Python处理数据集-1
原数据集的数据格式:
每行为:(test_User, test_Item) negativeItem1 negativeItem2 negativeItem3 …… negativeItem99
即每一行对应一个user 与100个item,其中1个item为正例,其余99个为负例。

将要处理成的目标数据的数据格式为:
将1个正例与99个负例拼在一起,也就是每行数据为100个item的list。(User的 ID默认从0 开始~)
【解决方案】
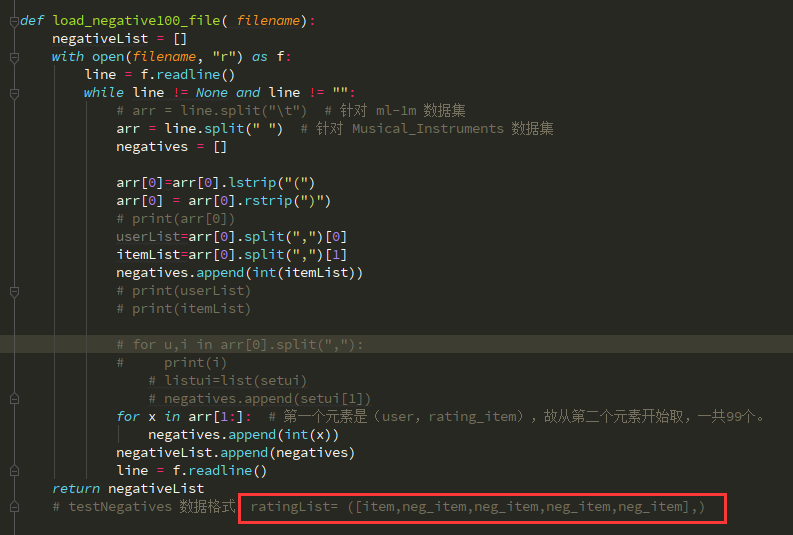
def load_negative100_file( filename):
negativeList = []
with open(filename, "r") as f:
line = f.readline()
while line != None and line != "":
# arr = line.split("\t") # 针对 ml-1m 数据集
arr = line.split(" ") # 针对 Musical_Instruments 数据集
negatives = [] arr[0]=arr[0].lstrip("(")
arr[0] = arr[0].rstrip(")")
# print(arr[0])
userList=arr[0].split(",")[0]
itemList=arr[0].split(",")[1]
negatives.append(int(itemList))
# print(userList)
# print(itemList) # for u,i in arr[0].split(","):
# print(i)
# listui=list(setui)
# negatives.append(setui[1])
for x in arr[1:]: # 第一个元素是(user,rating_item),故从第二个元素开始取,一共99个。
negatives.append(int(x))
negativeList.append(negatives)
line = f.readline()
return negativeList
# testNegatives 数据格式:ratingList= ([item,neg_item,neg_item,neg_item,neg_item],)
如下:
Python处理数据集-1的更多相关文章
- 使用python划分数据集
无论是训练机器学习或是深度学习,第一步当然是先划分数据集啦,今天小白整理了一些划分数据集的方法,希望大佬们多多指教啊,嘻嘻~ 首先看一下数据集的样子,flower_data文件夹下有四个文件夹,每个文 ...
- KNN手写实践:Python基于数据集整体计算以及排序
1. 距离计算,不要通过遍历每个样本来计算和指定样本距离,而是通过对于指定样本进行广播(复制)成为一个shape和全局一致后,再进行整体计算,这里的广播 / 复制采用的是tile函数来实现的: 2. ...
- Python处理数据集-2
原数据集的数据格式: 每行为:(test_User, test_Item) negativeItem1 negativeItem2 negativeItem3 …… negativeItem99 即每 ...
- python 鸢尾花数据集报表展示
import seaborn as snsimport pandas as pdimport matplotlib.pyplot as pltsns.set_style('white',{'font. ...
- 【转】XGBoost参数调优完全指南(附Python代码)
xgboost入门非常经典的材料,虽然读起来比较吃力,但是会有很大的帮助: 英文原文链接:https://www.analyticsvidhya.com/blog/2016/03/complete-g ...
- COCO 数据集的使用
Windows 10 编译 Pycocotools 踩坑记 COCO数据库简介 微软发布的COCO数据库, 除了图片以外还提供物体检测, 分割(segmentation)和对图像的语义文本描述信息. ...
- Python实现机器学习算法:AdaBoost算法
Python程序 ''' 数据集:Mnist 训练集数量:60000(实际使用:10000) 测试集数量:10000(实际使用:1000) 层数:40 ------------------------ ...
- 深度残差网(deep residual networks)的训练过程
这里介绍一种深度残差网(deep residual networks)的训练过程: 1.通过下面的地址下载基于python的训练代码: https://github.com/dnlcrl/deep-r ...
- XGBoost参数调优完全指南
简介 如果你的预测模型表现得有些不尽如人意,那就用XGBoost吧.XGBoost算法现在已经成为很多数据工程师的重要武器.它是一种十分精致的算法,可以处理各种不规则的数据.构造一个使用XGBoost ...
随机推荐
- WPF-数据模板深入(加载XML类型数据)
一.我们知道WPF数据模板是当我们给定一个数据类型,我们为这个数据类型写好布局,就给这种数据类型穿上了外衣. 下面这个例子,能够帮助大家充分理解数据模板就是数据类型的外衣的意思:(里面的MyListB ...
- webservice因引用Oracle.DataAccess.dll导致发布前预编译不通过
这个问题最初是什么问题已经忘了,虽然就在几小时前/
- 批处理(bat)的一些记录
总览:https://www.jb51.net/article/151923.htm 如何判断空格与回车的输入:https://www.lmdouble.com//113311107.html 设置命 ...
- SSH开发模式——Struts2进阶
在之前我有写过关于struts2框架的博客,好像是写了三篇,但是之前写的内容仅仅是struts2的一些基础知识而已,struts2还有很多有趣的内容等待着我们去发掘.我准备再写几篇关于struts2的 ...
- AI人脸识别的测试重点
最常见的 AI应用就是人脸识别,因此这篇文章从人脸识别的架构和核心上,来讲讲测试的重点. 测试之前需要先了解人脸识别的整个流程,红色标识代表的是对应AI架构中的各个阶段 首先是人脸采集. 安装拍照摄像 ...
- Microsoft Surface 2019新品发布会汇总
Microsoft Surface 2019 新品发布会汇总 10月2日晚,微软举行了Microsoft Surface 2019秋季新品发布会,本次发布会涉及如下设备内容等: SurfaceLapt ...
- Missing write access to /usr/local/lib/node_modules npm ERR! path /usr/local/lib/node_modules
今天用npm下载yarn,出现Missing write access to /usr/local/lib/node_modules npm ERR! path /usr/local/lib/node ...
- 201871010121 王方 《面向对象程序设计(Java)》第6-7周学习总结
项目 内容 这个作业属于哪个课程 https://www.cnblogs.com/nwnu-daizh/ 这个作业的要求在哪里 https://www.cnblogs.com/nwnu-daizh/p ...
- Sharding-JDBC 学习资料
学习资料 网站 官网 https://shardingsphere.apache.org/document/current/cn/manual/sharding-jdbc/ 基于 Docker 的 M ...
- VC 静态库与动态库(四)动态库创建与使用_显示调用
在第三章的基础上,接着添加一个显示调用项目 显示调用项目创建: 1.给解决方案添加一个新的控制台项目DisplayCall用于测试动态库,创建完成后设置为启动项目 2.DisplayCall.cpp添 ...