使用selenium+BeautifulSoup 抓取京东商城手机信息
1.准备工作:
- chromedriver 传送门:国内:http://npm.taobao.org/mirrors/chromedriver/ vpn:
- selenium
- BeautifulSoup4(美味汤)
pip3 install selenium
pip3 install BeautifulSoup4
chromedriver 的安装请自行百度。我们直奔主题。
起飞前请确保准备工作以就绪...
2.分析网页:
目标网址:https://www.jd.com/


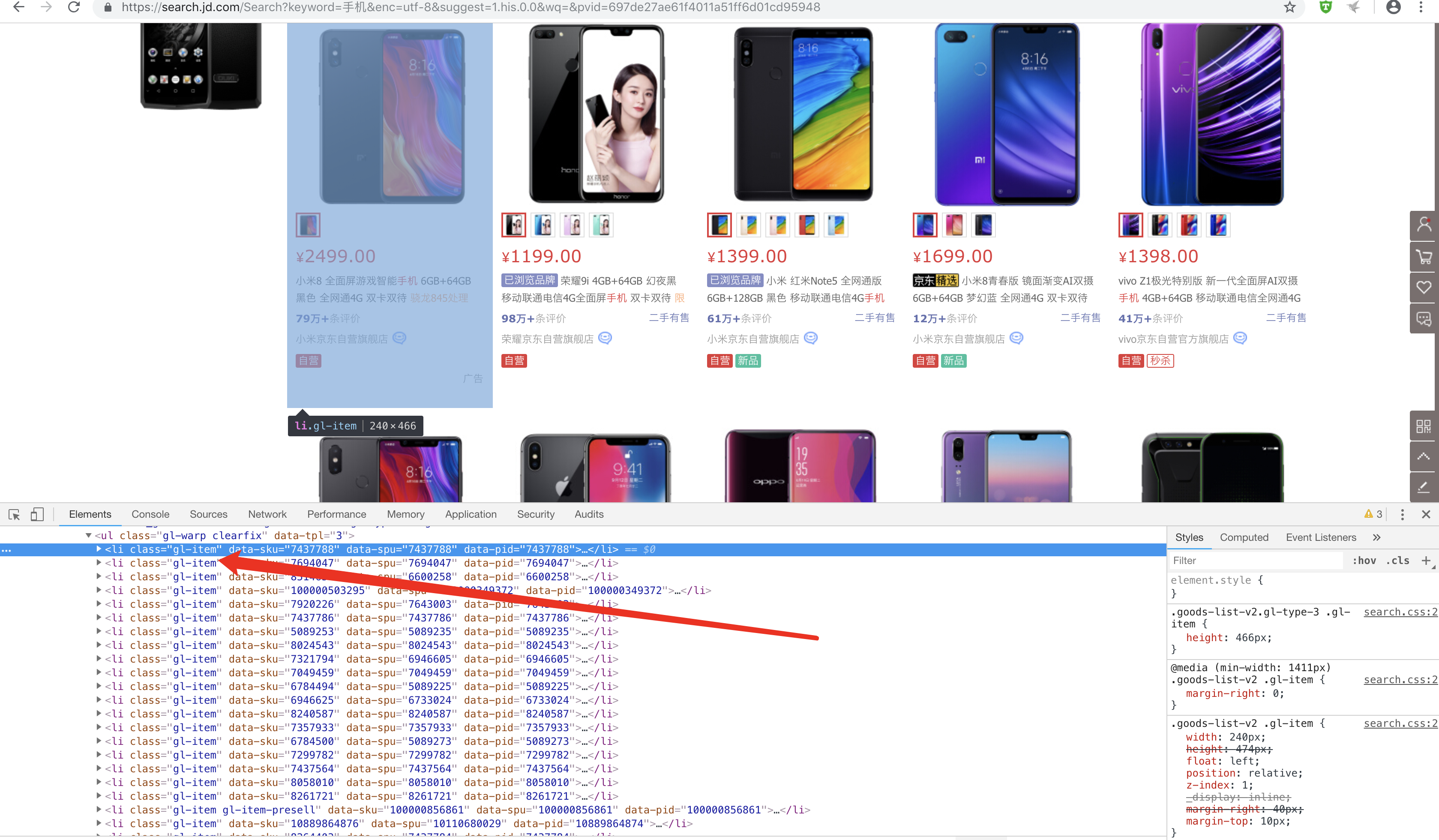
所有item均保存在class="gl-item"里面
需求:
- 使用selenium 驱动浏览器自动侦测到input输入框,输入框中输入“手机”,点击搜索按钮.
- 使用seleinum抓取发挥页面的总页码,并模拟手动翻页
- 使用BeautifulSoup分析页面,抓取手机信息
从入口首页进入查询状态
# 定义入口查询界面
def search():
browser.get('https://www.jd.com/')
try:
# 查找搜索框及搜索按钮,输入信息并点击按钮
input = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#key")))
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#search > div > div.form > button")))
input[0].send_keys('手机')
submit.click()
# 获取总页数
page = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '#J_bottomPage > span.p-skip > em:nth-child(1) > b')))
return page[0].text
# 如果异常,递归调用本函数
except TimeoutException:
search()
查询结束后模拟翻页
# 翻页
def next_page(page_number):
try:
# 滑动到网页底部,加载出所有商品信息
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(4)
html = browser.page_source
# 当网页到达100页时,下一页按钮失效,所以选择结束程序
while page_number == 101:
exit()
# 查找下一页按钮,并点击按钮
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_bottomPage > span.p-num > a.pn-next > em')))
button.click()
# 判断是否加载到本页最后一款产品Item(每页显示60条商品信息)
wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(60)")))
# 判断翻页成功
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR, "#J_bottomPage > span.p-num > a.curr"), str(page_number)))
return html
except TimeoutException:
return next_page(page_number)
解析页面上的a标签
# 解析每一页面上的a链接
def parse_html(html):
"""
解析商品列表网页,获取商品的详情页
""" soup = BeautifulSoup(html, 'html.parser')
items = soup.select('.gl-item')
for item in items:
a = item.select('.p-name.p-name-type-2 a')
link = str(a[0].attrs['href'])
if 'https:' in link:
continue
else:
link = "https:"+link
yield link
根据url 截取商品id 获取价格信息
# 获取手机价格,由于价格信息是请求另外一个地址https://p.3.cn/prices/mgets?skuIds=J_+product_id
def get_price(product_id):
url = 'https://p.3.cn/prices/mgets?skuIds=J_' + product_id
response = requests.get(url,heeders)
result = ujson.loads(response.text)
return result
进入item商品详情页
# 进入详情页
def detail_page(link):
"""
进入item详情页
:param link: item link
:return: html
"""
browser.get(link)
try:
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(3)
html = browser.page_source
return html
except TimeoutException:
detail_page(link)
# 获取详情页的手机信息
def get_detail(html,result):
"""
获取详情页的数据
:param html:
:return:
"""
dic ={}
soup = BeautifulSoup(html, 'html.parser')
item_list = soup.find_all('div', class_='Ptable-item')
for item in item_list:
contents1 = item.findAll('dt')
contents2 = item.findAll('dd')
for i in range(len(contents1)):
dic[contents1[i].string] = contents2[i].string dic['price_jd '] = result[0]['p']
dic['price_mk '] = result[0]['m']
print(dic)
滴滴滴.. 基本上的思路就酱紫咯.. 传送门依旧打开直github: https://github.com/shinefairy/spider/
end~
使用selenium+BeautifulSoup 抓取京东商城手机信息的更多相关文章
- asp.net mvc 抓取京东商城分类
555 asp.net mvc 抓取京东商城分类 URL:http://www.jd.com/allSort.aspx 效果: //后台代码 public ActionResult Get ...
- 如何利用BeautifulSoup选择器抓取京东网商品信息
昨天小编利用Python正则表达式爬取了京东网商品信息,看过代码的小伙伴们基本上都坐不住了,辣么多的规则和辣么长的代码,悲伤辣么大,实在是受不鸟了.不过小伙伴们不用担心,今天小编利用美丽的汤来为大家演 ...
- 如何利用Xpath抓取京东网商品信息
前几小编分别利用Python正则表达式和BeautifulSoup爬取了京东网商品信息,今天小编利用Xpath来为大家演示一下如何实现京东商品信息的精准匹配~~ HTML文件其实就是由一组尖括号构成的 ...
- 如何利用CSS选择器抓取京东网商品信息
前几天小编分别利用Python正则表达式.BeautifulSoup.Xpath分别爬取了京东网商品信息,今天小编利用CSS选择器来为大家展示一下如何实现京东商品信息的精准匹配~~ CSS选择器 目前 ...
- Scrapy实战篇(四)爬取京东商城文胸信息
创建scrapy项目 scrapy startproject jingdong 填充 item.py文件 在这里定义想要存储的字段信息 import scrapy class JingdongItem ...
- Scrapy实战篇(五)爬取京东商城文胸信息
创建scrapy项目 scrapy startproject jingdong 填充 item.py文件 在这里定义想要存储的字段信息 import scrapy class JingdongItem ...
- php+phpquery简易爬虫抓取京东商品分类
这是一个简单的php加phpquery实现抓取京东商品分类页内容的简易爬虫.phpquery可以非常简单地帮助你抽取想要的html内容,phpquery和jquery非常类似,可以说是几乎一样:如果你 ...
- Scrapy实战篇(八)之Scrapy对接selenium爬取京东商城商品数据
本篇目标:我们以爬取京东商城商品数据为例,展示Scrapy框架对接selenium爬取京东商城商品数据. 背景: 京东商城页面为js动态加载页面,直接使用request请求,无法得到我们想要的商品数据 ...
- Python脚本抓取京东手机的配置信息
以下代码是使用python抓取京东小米8手机的配置信息 首先找到小米8商品的链接:https://item.jd.com/7437788.html 然后找到其配置信息的标签,我们找到其配置信息的标签为 ...
随机推荐
- Bootstrap 学习笔记6 列表组面板嵌入组件
列表组组件: 面板组件:
- LeetCode 114. Flatten Binary Tree to Linked List 动态演示
把二叉树先序遍历,变成一个链表,链表的next指针用right代替 用递归的办法先序遍历,递归函数要返回子树变成链表之后的最后一个元素 class Solution { public: void he ...
- OSPF协议——原理及实验
首先命令部分: ospf 1 进入ospf协议 area 0 划定自治区域 因为实验只用了1个区域所以参数就为0 也就是骨干区域 network +网段+反写掩码(0.0.0.255)指定运行OSPF ...
- python selenium无法清除文本框内容问题
正常是我们在清除文本框内容的时候,都会使用 clear() 函数进行清除,但是有时候会出现,清除完成后再点击查询时,文本框的内容会再次自动填充,这个时候我们可以选择以下方式: #清空查询条件drive ...
- 5.1properties属性
需求: 将数据库连接参数单独配置在db.properties文件中,只需在SqlMapconfig.xml中加载db.properties的属性值. 在SqlMapconfig.xml中就不需要对数据 ...
- bzoj1897. tank 坦克游戏(决策单调性分治)
题目描述 有这样一款新的坦克游戏.在游戏中,你将操纵一辆坦克,在一个N×M的区域中完成一项任务.在此的区域中,将会有许多可攻击的目标,而你每摧毁这样的一个目标,就将获得与目标价值相等的分数.只有获得了 ...
- Mac下安装nodejs,然后安装Vue-devtools工具
一.安装nodejs 1.这一步简单,只要上官网下载下来,直接按照提示安装就可以,mac版本的安装方法很简单. 下载nodejs的官方网址是: nodejs.org ,浏览器输入就可以跳转到了 ...
- mybatis where 中in的使用
当我们使用mybatis时,在where中会用到 in 如: where name in ('Jana','Tom'); 我们可以在sql中直接写 name in ('Jana','Tom') 或者 ...
- weblogicjsp编译:查看编译后的java中间代码
转自:https://www.xuebuyuan.com/1069484.html 运行自己配置的web应用,往往只能看见weblogic编译之后的class文件.而看不见编译前的java的文件.为了 ...
- tensorflow的阶、形状、数据类型
张量的阶.形状.数据类型 TensorFlow用张量这种数据结构来表示所有的数据.你可以把一个张量想象成一个n维的数组或列表.一个张量有一个静态类型和动态类型的维数.张量可以在图中的节点之间流通. 阶 ...