Cross Entropy in Machine Learning
整理摘自:https://blog.csdn.net/tsyccnh/article/details/79163834
信息论
Outline
1. 信息量与信息熵
2. 相对熵(KL散度)
3. 交叉熵
--------------------------------
1. 信息量与信息熵
https://baike.baidu.com/item/%E4%BF%A1%E6%81%AF%E7%86%B5/7302318?fr=aladdin
信息论之父 C. E. Shannon 在 1948 年发表的论文“通信的数学理论( A Mathematical Theory of Communication )”中, Shannon 指出,任何信息都存在冗余,冗余大小与信息中每个符号(数字、字母或单词)的出现概率或者说不确定性有关。香农用信息熵的概念来描述信源的不确定度。
通常,一个信源发送出什么符号是不确定的,衡量它可以根据其出现的概率来度量。概率大,出现机会多,不确定性小;反之就大。
(1) 某一单个符号发生的不确定性
假设X是一个离散型随机变量,其取值集合为χ,概率分布函数p(x)=Pr(X=x),x∈χ,则定义事件X=x0的信息量为:
I(x0) = −log(p(x0))
(2) 信源所有可能发生情况的平均不确定性
在信源中,考虑的不是某一单个符号发生的不确定性,而是要考虑这个信源所有可能发生情况的平均不确定性。若信源符号有n种取值:U1…Ui…Un,对应概率为:P1…Pi…Pn,且各种符号的出现彼此独立。这时,信源的平均不确定性应当为单个符号不确定性 -logPi 的统计平均值(E),可称为信息熵,即
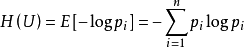 式中对数一般取2为底,单位为比特。也可以取其它对数底,采用其它相应的单位,它们间可用换底公式换算。
式中对数一般取2为底,单位为比特。也可以取其它对数底,采用其它相应的单位,它们间可用换底公式换算。
例子:假设你拿出了你的电脑,按下开关,会有三种可能性,下表列出了每一种可能的概率及其对应的信息量
| 序号 | 事件 | 概率p | 信息量I |
|---|---|---|---|
| A | 电脑正常开机 | 0.7 | -log(p(A))=0.36 |
| B | 电脑无法开机 | 0.2 | -log(p(B))=1.61 |
| C | 电脑爆炸了 | 0.1 | -log(p(C))=2.30 |
熵用来表示所有信息量的期望,上面的问题结果就是
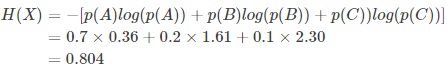
(3) 0-1分布问题
对于这类问题,熵的计算方法可以简化为:
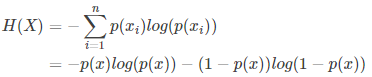
2. 相对熵(KL散度)
相对熵又称KL散度,如果我们对于同一个随机变量 x 有两个单独的概率分布 P(x) 和 Q(x),我们可以使用 KL 散度(Kullback-Leibler (KL) divergence)来衡量这两个分布的差异。
维基百科对相对熵的定义:
In the context of machine learning, DKL(P‖Q) is often called the information gain achieved if P is used instead of Q.
即如果用P来描述目标问题,而不是用Q来描述目标问题,得到的信息增量。
在机器学习中,P往往用来表示样本的真实分布,比如[1,0,0]表示当前样本属于第一类。Q用来表示模型所预测的分布,比如[0.7,0.2,0.1]。
直观的理解就是如果用P来描述样本,那么就非常完美。而用Q来描述样本,虽然可以大致描述,但是不是那么的完美,信息量不足,需要额外的一些“信息增量”才能达到和P一样完美的描述。如果我们的Q通过反复训练,也能完美的描述样本,那么就不再需要额外的“信息增量”,Q等价于P。
KL散度的计算公式:
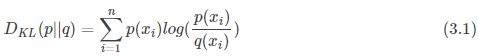
n为事件的所有可能性,DKL 的值越小,表示q分布和p分布越接近。
附注:这里 p(xi) / q(xi) 在一定程度上可以衡量p,q之间的差距。当 p = q 时,商为1,log值为0,DKL = 0.
3. 交叉熵
对式3.1变形可以得到:
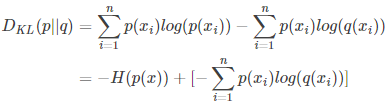
等式的前一部分恰巧就是p的熵,等式的后一部分,就是交叉熵:
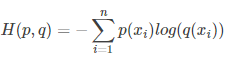
在机器学习中,我们需要评估label和predicts之间的差距,使用KL散度刚刚好,即 ,由于KL散度中的前一部分−H(y)不变,故在优化过程中,只需要关注交叉熵就可以了。所以一般在机器学习中直接用用交叉熵做loss,评估模型。
,由于KL散度中的前一部分−H(y)不变,故在优化过程中,只需要关注交叉熵就可以了。所以一般在机器学习中直接用用交叉熵做loss,评估模型。
机器学习中交叉熵的应用
Outline
1. 为什么要用交叉熵做loss函数?
2. 交叉熵在单分类问题中的使用
3. 交叉熵在多分类问题中的使用
-------------------------------------------------------------
1. 为什么要用交叉熵做loss函数?
在线性回归问题中,常常使用MSE(Mean Squared Error)作为loss函数,比如:
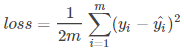
这里的m表示m个样本的,loss为m个样本的loss均值。
MSE在线性回归问题中比较好用,那么在逻辑分类问题中还是如此么?
2. 交叉熵在单分类问题中的使用
这里的单类别是指,每一张图像样本只能有一个类别,比如只能是狗或只能是猫。

上式为一张样本的loss计算方法。式2.1中n代表着n种类别。
举例说明,比如有如下样本

对应的标签和预测值
| * | 猫 | 青蛙 | 老鼠 |
|---|---|---|---|
| Label | 0 | 1 | 0 |
| Pred | 0.3 | 0.6 | 0.1 |
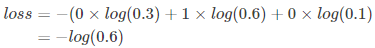
对应一个batch的loss就是:
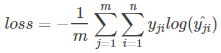
m为当前batch的样本数,n为类别数。
3. 交叉熵在多分类问题中的使用
这里的多类别是指,每一张图像样本可以有多个类别,比如同时包含一只猫和一只狗。和单分类问题的标签不同,多分类的标签是n-hot。比如下面这张样本图,即有青蛙,又有老鼠,所以是一个多分类问题。
对应的标签和预测值:
| * | 猫 | 青蛙 | 老鼠 |
|---|---|---|---|
| Label | 0 | 1 | 1 |
| Pred | 0.1 | 0.7 | 0.8 |
值得注意的是,这里的Pred不再是通过softmax计算的了,这里采用的是sigmoid。将每一个节点的输出归一化到[0,1]之间。所有Pred值的和也不再为1。换句话说,就是每一个Label都是独立分布的,相互之间没有影响。所以交叉熵在这里是单独对每一个节点进行计算,每一个节点只有两种可能值,所以是一个二项分布。前面说过对于二项分布这种特殊的分布,熵的计算可以进行简化。
附注:相当于对于每一个类别,看做一个0-1分布问题,求各个类别下的lossi,然后将各个类别的loss加和即为多分类任务总的loss.
同样的,交叉熵的计算也可以简化,即 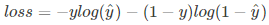
注意,上式只是针对一个节点的计算公式。这一点一定要和单分类loss区分开来。
例子中可以计算为:
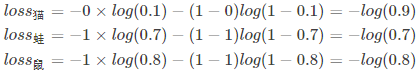
单张样本的loss即为
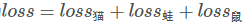
每一个batch的loss就是:
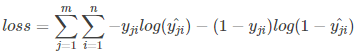
式中m为当前batch中的样本量,n为类别数。
Cross Entropy in Machine Learning的更多相关文章
- Machine Learning Methods: Decision trees and forests
Machine Learning Methods: Decision trees and forests This post contains our crib notes on the basics ...
- 学习笔记之Machine Learning Crash Course | Google Developers
Machine Learning Crash Course | Google Developers https://developers.google.com/machine-learning/c ...
- 《MATLAB Deep Learning:With Machine Learning,Neural Networks and Artificial Intelligence》选记
一.Training of a Single-Layer Neural Network 1 Delta Rule Consider a single-layer neural network, as ...
- How do I learn mathematics for machine learning?
https://www.quora.com/How-do-I-learn-mathematics-for-machine-learning How do I learn mathematics f ...
- 機器學習基石(Machine Learning Foundations) 机器学习基石 作业三 课后习题解答
今天和大家分享coursera-NTU-機器學習基石(Machine Learning Foundations)-作业三的习题解答.笔者在做这些题目时遇到非常多困难,当我在网上寻找答案时却找不到,而林 ...
- 关于交叉熵损失函数Cross Entropy Loss
1.说在前面 最近在学习object detection的论文,又遇到交叉熵.高斯混合模型等之类的知识,发现自己没有搞明白这些概念,也从来没有认真总结归纳过,所以觉得自己应该沉下心,对以前的知识做一个 ...
- 机器学习---逻辑回归(一)(Machine Learning Logistic Regression I)
逻辑回归(Logistic Regression)是一种经典的线性分类算法.逻辑回归虽然叫回归,但是其模型是用来分类的. 让我们先从最简单的二分类问题开始.给定特征向量x=([x1,x2,...,xn ...
- 【Machine Learning】决策树案例:基于python的商品购买能力预测系统
决策树在商品购买能力预测案例中的算法实现 作者:白宁超 2016年12月24日22:05:42 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本 ...
- 【机器学习Machine Learning】资料大全
昨天总结了深度学习的资料,今天把机器学习的资料也总结一下(友情提示:有些网站需要"科学上网"^_^) 推荐几本好书: 1.Pattern Recognition and Machi ...
随机推荐
- override render 方法
有时候需要在ASP.net 或MVC 中在页面呈现前,把要显示的内容作一个拦截,更改内容后显示. 只要重写 protected override void Render(System.Web.UI. ...
- py faster rcnn+ 1080Ti+cudnn5.0
看了py-faster-rcnn上的issue,原来大家都遇到各种问题. 我要好好琢磨一下,看看到底怎么样才能更好地把GPU卡发挥出来.最近真是和GPU卡较上劲了. 上午解决了g++的问题不是. 然后 ...
- vue2.0+node.js+mongodb全栈打造商城
Github地址:https://github.com/ccyinghua/vue-node-mongodb-project 一.构建项目所用: vue init webpack vue-node-m ...
- Java并发编程:JMM和volatile关键字
转载请标明出处: http://blog.csdn.net/forezp/article/details/77580491 本文出自方志朋的博客 Java内存模型 随着计算机的CPU的飞速发展,CPU ...
- python tips(持续更新中)
python tips 可变对象与不可变对象 在python中,可变对象有数值类型(int,float),字符串(str),元组(tuple),可变对象有列表(list),字典(dict),集合(se ...
- [oracle]分区表学习
(一)什么是分区 所谓分区,就是将一张巨型表或巨型索引分成若干个独立的组成部分进行存储和管理,每一个相对小的,可独立管理的部分,称为分区. (二)分区的优势 提高数据可管理性.对表进行分区,数据的加载 ...
- h5移动端页面meta标签
<!DOCTYPE html> <!-- 使用 HTML5 doctype,不区分大小写 --> <html lang="zh-cmn-Hans"&g ...
- PHP实现微信红包算法和微信红包的架构设计简介
微信红包的架构设计简介: 原文:https://www.zybuluo.com/yulin718/note/93148 @来源于QCon某高可用架构群整理,整理朱玉华. 背景:有某个朋友在朋友圈咨询微 ...
- django之多表查询
一.创建模型 在Models创建如下模型: from django.db import models # Create your models here. # 用了OneToOneField和Fore ...
- 网站漏洞修复之最新版本UEditor漏洞
UEditor于近日被曝出高危漏洞,包括目前官方UEditor 1.4.3.3 最新版本,都受到此漏洞的影响,ueditor是百度官方技术团队开发的一套前端编辑器,可以上传图片,写文字,支持自定义的h ...