HBase体系结构剖析
本文出自:http://wuyudong.com/archives/154
在上篇文章《HBase简介》中,已经提到过,HBase中的Table中的所有行都按照row key的字典序排列,Table 在行的方向上分割为多个Hregion:
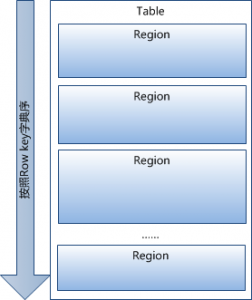
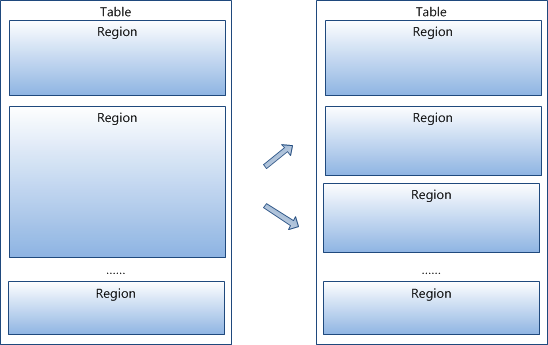
region按大小分割的,每个表一开始只有一个region,随着数据不断插入表,region不断增大,当增大到一个阀值的时候,Hregion就会等分会两个新的Hregion。当table中的行不断增多,就会有越来越多的Hregion。
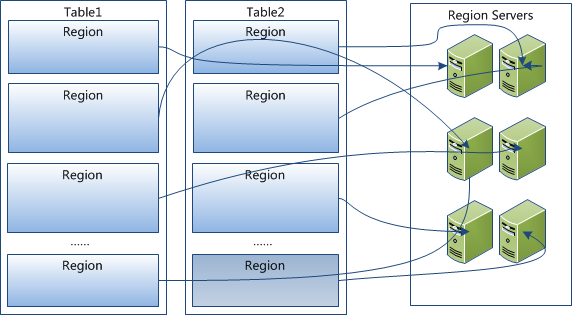
HRegion是Hbase中分布式存储和负载均衡的最小单元。最小单元就表示不同的Hregion可以分布在不同的HRegion server上。但一个Hregion是不会拆分到多个server上的。
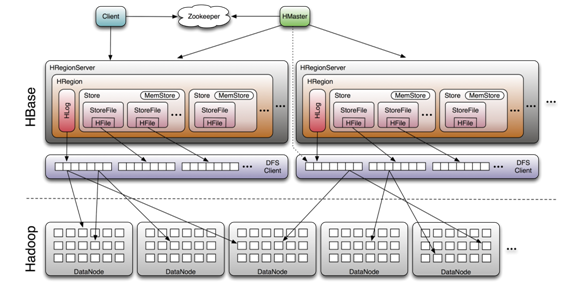
HRegion虽然是分布式存储的最小单元,但并不是存储的最小单元。事实上,HRegion由一个或者多个Store组成,每个store保存一个columns family。每个Strore又由一个memStore和0至多个StoreFile组成。StoreFile以HFile格式保存在HDFS上。如图:
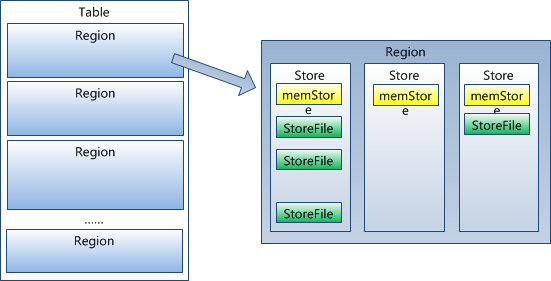
HFile的格式为:
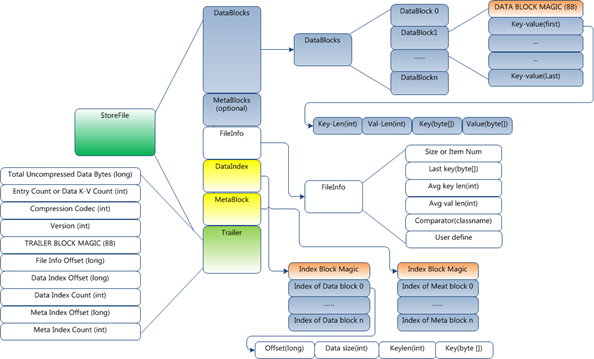
HFile分为六个部分:
Data Block 段–保存表中的数据,这部分可以被压缩
Meta Block 段 (可选的)–保存用户自定义的kv对,可以被压缩。
File Info 段–Hfile的元信息,不被压缩,用户也可以在这一部分添加自己的元信息。
Data Block Index 段–Data Block的索引。每条索引的key是被索引的block的第一条记录的key。
Meta Block Index段 (可选的)–Meta Block的索引。
Trailer– 这一段是定长的。保存了每一段的偏移量,读取一个HFile时,会首先读取Trailer,Trailer保存了每个段的起始位置(段的Magic Number用来做安全check),然后,DataBlock Index会被读取到内存中,这样,当检索某个key时,不需要扫描整个HFile,而只需从内存中找到key所在的block,通过一次磁盘io将整个 block读取到内存中,再找到需要的key。DataBlock Index采用LRU机制淘汰。
HFile的Data Block,Meta Block通常采用压缩方式存储,压缩之后可以大大减少网络IO和磁盘IO,随之而来的开销当然是需要花费cpu进行压缩和解压缩。
目标Hfile的压缩支持两种方式:Gzip,Lzo。
系统架构
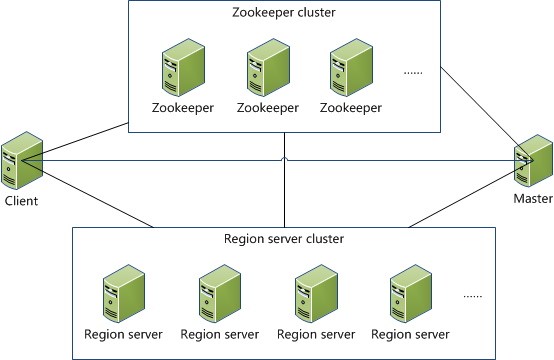
Client
1. 包含访问hbase的接口,client维护着一些cache来加快对hbase的访问,比如regione的位置信息。
Zookeeper
1. 保证任何时候,集群中只有一个master
2. 存贮所有Region的寻址入口。
3. 实时监控Region Server的状态,将Region server的上线和下线信息实时通知给Master
4. 存储Hbase的schema,包括有哪些table,每个table有哪些column family
Master
1. 为Region server分配region
2. 负责region server的负载均衡
3. 发现失效的region server并重新分配其上的region
4. GFS上的垃圾文件回收
5. 处理schema更新请求
Region Server
1.Region server维护Master分配给它的region,处理对这些region的IO请求
2.Region server负责切分在运行过程中变得过大的region
可以看到,client访问hbase上数据的过程并不需要master参与(寻址访问zookeeper和region server,数据读写访问regione server),master仅仅维护者table和region的元数据信息,负载很低。
HBase体系结构剖析的更多相关文章
- HBase(七): HBase体系结构剖析(下)
目录: write Compaction splite read Write: 当客户端发起一个Put请求时,首先根据RowKey寻址,从hbase:meta表中查出该Put数据最终需要去的HRegi ...
- HBase(六): HBase体系结构剖析(上)
HBase隶属于hadoop生态系统,它参考了谷歌的BigTable建模,实现的编程语言为 Java, 建立在hdfs之上,提供高可靠性.高性能.列存储.可伸缩.实时读写的数据库系统.它仅能通过主键( ...
- HBase Coprocessor 剖析与编程实践(转载http://www.cnblogs.com/ventlam/archive/2012/10/30/2747024.html)
HBase Coprocessor 剖析与编程实践 1.起因(Why HBase Coprocessor) HBase作为列族数据库最经常被人诟病的特性包括:无法轻易建立“二级索引”,难以执行求和. ...
- hadoop学习笔记(六):HBase体系结构和数据模型
1. HBase体系结构 一个完整分布式的HBase的组成示意图如下,后面我们再详细谈其工作原理. 1)Client 包含访问HBase的接口并维护cache来加快对HBase的访问. 2)Zooke ...
- HBase体系结构(转)
HBase的服务器体系结构遵循简单的主从服务器架构,它由HRegion服务器(HRegion Server)群和HBase Master服务器(HBase Master Server)构成.HBase ...
- HBase体系结构
HBase的服务器体系结构遵从简单的主从服务器架构,它由HRegion服务器(HRegion Service)群和HBase Master服务器(HBase Master Server)构成.Hbas ...
- HBase - Phoenix剖析
1.概述 在<Hadoop-Drill深度剖析>一文当中,给大家介绍了Drill的相关内容,就实时查询来说,Drill基本能够满足要求,同时还可以做一个简单业务上的聚合,如果在使用Hive ...
- HBase存储剖析与数据迁移
1.概述 HBase的存储结构和关系型数据库不一样,HBase面向半结构化数据进行存储.所以,对于结构化的SQL语言查询,HBase自身并没有接口支持.在大数据应用中,虽然也有SQL查询引擎可以查询H ...
- HBase数据模型剖析
出处:http://wuyudong.com/1987.html HBase 进行数据建模的方式和你熟悉的关系型数据库有些不同.关系型数据库围绕表.列和数据类型——数据的形态使用严格的规则.遵守这些严 ...
随机推荐
- 【Thinking in Java-CHAPTER 3】操作符
优先级 赋值 对象在使用c=d,那么c和d都指向原本只有d指向的那个对象. 方法调用中的别名问题:当一个对象作为参数传递到一个函数中,函数改变了这个参数,则改变了传递进来的对象: 自增和自减 浮点型的 ...
- 代码演示用 .NET 4.5 (C# 5.0)自带的压缩类 ZipArchive 创建一个压缩文件
代码如下: using System; using System.Collections.Generic; using System.IO; using System.IO.Compression; ...
- CSS 块状元素和内联元素
在用CSS布局页面的时候,我们会将HTML标签分成两种,块状元素和内联元素(我们平常用到的div和p就是块状元素,链接标签a就是内联元素) 块状元素一般是其他元素的容器,可容纳内联元素和其他块状元素, ...
- hibernate的多对多例子讲解(加图片)
在hibernate中也有多对多的关系.但是这样关系执行的效率不高,所以我们可以通过两个多对1或者两个1对多来实现. 在现实生活中多对多的关系也比较常见.比如说老师和学生.一个老师有多个学生,一个学生 ...
- [转载]部署Office Web Apps Server并配置其与SharePoint 2013的集成
Office Web Apps Server 是新的 Office 服务器产品,它提供 Word.PowerPoint.Excel 和 OneNote 的基于浏览器的版本.单个 Office Web ...
- bootstrap精简教程
bootstrap 的学习非常简单,并且它所提供的样式又非常精美.只要稍微简单的学习就可以制作出漂亮的页面. bootstrap中文网:http://v3.bootcss.com/ bootstrap ...
- 你不一定知道的几个很有用的 Git 命令
这里给大家分享一些很有用的 Git 命令,其中很多用法你可能都不知道,无论你是工作在团队环境中或在您的个人项目中,这些命令将对你帮助很大,让你可以更加高效的进行项目开发,更轻松愉快的工作和生活. 您可 ...
- ThroughRain第二次冲刺总结
团队名:ThroughRain 项目确定:<餐厅到店点餐系统> 项目背景:本次项目是专门为餐厅开发的一套订餐系统.大家有没有发现在节假日去餐厅吃饭会超级麻烦,人很多, 热门的餐厅基本没有座 ...
- 复利计算6.0—软件工程(web版本)
复利计算再升级------------------------------------------------------------ 客户在大家的引导下,有了更多的想法: 这个数据我经常会填.... ...
- 使用SignalR构建一个最基本的web聊天室
What is SignalR ASP.NET SignalR is a new library for ASP.NET developers that simplifies the process ...