MySQL 数据库慢查询日志分析脚本
这个脚本是基于pt-query-digest做的日志分析脚本,变成可视化的格式。
目录结构是
./mysql_data/log
./mysql_data/log/tmp
./slow_query
# coding = gbk
__author__ = 'T_two' import datetime
import os IP = '111'
dirname = os.path.dirname(os.path.abspath(__file__))
# 解析后的目录名
slow_query= os.path.join(dirname, 'slow_query')
# pt-query-digest前的目录的
mysql_data = os.path.join(os.path.join(dirname, 'mysql_data'), 'log')
# pt-query-digest后的目录的
tmp = os.path.join(mysql_data, 'tmp') def getYesterday():
today=datetime.date.today()
yesterday = str(today - datetime.timedelta(days=1))
return yesterday def getLog(yes_time, slow_query):
# 对日志进行pt-query-digest分析
before_name = yes_time.replace('-', '') + '-' + 'slow-query.log'
# pt-query-digest之前的日志 b_filename
b_filename = os.path.join(mysql_data, before_name)
# print(b_filename)
# pt-query-digest之后的日志 a_filename
after_name = yes_time.replace('-', '') + '-' + IP + '-' + 'slow-query.log'
a_filename = os.path.join(tmp, after_name)
# print(a_filename)
# 最终格式化的日志 e_filename
end_name = IP + '-slow-log-' + yes_time + '.txt'
e_filename = os.path.join(slow_query, end_name)
#print(e_filename)
return b_filename,a_filename,e_filename def getSlowquery(b_filename,a_filename,e_filename):
print('File format starting...')
#os.system('pt-query-digest '+ b_filename + '>' + a_filename) a_slow_query = open(a_filename, 'r', encoding = 'utf8')
e_slow_query = open(e_filename, 'w', encoding = 'utf8')
_line = ''
line = a_slow_query.readlines()[20:] # 对文件切片,去除不需要的前20行。
for line in line:
line = line.strip()
# 提取需要的行
if line.startswith('#') and '# Hosts' not in line and '# Users' not in line and '# Databases' not in line and 'byte' not in line \
and '# Count' not in line and '# Exec time' not in line :
pass
elif line == '':
pass
else:
# 序列号
if '# Query' in line: line = ('\nNO.%s' % line.split()[2])
# 执行次数
elif '# Count' in line: line = ('执行次数: %s' % line.split()[3])
#执行时间
elif '# Exec time' in line: line = ('执行时间 Total: %s min: %s max: %s' % (line.split()[4],line.split()[5],line.split()[6],))
# DB
elif '# Databases' in line: line = ('库名: %s' % line.split()[2])
# 源IP
elif '# Host' in line:line = ('源IP: %s' % line.split()[2])
# 用户名
elif '# User' in line: line = ('用户名: %s' % line.split()[2]) _line = _line + line + '\n' e_slow_query.write(_line)
a_slow_query.close()
e_slow_query.close()
# 将文件拷贝到web目录下
os.system('cp ' + e_filename + ' ' + web_dir)
# 删除10天之前的数据
os.system('find ' + str(slow_query) + ' -mtime +10 | xargs rm -rf ')
os.system('find ' + mysql_data + ' -mtime +10 | xargs rm -rf ')
os.system('find ' + tmp + ' -mtime +10 | xargs rm -rf ') print ('File format end...') if __name__ == '__main__':
yes_time = getYesterday()
b_filename,a_filename, e_filename = getLog(yes_time, slow_query)
getSlowquery(b_filename,a_filename,e_filename)
解析之后显示的结果:
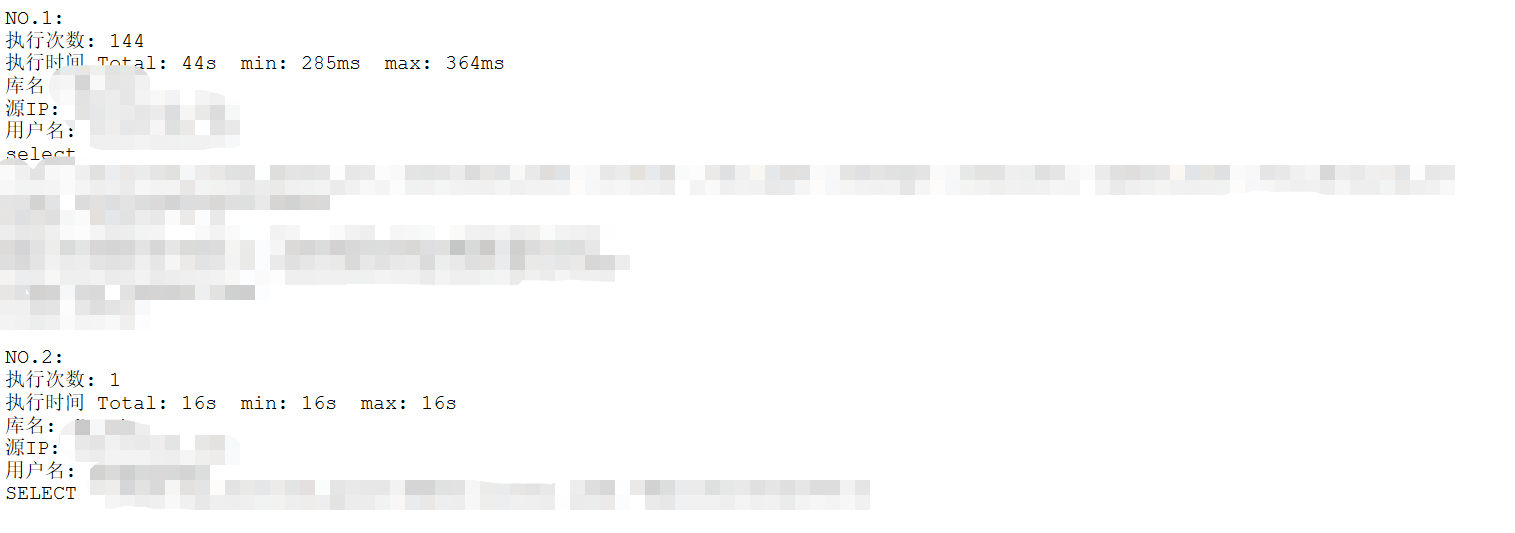
MySQL 数据库慢查询日志分析脚本的更多相关文章
- MySQL之慢查询日志分析
在MySQL命令行中查看慢查询日志是否打开了: mysql> show variables like '%slow_query%'; +---------------------------+- ...
- mysql使用慢查询日志分析数据执行情况
#查询慢查询日志文件路径show variables like '%slow_query%';#开启慢查询日志 ; #设置慢查询阀值为0,将所有的语句都记入慢查询日志 ;#未使用索引的查询也被记录到慢 ...
- MySQL慢查询日志分析
一:查询slow log的状态,如示例代码所示,则slow log已经开启. mysql> show variables like '%slow%'; +-------------------- ...
- MySQL慢查询日志分析提取【转】
原文:https://www.cnblogs.com/skymyyang/p/7239010.html 一:查询slow log的状态,如示例代码所示,则slow log已经开启. mysql> ...
- MySql数据库慢查询
一.什么是数据库慢查询? 数据库慢查询,就是查询时间超过了我们设定的时间的语句. 可以查看设定的时间: 默认的设定时间是10秒.也可以自己根据实际项目设定. set long_query_time=0 ...
- MySQL 通用查询日志和慢查询日志分析
MySQL中的日志包括:错误日志.二进制日志.通用查询日志.慢查询日志等等.这里主要介绍下比较常用的两个功能:通用查询日志和慢查询日志. 1)通用查询日志:记录建立的客户端连接和执行的语句.2)慢查询 ...
- 关于MySQL 通用查询日志和慢查询日志分析
MySQL中的日志包括:错误日志.二进制日志.通用查询日志.慢查询日志等等.这里主要介绍下比较常用的两个功能:通用查询日志和慢查询日志. 1)通用查询日志:记录建立的客户端连接和执行的语句. 2)慢查 ...
- 关于MySQL 通用查询日志和慢查询日志分析(转)
MySQL中的日志包括:错误日志.二进制日志.通用查询日志.慢查询日志等等.这里主要介绍下比较常用的两个功能:通用查询日志和慢查询日志. 1)通用查询日志:记录建立的客户端连接和执行的语句. 2)慢查 ...
- Mysql慢查询和慢查询日志分析
Mysql慢查询和慢查询日志分析 众所周知,大访问量的情况下,可添加节点或改变架构可有效的缓解数据库压力,不过一切的原点,都是从单台mysql开始的.下面总结一些使用过或者研究过的经验,从配置以 ...
随机推荐
- 【工具】Fiddler使用教程
目录 概述 2 Fiddler是做什么的,能帮助我们做什么? 2 工作原理 2 代理模式 3 使用场景--提供的功能 3 界面及使用介绍 3 常用功能 10 HOST配置 10 前后端接口连调--Co ...
- 【读书笔记】GitHub入门
代码管理方式--集中与分散 集中型 以 Subversion 为代表的集中型,所示将仓库集中存放在服务器之中,所以只存在一个仓库.这就是为什么这种版本管理系统会被称作集中型. 集中型将所有数据集中存放 ...
- js 如何定义函数
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- Java基础语法-运算符
1算术运算符 1.1运算符和表达式 运算符:对常量和变量进行操作的符号. 表达式:用运算符把常量或者变量连接起来符合java语法的式子就可以称为表达式. 不同运算符链接的表达式体现的是不同类型的表达式 ...
- [19/10/13-星期日] Python中的函数
一.函数 # 第五章 函数 ## 函数简介(function) - 函数也是一个对象 - 对象是内存中专门用来存储数据的一块区域 - 函数可以用来保存一些可执行的代码,并且可以在需要时,对这些语句进行 ...
- mysql自动生成my.cnf文件
http://imysql.com/my-cnf-wizard.html
- RabbitMq学习4-发布/订阅(Publish/Subscribe)
一.发布/订阅 分发一个消息给多个消费者(consumers).这种模式被称为“发布/订阅”. 为了描述这种模式,我们将会构建一个简单的日志系统.它包括两个程序——第一个程序负责发送日志消息,第二个程 ...
- 1000行MySQL学习笔记
/* 启动MySQL */ net start mysql /* 连接与断开服务器 */ mysql -h 地址 -P 端口 -u 用户名 -p 密码 /* 跳过权限验证登录MySQL */ mysq ...
- LNMP环境搭建哈哈
经过一番折腾,终于将LNMP环境搭建完成了.本文介绍的LNMP环境是在windows的Oracle VM VirtualBox中的Centos虚拟机上搭建的,各个软件的版本为:Centos7 + Ng ...
- 移动前端不得不了解的Meta标签
http://ghmagical.com/article/page/id/PSeJR0rPd34k