spark-2.1.1 yarn(高可用)搭建
一、概述
spark分布式搭建方式大致分为三种:standalone、yarn、mesos。三种分类的区别这里就不一一介绍了,不明白可自行了解。standalone是官方提供的一种集群方式,企业一般不使用。yarn集群方式在企业中应用是比较广泛的,这里也是介绍yarn的集群安装方式。mesos安装适合于超大型集群。
集群节点分配:
hadoop01:Zookeeper、NameNode(active)、ResourceManager(active)
hadoop02:Zookeeper、NameNode(standby)
hadoop03:Zookeeper、 ResourceManager(standby)
hadoop04: DataNode、 NodeManager、 JournalNode、 spark
hadoop05: DataNode、 NodeManager、 JournalNode、 spark
hadoop06: DataNode、 NodeManager、 JournalNode、 spark
二、安装
说明一下:
①选spark的时候要注意与hadoop版本对应。因为hadoop用的是2.7的,所以spark选的是spark-2.1.1-bin-hadoop2.7
②因为spark基于yarn来管理,spark只能安装在NodeManager节点上。
③spark安装放在/home/software目录下。
1、hadoop基于yarn(ha)的搭建,这里介绍步骤了。在我的上一个教程里有详细介绍。
2、安装scala,并配置好环境变量。
3、在NodeManager节点上解压spark文件。
tar -xvf spark-2.1.1-bin-hadoop2.7
3、修改spark-2.1.1-bin-hadoop2.7/conf/spark-env.sh,在文件尾部加上以下内容,其中HADOOP_CONF_DIR是必填项
export JAVA_HOME=/home/jack/jdk1.8.0_144
export SCALA_HOME=/home/jack/scala-2.12.3
export HADOOP_HOME=/home/software/hadoop-2.7.4
export HADOOP_CONF_DIR=/home/software/hadoop-2.7.4/etc/hadoop
export SPARK_MASTER_PORT=7077
export SPARK_EXECUTOR_CORES=2
export SPARK_EXECUTOR_MEMORY=1024m
export SPARK_EXECUTOR_INSTANCES=1
4、修改spark-2.1.1-bin-hadoop2.7/conf/slave文件,添加以下内容:
hadoop04
hadoop05
hadoop06
5、在hdfs上传spark的jar包,并修改/home/software/spark-2.1.1-bin-hadoop2.7/conf/spark-defaults.conf(可不做)
①hadoop fs -mkdir /spark_jars
②hadoop fs -put /home/software/spark-2.1.1-bin-hadoop2.7/jars/* /spark_jars
③修改/home/software/spark-2.1.1-bin-hadoop2.7/conf/spark-defaults.conf,添加以下内容:
spark.yarn.jars=hdfs://hadoop01:9000/spark_jars/*
6、完成以上操作就完成了spark基于yarn的安装。下面是验证部分:
在安装有spark的节点上执行以下命令:
spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 1 \
--num-executors 3 \
/home/software/spark-2.1.1-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.1.jar \
10
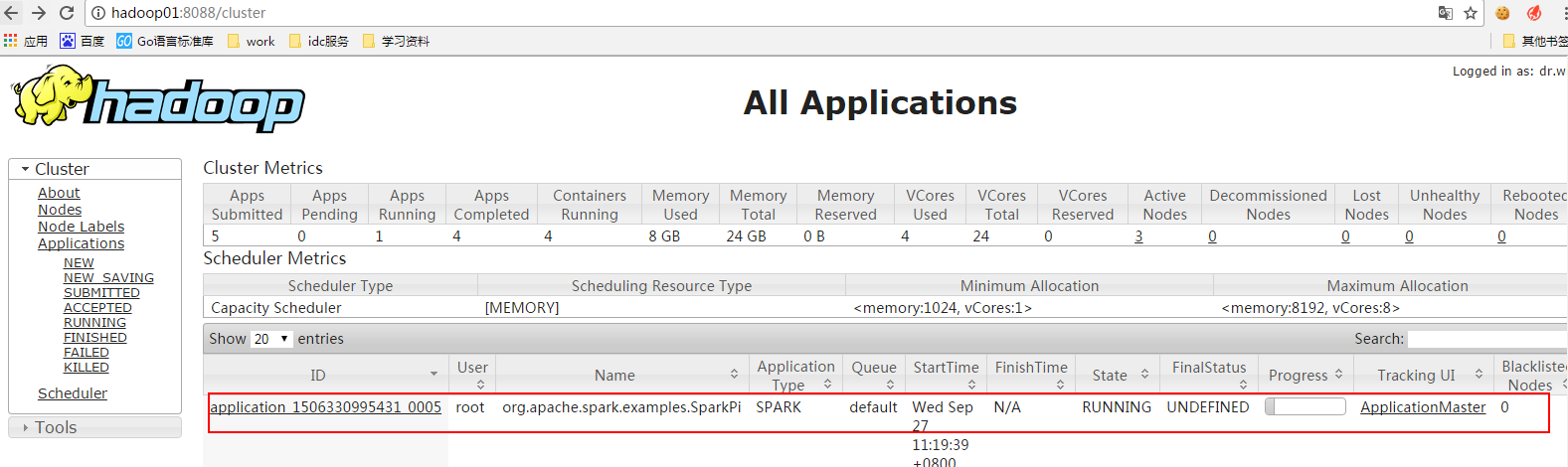
能看以上三张图就说明安装成功了!
备注:如果执行spark-shell --master yarn --deploy-mode client失败,报rpc连接失败,解决方法如下:
在hadoop的配置文件yarn-site.xml中加入:
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
报错的原因是:内存资源给的过小,yarn直接kill掉进程,则报rpc连接失败、ClosedChannelException等错误。
spark-2.1.1 yarn(高可用)搭建的更多相关文章
- hadoop2.6.0高可靠及yarn 高可靠搭建
以前用hadoop2.2.0只搭建了hadoop的高可用,但在hadoop2.2.0中始终没有完成YARN HA的搭建,直接下载了hadoop最新稳定版本2.6.0完成了YARN HA及HADOOP ...
- hadoop 集群HA高可用搭建以及问题解决方案
hadoop 集群HA高可用搭建 目录大纲 1. hadoop HA原理 2. hadoop HA特点 3. Zookeeper 配置 4. 安装Hadoop集群 5. Hadoop HA配置 搭建环 ...
- hadoop+zookeeper集群高可用搭建
hadoop+zookeeper集群高可用搭建 Senerity 发布于 2 ...
- 七、Hadoop3.3.1 HA 高可用集群QJM (基于Zookeeper,NameNode高可用+Yarn高可用)
目录 前文 Hadoop3.3.1 HA 高可用集群的搭建 QJM 的 NameNode HA Hadoop HA模式搭建(高可用) 1.集群规划 2.Zookeeper集群搭建: 3.修改Hadoo ...
- 10-Flink集群的高可用(搭建篇补充)
戳更多文章: 1-Flink入门 2-本地环境搭建&构建第一个Flink应用 3-DataSet API 4-DataSteam API 5-集群部署 6-分布式缓存 7-重启策略 8-Fli ...
- Hadoop入门学习笔记-第三天(Yarn高可用集群配置及计算案例)
什么是mapreduce 首先让我们来重温一下 hadoop 的四大组件:HDFS:分布式存储系统MapReduce:分布式计算系统YARN: hadoop 的资源调度系统Common: 以上三大组件 ...
- Qingcloud_MySQL Plus(Xenon) 高可用搭建实验
实验:Xenon on 5.7.30 Xenon (MySQL Plus) 是青云Qingcloud的一个开源项目,号称金融级别强一致性的高可用解决方案,项目地址为 https://github.co ...
- Spring Cloud(Dalston.SR5)--Eureka 注册中心高可用搭建
高可用集群 在微服务架构这样的分布式环境中,我们需要充分考虑发生故障的情况,所以在生产环境中必须对各个组件进行高可用部署,对与微服务和服务注册中心都需要高可用部署,Eureka 高可用实际上就是将自己 ...
- kudu集群高可用搭建
首先咱得有KUDU安装包 这里就不提供直接下载地址了(因为有5G,我 的服务器网卡只有4M,你们下的很慢) 这里使用的是CDH版本 官方下载地址http://archive.cloudera.com/ ...
随机推荐
- Visual Studio Code 折叠代码快捷键
为了快速阅读不熟悉的代码, 最好可以打开一个文件能先将具体实现折叠起来的,进行一个大概的认识,vscode中有这些折叠快捷键: ctrl+shift+[是折叠 ctrl+k ctrl+0 是折叠全部 ...
- Golang http post error : http: ContentLength=355 with Body length 0
参考:https://stackoverflow.com/questions/31337891/net-http-http-contentlength-222-with-body-length-0 问 ...
- Python --链接MYSQL数据库与简单操作 含SSH链接
项目是软硬件结合,在缺少设备的情况,需要通过接口来模拟实现与设备的交互,其中就需要通过从数据库读取商品的ID信息 出于安全考虑 现在很多数据库都不允许通过直接访问,大多数是通过SSH SSH : 数 ...
- 【MM系列】SAP 各种冲销凭证
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[MM系列]SAP 各种冲销凭证 前言部分 ...
- 【Unity Shader】---数据类型和关键字
一.基本数据类型:Cg支持7种基本的数据类型 1.float,32位浮点数据,一个符号位.浮点数据类型被所有的图形接口支持: 2.half,16位浮点数据: 3.int,32位整形数据 4,fixed ...
- CQRS框架(nodejs的DDD开发落地框架)初识感想
CQRS是啥?DDD又是啥? 这两个概念其实没什么神秘的,当然此文章中的这两个概念以曾老师的课程为准(关于CQRS和DDD的标准概念,google上已经很多了,不再赘述.) DDD(Domain Dr ...
- Vue切换页面时中断axios请求
一.概述 在Vue单页面开发过程中,遇到这样的情况,当我切换页面时,由于上一页面请求执行时间长,切换到该页面时,还未执行完,这时那个请求仍会继续执行直到请求结束,此时将会影响页面性能,并且可能对现在页 ...
- tableView优化方案
最近在微博上看到一个很好的开源项目VVeboTableViewDemo,是关于如何优化UITableView的.加上正好最近也在优化项目中的类似朋友圈功能这块,思考了很多关于UITableView的优 ...
- Apple Pay接入详细教程
Apple Pay接入详细教程 来源:Yasin的简书 链接:http://www.jianshu.com/p/738aee78ba52# Apple Pay运行环境:iPhone6以上设备,操作 ...
- MySQL事务提交与回滚
提交 为了演示效果,需要打开两个终端窗口,使用同一个数据库,操作同一张表 step1:连接 终端1:查询商品分类信息 select * from goods_cates; step2:增加数据 终端2 ...