Requests的基本使用
Requests库
r=requests.get(url)
#返回一个包含服务器资源的Response对象
#构造一个向服务器请求资源的Request对象
格式:requests.get(url,params=None,**kwargs)
- url 抓取页面的url连接
- params:url中的额外参数,字典或者字节流的格式
- **kwargs 12个访问控制参数
Response对象
import requests
r=requests.get("http://www.baidu.com")
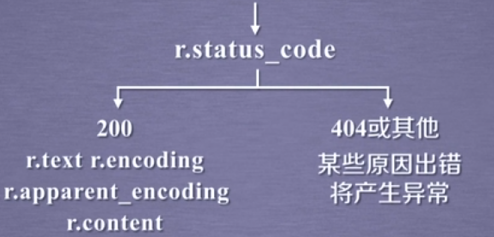
print(r.status_code)#状态码 200 成功 别的失败
type(r)
r.headers
| 属性 | 说明 |
|---|---|
| r.status_code | 状态码,200成功,404失败 |
| r.text | url对应的页面的内容 |
| r.encoding | 编码方式 |
| r.apparent_encoding | 分析出的编码 |
| r.content | 相应内容二进制内容 |
流程
>>> import requests
>>> r=requests.get('http://www.baidu.com')
>>> r.status_code
200
>>> r.content
>>> r.encoding
'ISO-8859-1'
>>> r.apparent_encoding
'utf-8'
>>> r.encoding=r.apparent_encoding
>>> r.content
编码
r.encoding 猜测的编码方式
r.apparent_encoding 从内容分析出的编码方式
Request库的异常
| 异常 | 异常作用 |
|---|---|
| requests.ConnectionError | 网络连接异常 |
| requests.HTTPError | HTTP错误异常 |
| requests.URLRequired | URL缺失异常 |
| requests.TooManyRedirects | 重定向异常 |
| requests.ConnectTimeout | 连接服务器超时异常 |
| requests.Timeout | 请求URL超时异常 |
| r.raise_for_status() | 如果不是200,产生http异常 |
通用的代码
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout=20)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return "产生异常"
Requests库的七个主要方法
| 方法 | 说明 |
|---|---|
| requests.request() | 构建请求 |
| requests.get() | 获取html主要方法 |
| requests.head() | 获取头方法 |
| requests.post() | POST请求 |
| requests.put() | PUT请求 |
| requests.patch() | 局部修改 |
| requests.delete() | 删除请求 |
HTTP协议
超文本传输协议
用户发起请求,服务器给出回应,每次发出请求与请求之间互不影响
采用url来定位资源表示
URL格式:http://host[:port][path]
host:主机的域名或者IP的地址
port:端口号
path:请求资源的路径
URL存取的是网络上资源的路径,一个URL对应一个数据资源
HTTP协议对资源的操作
| 方法 | 说明 |
|---|---|
| GET | 获取位置资源 |
| HEAD | 获取头部信息 |
| POST | 请求向url位置资源之后添加新的信息 |
| PUT | 向url位置存储资源,覆盖url位置资源 |
| PATCH | 更新url位置的资源 |
| delete | 删除URL位置的资源 |

PATCH和PUT的区别
假设URL位置有一组数据UserInfo,包括UserID,UserName,等20个字段
采用PATCH,仅仅向URL提交UserName的局部更新要求
采用PUT,必须将所有20个字段一并提交到URL,未提交字段被删除
head()
r=requests.head(url)
r.headers
post()
payload={'key1':'value1','key2':'values'}
r=requests.post(url,data=payload)
print(r.text)
put()
payload={'key1':'value1','key2':'value2'}
r=requests.put('http://httpbin.org/put',data=payload)
print(r.text)
Requests库解析
request
requests.request(method,url,**kwargs)
**kwargs:控制访问参数
params:字典或者字节序列,作为参数增加到url中
kv={'key1':'value1','key2':'value2'}
r=requests.request('GET','http://python123.io/ws',params=kv)
print(r.url)
#http://python123.io/ws?key1=value1&key2=value2
json:json格式的数据作为Request的内容
kv={'key1':'value1'}
r=requests.request('POST','http://python123.io/ws',json=kv)
header:字典,http定制头
hd={'user-agent':'Chrome/10'}
r=requests.request('POST','http://python123.io/ws',headers=hd)
cookies:字典或者cookieJar,Request中的cookie
auth:元组,支持http认证功能
files:字典类型,传输文件
fs={'file':open('data.xls'),'rb'}
r=requests.request('POST','http://python123.io/ws',files=fs)
timeout:设定超时时间,以秒为单位
r=requests.request('GET','http://www.baidu.com',timeout=10)
proxies:字典类型,设定代理服务器,可以增加登录的认证
异常ip地址
pxs={'http':'http://user:pass@10.10.10.1:1234',
'http':'http://10.10.10.1:4321'}
r=requests.request('GET','http://www.baidu.com',proxies=pxs)
allow_redirects:重定向开关
stream:获取内容重定向下载开关
verify:认证ssl证书开关
head
13个控制参数和request完全一样
post
post(url,data=None,json=None,**kwargs)
url:要更新页面的url链接
data:字典
json:JSON的数据格式,Request的内容
**kwargs:11个访问控制参数
put
url:要更新的url链接
data:字典,字节序列或者文件,request的内容
**kwargs:12个访问控制参数
patch
url:要更新的页面的url
data:字典、字节序列或者文件,request的内容
**kwargs:12个访问控制参数
delete
url 要删除的url的资源
**kwargs:13个访问的控制参数
Requests的基本使用的更多相关文章
- requests的content与text导致lxml的解析问题
title: requests的content与text导致lxml的解析问题 date: 2015-04-29 22:49:31 categories: 经验 tags: [Python,lxml, ...
- requests源码阅读学习笔记
0:此文并不想拆requests的功能,目的仅仅只是让自己以后写的代码更pythonic.可能会涉及到一部分requests的功能模块,但全看心情. 1.另一种类的初始化方式 class Reques ...
- Python爬虫小白入门(二)requests库
一.前言 为什么要先说Requests库呢,因为这是个功能很强大的网络请求库,可以实现跟浏览器一样发送各种HTTP请求来获取网站的数据.网络上的模块.库.包指的都是同一种东西,所以后文中可能会在不同地 ...
- 使用beautifulsoup与requests爬取数据
1.安装需要的库 bs4 beautifulSoup requests lxml如果使用mongodb存取数据,安装一下pymongo插件 2.常见问题 1> lxml安装问题 如果遇到lxm ...
- python爬虫学习(6) —— 神器 Requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 H ...
- ImportError: No module named 'requests'
补充说明: 当前环境是在windows环境下 python版本是:python 3.4. 刚开始学习python,一边看书一边论坛里阅读感兴趣的代码, http://www.oschina.net/c ...
- Python-第三方库requests详解
Requests 是用Python语言编写,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库.它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTT ...
- Requests 乱码
当使用Requests请求网页时,出现下面图片中的一些乱码,我就一脸蒙逼. 程序是这样的. def getLinks(articleUrl): headers = { "Uset-Agent ...
- 爬虫requests模块 2
会话对象¶ 会话对象让你能够跨请求保持某些参数.它也会在同一个 Session 实例发出的所有请求之间保持 cookie, 期间使用 urllib3 的 connection pooling 功能.所 ...
- 爬虫requests模块 1
让我们从一些简单的示例开始吧. 发送请求¶ 使用 Requests 发送网络请求非常简单. 一开始要导入 Requests 模块: >>> import requests 然后,尝试 ...
随机推荐
- Python 元组Ⅰ
Python 元组 Python的元组与列表类似,不同之处在于元组的元素不能修改. 元组使用小括号,列表使用方括号. 元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可. 如下实例: 创建空元 ...
- 观察者模式------《Head First 设计模式》
第二章---观察者模式 xzmxddx 学习方式:书籍<Head First 设计模式>,这本书通俗易懂,所有知识点全部取自本书. 面向对象设计原则 封装变化 多用组合,少用继承 针对接口 ...
- clojure的语法糖
语法糖很多, 就是奔这个“懒” 来用clj的. 但是,在常见的书里(<Clojure编程><Clojure编程乐趣2>)都对很多基本语法,用法都介绍不全, 不细.看书看得很累. ...
- Introduction-to-Psychology Slides
最近在网易公开课学习耶鲁大学Paul Bloom教授的<心理学导论>,英文水平有限,视频中一直没有出现PPT,无意中找到一份课件,现分享于此,大家自取! 链接:https://pan.ba ...
- 多线程之Tread类和Runnable的区别
一.run()方法和start()方法的区别 在java中可有两种方式实现多线程,一种是继承Thread类,一种是实现Runnable接口:Thread类是在java.lang包中定义的.一个类只要继 ...
- layui 获取select option value 获取text
$.trim($("#processState").val()): //获取val $("#processState option:selected").tex ...
- jsp四种属性范围
在JSP提供了四种属性的保存范围.所谓的属性保存范围,指的就是一个设置的对象,可以在多个页面中保存并可以继续使用.它们分别是:page.request.session.appliction. 1.pa ...
- lr_save_string和sprintf、lr_eval_string的使用
一.lr_save_string函数 1.该函数主要是将程序中的常量或变量保存为参数: //将常量保存为参数 lr_save_string("777","page&quo ...
- 惠普服务器DL360G6安装ESXi主机后遗忘密码用u盘重置密码
惠普服务器DL360G6安装ESXi主机后遗忘密码重置密码 先用rufus制作U盘启动盘,启动盘一定要用惠普专用hpe的esxi版本,否则安装会报错, 下载https://www.iplaysoft. ...
- 屏蔽ffmpeg命令的所有提示
有时候需要隐蔽的执行ffmpeg不希望输出任何日志,提示.这个时候只需要多添加这个参数即可 -loglevel quiet