斯坦福CS229机器学习课程笔记 part2:分类和逻辑回归 Classificatiion and logistic regression
Logistic Regression 逻辑回归
1.模型
逻辑回归解决的是分类问题,并且是二元分类问题(binary classification),y只有0,1两个取值。对于分类问题使用线性回归不行,因为直线无法将样本正确分类。
1.1 Sigmoid Function
因为 y∈{0,1},我们也希望 hθ(x)∈{0,1}。第一种选择是 logistic函数或S型函数(logistic function/sigmoid function)。g(z)值的范围在0-1之间,在z=0时为0.5,z无穷小g(z)趋近0,z无穷大g(z)趋近1。
其公式为:
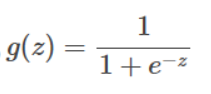
图像为:

同时g(z)的倒数有以下这个特性,即g(z)的倒数刚好等于 g(z)(1-g(z)):
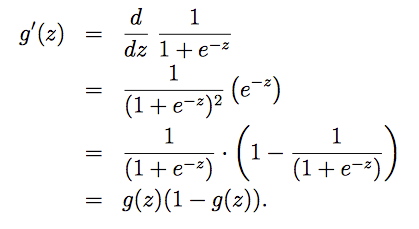
假设 hθ(x) 的公式为:
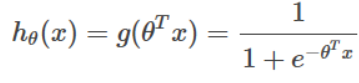
1.2 threshold function
logistic函数是曲线,如果想更加明确地将输出分为0、1两类,就要用到阶梯函数/临界函 (threshold function)。很简单直白的定义:
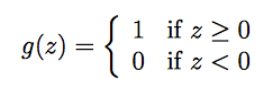
如果使用threshold函数替换logistic函数,则算法称为感知学习算法(Perceptron learning algorithm)。
2.策略
下面根据逻辑回归模型,调整 θ 对其进行拟合。首先进行以下假设:
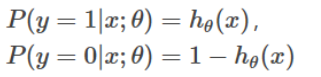
两个式子可以改写成一个式子:
逻辑回归使用的策略是最大化对数似然函数。似然函数 likelihood function 与对数似然函数分别为:

注:似然函数,就是计算整个训练集中每组 x,y 成立的可能性,即将每一组 x(i),y(i) 发生的概率相乘。
求对数是为了计算方便
3.算法
逻辑回归的目的是使可能性最大,即 maximizing 最大化似然函数的值。(线性回归是为了使代价最小,即minimizing代价函数的值,求最低点)
3.1 gradient ascent 梯度上升
先假设只有一个训练样本,对函数 l(θ) 求偏导可得:
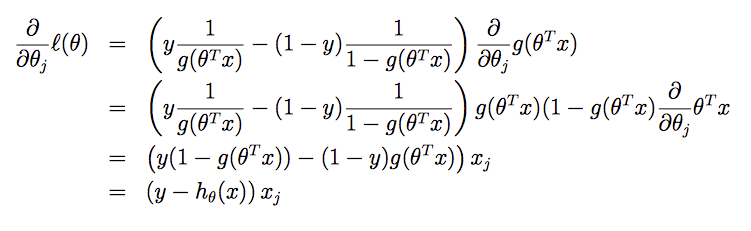
如果有多个样本,同样需要使用梯度算法。但和线性回归有一个区别:为了使函数最大化,要将之前更新算法中的 “-“ 改为“+“,“下降“改为“上升“。
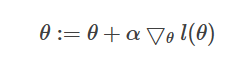
将上面单个训练样本J(θ)的导数进行向量化,得到 随机梯度上升算法 的更新原则(随机没有求和,批量有求和):
这和上一讲中的最小二乘法更新规则的表达式一样,但是其中 hθ(x) 却不同。最小二乘法中的 hθ(x) 是线性函数,而此表达式中的 hθ(x) 是sigmoid函数。
3.2 Newton’s method 牛顿方法
极值点就是导数为0的地方,所以最大化对数似然函数的另一个求法是求对数似然函数导数为0的点。
(1)考虑最简单情况:θ是一个实数,首先找到一个实数域上的方程 f,f(θ)=0。 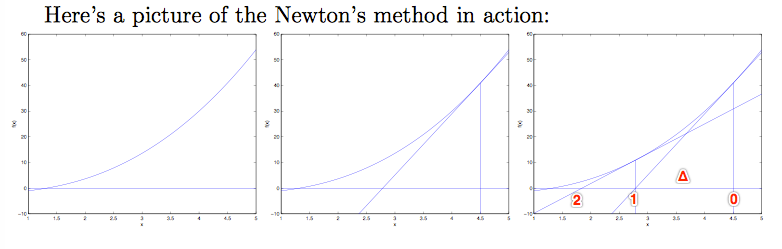
从起始点θ0开始,找到f(θ0)处的切线,与坐标轴相交于θ1。再从求 f(θ1) 处的切线,与坐标轴相交于θ2。不断迭代,直到切线斜率为0。
如果将 θ0 和 θ1 两点之间的距离记为Δ,可以通过求Δ来判断下一个θ在哪。根据 tan() 的特性,有: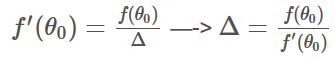
所以牛顿方法执行更新规则:

如果想要找到 θ 使得 l(θ) 最大,那么 θ 满足 l′(θ) = 0,可以将牛顿方法运用其中,将 l′(θ)替代上式中的 f(θ),得到:

注:如果想要使用牛顿方法最小化而不是最大化一个函数,公式怎么改?答案是不改,因为最小和最大值处对应的导数都是0。
(2)考虑一般化情况,θ 是一个向量。则一般化的牛顿方法(也称作Newton-Raphson method) 为: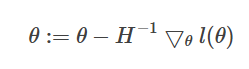
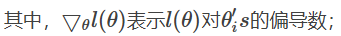
H表示黑塞矩阵(Hessian matrix),是二阶导数矩阵。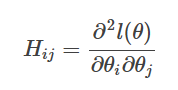
3.2 牛顿方法的优缺点
优点:牛顿方法比梯度上升算法减少了迭代次数,通常来说有更快的收敛速度,相对来说经过很少次迭代就能接近最小值。也称为二次收敛 quadratic conversions,即收敛速度几乎翻倍。
缺点:每次迭代都要重新计算 Hessian矩阵的逆,如果在大规模数据中涉及很多特征,将花费巨大计算代价并且变慢。
Google 是利用逻辑回归预测搜索广告的点击率。
https://blog.csdn.net/TRillionZxY1/article/details/77099955
斯坦福CS229机器学习课程笔记 part2:分类和逻辑回归 Classificatiion and logistic regression的更多相关文章
- 机器学习算法笔记1_2:分类和逻辑回归(Classification and Logistic regression)
形式: 採用sigmoid函数: g(z)=11+e−z 其导数为g′(z)=(1−g(z))g(z) 如果: 即: 若有m个样本,则似然函数形式是: 对数形式: 採用梯度上升法求其最大值 求导: 更 ...
- 斯坦福CS229机器学习课程笔记 part3:广义线性模型 Greneralized Linear Models (GLMs)
指数分布族 The exponential family 因为广义线性模型是围绕指数分布族的.大多数常用分布都属于指数分布族,服从指数分布族的条件是概率分布可以写成如下形式:η 被称作自然参数(nat ...
- 吴恩达机器学习笔记22-正则化逻辑回归模型(Regularized Logistic Regression)
针对逻辑回归问题,我们在之前的课程已经学习过两种优化算法:我们首先学习了使用梯度下降法来优化代价函数
- 分类和逻辑回归(Classification and logistic regression)
分类问题和线性回归问题问题很像,只是在分类问题中,我们预测的y值包含在一个小的离散数据集里.首先,认识一下二元分类(binary classification),在二元分类中,y的取值只能是0和1.例 ...
- 斯坦福CS229机器学习课程笔记 Part1:线性回归 Linear Regression
机器学习三要素 机器学习的三要素为:模型.策略.算法. 模型:就是所要学习的条件概率分布或决策函数.线性回归模型 策略:按照什么样的准则学习或选择最优的模型.最小化均方误差,即所谓的 least-sq ...
- 斯坦福机器学习视频笔记 Week3 逻辑回归与正则化 Logistic Regression and Regularization
我们将讨论逻辑回归. 逻辑回归是一种将数据分类为离散结果的方法. 例如,我们可以使用逻辑回归将电子邮件分类为垃圾邮件或非垃圾邮件. 在本模块中,我们介绍分类的概念,逻辑回归的损失函数(cost fun ...
- CS229笔记:分类与逻辑回归
逻辑回归 对于一个二分类(binary classification)问题,\(y \in \left\{0, 1\right\}\),如果直接用线性回归去预测,结果显然是非常不准确的,所以我们采用一 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 7 Regularization 正则化
Lecture7 Regularization 正则化 7.1 过拟合问题 The Problem of Overfitting7.2 代价函数 Cost Function7.3 正则化线性回归 R ...
- CS229 机器学习课程复习材料-线性代数
本文是斯坦福大学CS 229机器学习课程的基础材料,原始文件下载 原文作者:Zico Kolter,修改:Chuong Do, Tengyu Ma 翻译:黄海广 备注:请关注github的更新,线性代 ...
随机推荐
- UI - 视图控制器跳转另一个视图控制器特效总结
1. 从一个视图控制器跳转另一个视图控制器的方式是可以进行设置的 CATransition *animation = [[CATransition alloc]init]; animation.dur ...
- Flask 通关攻略大全
基本使用 from flask import Flask app = Flask(__name__) @app.route('/') def hello_world(): return 'Hello ...
- Activity Process Task Application 专题讲解
Activity Process Task Application 专题讲解 Activity.和进程 为了阅读方便,将文档转成pdf http://files.cnblogs.com/franksu ...
- AAC解码算法原理详解
”
- 自定义View实战--实现一个清新美观的加载按钮
本篇文章已授权微信公众号 guolin_blog (郭霖)独家发布 在 Dribble 上偶然看到了一组交互如下: 当时在心里问自己能不能做,答案肯定是能做的,不过我比较懒,觉得中间那个伸缩变化要编写 ...
- 演示使用Metasploit入侵Windows
我使用Kali Linux的IP地址是192.168.0.112:在同一局域网内有一台运行Windows XP(192.168.0.108)的测试电脑. 本文演示怎么使用Metasploit入侵win ...
- Django之搭建学员管理系统
GET请求传参数的方式: /xxx/?k1=v1&k2=v2 ? 前面的是URL ?后面的是请求的参数 多个参数之间用&分隔 POST请求传数据: 是放在请求体里面的 表结构设计. - ...
- 深入学习Heritrix---解析Frontier(链接工厂)(转)
深入学习Heritrix---解析Frontier(链接工厂) Frontier是Heritrix最核心的组成部分之一,也是最复杂的组成部分.它主要功能是为处理链接的线程提供URL,并负责链接处理完成 ...
- 高级C/C++编译技术之读书笔记(三)之动态库设计
最近有幸阅读了<高级C/C++编译技术>深受启发,该书深入浅出地讲解了构建过程(编译.链接)中的各种细节,从多个角度展示了程序与库文件或代码的集成方法,提出了面向代码复用和系统集成的软件架 ...
- 51nod 1012 最小公倍数LCM
输入2个正整数A,B,求A与B的最小公倍数. 收起 输入 2个数A,B,中间用空格隔开.(1<= A,B <= 10^9) 输出 输出A与B的最小公倍数. 输入样例 30 105 输出 ...