缺少一个配置文件,这里配置文件默认位置为:/usr/local/rabbitmq_server-3.8.1/etc/rabbitmq/rabbitmq.conf,这个文件不存在需要手动创建,具体的配置示例参考:https://github.com/rabbitmq/rabbitmq-server/blob/master/docs/rabbitmq.conf.example,现在可以将配示例全部复制到新建的配置文件中,也就是安装目录下的etc/rabbitmq/rabbitmq.conf,比如端口号默认是5672,我们可以修改为5682,配置项为:listeners.tcp.default,如下:

更多配置参考:https://www.rabbitmq.com/configure.html,然后可以启动rabbitmq服务了,命令如下:
前台启动: ./sbin/rabbitmq-server
后台启动: ./sbin/rabbitmq-server -detached
停止服务: sbin/rabbitmqctl shutdown
启动服务之后可以测试一下消息队列方式是不是好用,这是使用python pika模块,生产消息代码如下:new_task.py
#!/usr/bin/env python
import pika
import sys connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost', port=5682))
channel = connection.channel() channel.queue_declare(queue='task_queue', durable=True) for i in range(100):
message = '%d. Hello!' % i
channel.basic_publish(
exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
))
print("Queue sent %r" % message)
connection.close()
消费消息代码如下:worker.py
#!/usr/bin/env python
import pika
import time connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost',port=5682))
channel = connection.channel() channel.queue_declare(queue='task_queue', durable=True)
print(' [*] Waiting for messages. To exit press CTRL+C') def callback(ch, method, properties, body):
print("Received %r" % body)
#time.sleep(body.count(b'.'))
#print("Done")
ch.basic_ack(delivery_tag=method.delivery_tag) channel.basic_qos(prefetch_count=1)
channel.basic_consume(queue='task_queue', on_message_callback=callback)
channel.start_consuming()
这两段代码就是官网上给出的work queues示例代码,首先启动消费的脚本,这里开两个窗口分别执行python3 worker.py,启动后应该是阻塞的,然后再启动生产消息的脚本python3 new_task.py,我这里用的是python3,具体根据自己的环境执行,执行后如果生产消息正常退出并且两个worker分别输出不一样序号的消息,也就是说生产的消息被分割到两个进程处理,每个进程消费到数据都不重复,这样的话说明测试通过,服务是正常的
实际上rabbitmq支持5种不同的消息模型,可以根据不同的场景来应用,这几种消息模型如下:
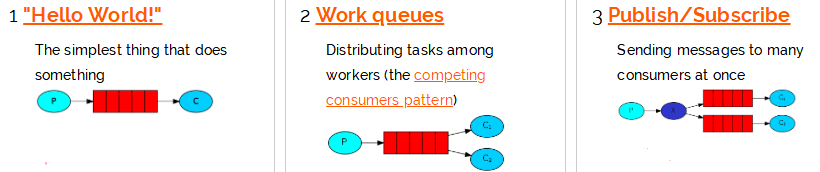
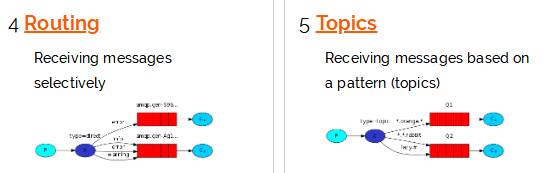
这里只是简单叙述了rabbitmq非常初级的应用,更深入的后续再补充.
rabbitmq在linux下单节点部署和基本使用的更多相关文章
- RabbitMQ镜像模式双节点部署时故障转移过程中队列中消息的状态
场景 现有节点Node1和Node2,建立Exchange:yu.exchange,创建队列yu1.queue镜像队列master位于Node1,yu2.queue镜像队列位于Node2,使用topi ...
- linux下单节点oracle数据库间ogg搭建
环境说明: linux为Linux 2.6.32-573.el6.x86_64 oracle为 11g Enterprise Edition Release 11.2.0.1.0 - 64 ...
- Linux 安装 RabbitMQ 3.7.8 安装部署
Linux 安装 rabbitmq 3.7.8 安装部署 安装 ncurses 1.安装GCC GCC-C++ Openssl等模块 yum -y install make gcc gcc-c++ k ...
- Openstack 网络服务 Neutron介绍和控制节点部署 (九)
Neutron介绍 neutron是openstack重要组件之一,在以前是时候没有neutron项目. 早期的时候是没有neutron,早期所使用的网络的nova-network,经过版本改变才有个 ...
- OpenStack IceHouse 部署 - 5 - 网络节点部署
Neutron网络服务(网络节点) 目录 [隐藏] 1 参考 2 前置工作 2.1 调整内核参数 3 安装 4 配置 4.1 keystone对接 4.2 rabbitmq对接 4.3 me ...
- OpenStack IceHouse 部署 - 3 - 控制节点部署
Mysql部署配置 安装 安装mysql,mysql的python绑定 apt-get install mysql-server 安装过程中会要求设定mysql的root账户的密码,这里假定设为my ...
- Linux集群部署自定义时间同步服务器(ntpd)
Linux集群部署自定义时间同步服务器(ntpd) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 身为一名运维人员,在搭建集群的时候,第一步需要做的就是同步每个机器的时间,尤其是在 ...
- Openstack 网络服务 Neutron计算节点部署(十)
Neutron计算节点部署 安装组件,安装的服务器是192.168.137.12 1.安装软件包 yum install -y openstack-neutron-linuxbridge ebtabl ...
- OpenStack 计算服务 Nova介绍和控制节点部署(七)
介绍 Nova是openstack最早的两块模块之一,另一个是对象存储swift.在openstack体系中一个叫做计算节点,一个叫做控制节点.这个主要和nova相关,我们把安装为计算节点nova-c ...
随机推荐
- python爬虫爬取天气数据并图形化显示
前言 使用python进行网页数据的爬取现在已经很常见了,而对天气数据的爬取更是入门级的新手操作,很多人学习爬虫都从天气开始,本文便是介绍了从中国天气网爬取天气数据,能够实现输入想要查询的城市,返回该 ...
- VMware虚拟机文件夹中各文件作用详解
虚拟机的文件管理由VMware Workstation来执行 一个虚拟机一般以一系列文件的形式储存在宿主机中,这些文件一般在由workstation为虚拟机所创建的那个目录中 这里列出了这些关键文件及 ...
- Ubuntu下映射网络驱动器
Ubuntu下映射网络驱动器https://www.linuxidc.com/Linux/2013-07/86928.htm linux下samba访问路径: smb://192.168.1.111/ ...
- 【异常】Caused by: java.sql.SQLTransientConnectionException: HikariPool-1 - Connection is not available, request timed out after 30005ms.
一.异常出现的场景 一次线上订单历史数据字段刷新操作,3张表100多万数据.由于同步更新太慢大概20分钟以上,所以采用异不的方式.代码如下: private void batchUpdate(List ...
- 【Spring Cloud】Spring Cloud之整合Spring Cloud Bus以及最佳实践
一.整合步骤 1)加入Maven坐标 <!-- actuator监控模块 --> <dependency> <groupId>org.springframework ...
- 使用jmeter 设计流程发起测试
业务场景 需要实现用户在登录后,能够持续的发起流程. 需要注意的点: 1.使用不同的用户登录. 2.登录后发起可以持续的发起流程. 实现步骤 1.先使用badboy 录制脚本. 2.使用jmeter ...
- HashMap中的putIfAbsent使用示例
原文:https://blog.csdn.net/k3108001263/article/details/83720445 如果不存在key,则添加到HashMap中,跟put方法相似 如果存在key ...
- 性能测试基础---测试流程,LR安装
·性能测试流程详解: 一般来说,性能测试通常可以分为以下过程: ·前期分析.测试计划.测试方案.测试环境的搭建.测试数据的准备.测试脚本的开发.测试场景的设计.测试场景的实现和执行.资源的监控.分析结 ...
- param动作
param动作通常与forword一起使用 <jsp:forword page="目标页面" > <jsp:param value="参数值" ...
- Colorful events