[CSP-S模拟测试]:字符消除2(hash+KMP)
题目背景
生牛哥终于打通了“字符消除”,可是他又被它的续集难倒了。
题目传送门(内部题52)
输入格式
第一行$n$表示数据组书。
接下来每行一个字符串。(只包含大写字母)
输出格式
每组数据输出一个$01$串。
样例
样例输入:
3
YDYYDY
JRYJREJRYJR
YDYAKYDY
样例输出:
010010
01001101001
01000010
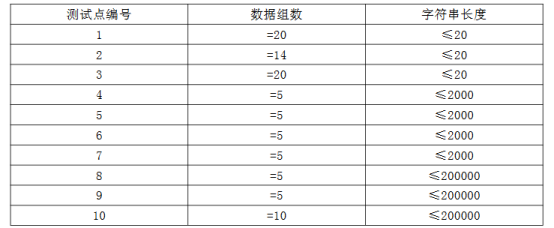
数据范围与提示
题解
为方便,我们设串长为$S$。
首先,来解释一下什么是可行$t$。
对于样例中的第一个串$"YDYYDY"$,我看它比较帅,所以就拿它举例。
它的可行$t$集合为$3$和$6$,为什么呢?
对于一个长度为$3$的环,我们可以这么填:
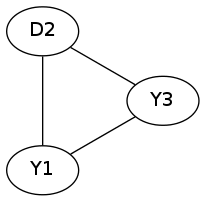
这时,我们填成了一圈,然后我们去填第二圈:
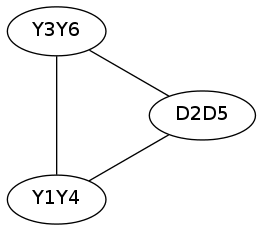
刚好填完,所以它是一个可行$t$,长度为$6$时同理,可是当长度为$4$当我们填到第五个$D$时发现那个位置已经填了$Y$,所以就不可行了。
题意解释完了,我们现在开始考虑这道题应该怎么办?
先来考虑如何求出可行$t$的集合。
我们发现,如果这个串有一个长度为$len$的公共前后缀,那么其中一个可行$t$就是$len-1$,来解释一下:
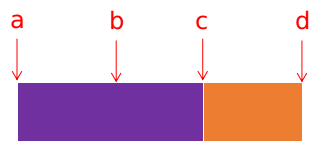
对于一个公共前后缀,如下图:

橙色区域是公共前后缀,绿色区域是串,显然$a\sim b$点即为长度$len$,那么当我们处理到$c$点时完成了一个环,但是接下来我们要填的$c\sim d$这部分和$a\sim b$是一样的,所以这个$n-len$就是一个长度$t$。
对于$t$的集合,我们可以通过$hash$或者是$KMP$在$\Theta(S)$的时间复杂度内求出。
虽说我用的是$hash$,但是我想讲一下$KMP$如何求出,我们只需要从$n$向前不断的找$next$就好了,也就是$next[next[i]]$,下面来解释为什么:

设橙色区域即$a\sim d$是$next[n]$,也就是说$1-$橙色区域是一组可行$t$,现在另紫色区域即$a\sim b$是$next[next[n]]$,现在来证明$1-$紫色区域是一组可行$t$:
因为$a\sim d$和$e\sim h$相同,$a\sim b$、$c\sim d$、$e\sim f$、$g\sim h$相同,所以我们可以当填一圈填到$g$时接着填完最后$g\sim h$($a\sim b=g\sim h$)。
现在再来考虑如何生成$01$串,显然枚举是不可能的。
设$a$数组表示所有的公共前后缀集合(其实就是$KMP$中的$next$数组),注意不是可行$t$,那么这时候分两种情况:
$\alpha.a[k]\times 2\geqslant a[k+1]$:这时候我们就将$01$串后面接上一段长度为$a[k+1]-a[k]$的后缀即可,如下图:
我们现在已经处理好了$a\sim c$这一段,现在要将填$c\sim d$这一段,不妨另$len(b\sim c)=len(c\sim d)$注意现在$c$是$next[d]$,也就是说我们要使$a\sim c=b\sim d$,那么显然是要将$b\sim c$复制到$c\sim d$。
$\beta.a[k]\times 2<a[k+1]$:考虑$next$数组的含义,为了保证解最优,我们一定是先将整个串复制一遍放在最后,然后在中间先填满$0$,如果不行的话将最后一个$0$换成$1$即可,至于如何判断,暴力搞就好了,因为如果$0$不行的话最后以为是$1$肯定行。
这样我们就完美的解决了这道题。
时间复杂度:$\Theta(\sum S)$。
期望得分:$100$分。
实际得分:$100$分。
代码时刻
#include<bits/stdc++.h>
using namespace std;
int n;
char ch[200001];
int b[200001],que[200001],nxt[200001],p;
unsigned long long a[200001],mod[200001];
void pre_work()
{
memset(nxt,0,sizeof(nxt));
memset(b,0,sizeof(b));
p=que[0]=0;
}
void KMP(int l,int r)
{
for(int i=l+1;i<=r;i++)
{
while(p&&b[i]!=b[p+1])p=nxt[p];
if(b[i]==b[p+1])p++;
nxt[i]=p;
}
}
int main()
{
int T;scanf("%d",&T);
mod[1]=1;
for(int i=2;i<=200000;i++)mod[i]=mod[i-1]*131;
while(T--)
{
scanf("%s",ch+1);
pre_work();
n=strlen(ch+1);
a[1]=ch[1]-'A'+1;
for(int i=2;i<=n;i++)
a[i]=a[i-1]*131+ch[i]-'A'+1;
for(int i=0;i<=n;i++)
if(a[i+1]==a[n]-a[n-i-1]*mod[i+2])que[++que[0]]=i+1;
if(que[1]>1)b[que[1]]=1;
KMP(1,que[1]);
for(int i=2;i<=que[0];i++)
{
if(que[i]<=que[i-1]<<1)
{
for(int j=que[i-1]+1;j<=que[i];j++)
b[j]=b[j+que[i-1]-que[i]];
KMP(que[i-1],que[i]);
}
else
{
KMP(que[i-1],que[i]-que[i-1]-1);
int now=p,zero=1,len=que[i]-que[i-1];
while(now)
{
if(!b[now+1]&&!(len%(len-now-1))){b[len]=1;break;}
now=nxt[now];
}
if(!b[now+1]&&!(len%(len-now-1)))b[len]=1;
KMP(len-1,len);
nxt[len]=p;
len=que[i]-que[i-1];
for(int j=1;j<=que[i-1];j++)b[len+j]=b[j];
KMP(len,len+que[i-1]);
}
}
for(int i=1;i<=n;i++)printf("%d",b[i]);
puts("");
}
return 0;
}
rp++
[CSP-S模拟测试]:字符消除2(hash+KMP)的更多相关文章
- [CSP-S模拟测试]:字符交换(贪心+模拟)
题目传送门(内部题136) 输入格式 输入文件第一行为两个正整数$n,k$,第二行为一个长度为$n$的小写字母字符串$s$. 输出格式 输出一个整数,为对字符串$s$进行至多$k$次交换相邻字符的操作 ...
- [CSP-S模拟测试]:回文(hash+二维前缀和)
题目描述 闲着无聊的$YGH$秒掉上面两道题之后,开始思考有趣的回文串问题了. 他面前就有一个漂浮着的字符串.显然$YGH$是会$manacher$的,于是他随手求出了这个字符串的回文子串个数.但是他 ...
- [CSP-S模拟测试]:字符(模拟+剪枝)
题目传送门(内部题33) 输入格式 第一行,两个整数$T,C$,表示测试数据组数和字符种类数.对于每组数据:第一行,一个正整数$M$:接下来的$M$行,每行两个整数$P_k,X_k$($S$的下标从$ ...
- Android单元测试与模拟测试详解
测试与基本规范 为什么需要测试? 为了稳定性,能够明确的了解是否正确的完成开发. 更加易于维护,能够在修改代码后保证功能不被破坏. 集成一些工具,规范开发规范,使得代码更加稳定( 如通过 phabri ...
- csp-s模拟测试94
csp-s模拟测试94 一场简单题,打爆了.$T1$脑抽分解质因数准备分子分母消,想了半天发现$jb$互质直接上天,果断码了高精滚蛋.$T2$无脑手玩大样例,突然灵光一闪想到映射到前$K$大小的区间, ...
- csp-s模拟测试85
csp-s模拟测试85 $T1$全场秒切没有什么区分度,$T2$全场成功转化题意但是我并不会打,$T3$暴力都没打很遗憾. 100 00:21:49 02:56:35 02:56:49 135 02: ...
- 「题解」NOIP模拟测试题解乱写II(36)
毕竟考得太频繁了于是不可能每次考试都写题解.(我解释个什么劲啊又没有人看) 甚至有的题目都没有改掉.跑过来写题解一方面是总结,另一方面也是放松了. NOIP模拟测试36 T1字符 这题我完全懵逼了.就 ...
- Fiddler: AutoResponder 构建模拟测试场景
AutoResponder 可用于拦截某一请求,并重定向到本地的资源,或者使用Fiddler的内置响应.可用于调试服务器端代码而无需修改服务器端的代码和配置,因为拦截和重定向后,实际上访问的是本地的文 ...
- NOIP模拟测试17&18
NOIP模拟测试17&18 17-T1 给定一个序列,选取其中一个闭区间,使得其中每个元素可以在重新排列后成为一个等比数列的子序列,问区间最长是? 特判比值为1的情况,预处理比值2~1000的 ...
随机推荐
- 编程语言-Python2-问题整理
InsecureRequestWarning: Unverified HTTPS request is being made. import urllib3 urllib3.disable_warni ...
- jQury+Ajax与C#后台交换数据
-------------------------------------------jQury+Ajax调用后台方法----------------------------------------- ...
- Spring-Cloud-Alibaba-Nacos 目录
Spring-Cloud-Alibaba-Nacos 目录 学习资料 Nacos 官网(https://nacos.io/zh-cn/docs/what-is-nacos.html) Nacos 程序 ...
- python学习第三十二天函数的闭包
python函数中嵌套另外一个函数,另外一个函数形成一个封闭的环境,里面的那个函数叫做函数的闭包,函数的闭包好处可以保护函数里面的变量,下面讲述函数闭包的实例和用法 1,函数闭包的实例 a='cat' ...
- 如何为自己的网站添加HTTPS服务
如何为自己的网站添加HTTPS服务,针对单个域名而言的,下面介绍网站添加https方法,拿阿里云方法 1.准备证书文件 进入阿里云管理控制台-安全-证书服务点击购买证书服务,进入证书购买页面(放心,我 ...
- 浅谈Linux下的rpm
虽然现在很多人都使用yum去替代rpm了,但是rpm在一些特殊场合下还是有其作用的,比如查询跟验证已安装的rpm包,rpm全称Redhat Package Manager,是一种用于互联网下载包的 ...
- crack Tut.ReverseMe1.exe
测试文件:https://www.wocloud.com.cn/webclient/share/sindex.action?id=i9K_Br6TgE7ZLB3oBGUcJmKcRy5TUdZ8U6_ ...
- FTP客户端遇到150连接超时错误的处理办法
环境:阿里云ECS,win server 2012 R2 / FTP Server(FileZilla 0.9.41) 问题描述:账号连接正常,但无法列出目录,提示150连接超时. 解决过程: 1.关 ...
- sendmail 出现 My unqualified host name的解决办法
有"My unqualified host name"错误 修改/etc/hosts, 在本机的ip那一行, 在xxxhostname后面加上" xxxhostname ...
- python常用函数 I
iter(iterable) 可以生成一个迭代器. 例子: islice(iterator, int, int) itertools的islice方法为迭代器生成器提供切片操作. 例子: izip_l ...