【七】强化学习之Policy Gradient---PaddlePaddlle【PARL】框架{飞桨}
相关文章:
【一】飞桨paddle【GPU、CPU】安装以及环境配置+python入门教学
代码链接:码云:https://gitee.com/dingding962285595/parl_work ;github:https://github.com/PaddlePaddle/PARL
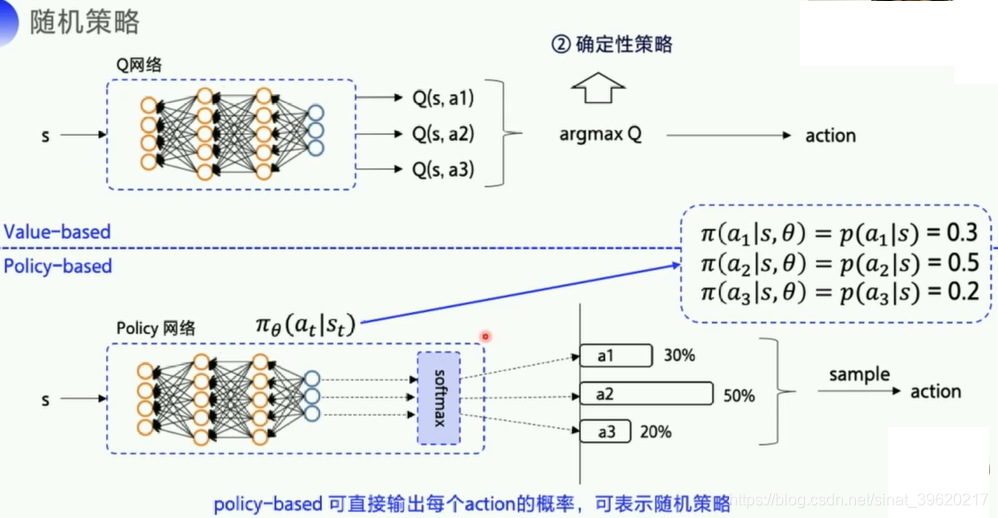
1.随机策略与梯度策略
1.1 Policy Gradient-与DQN预测区别:
在强化学习中,有两大类方法,一种基于值(Value-based),一种基于策略(Policy-based)
Value-based的算法的典型代表为Q-learning和SARSA,将Q函数优化到最优,再根据Q函数取最优策略。Policy-based的算法的典型代表为Policy Gradient,直接优化策略函数。
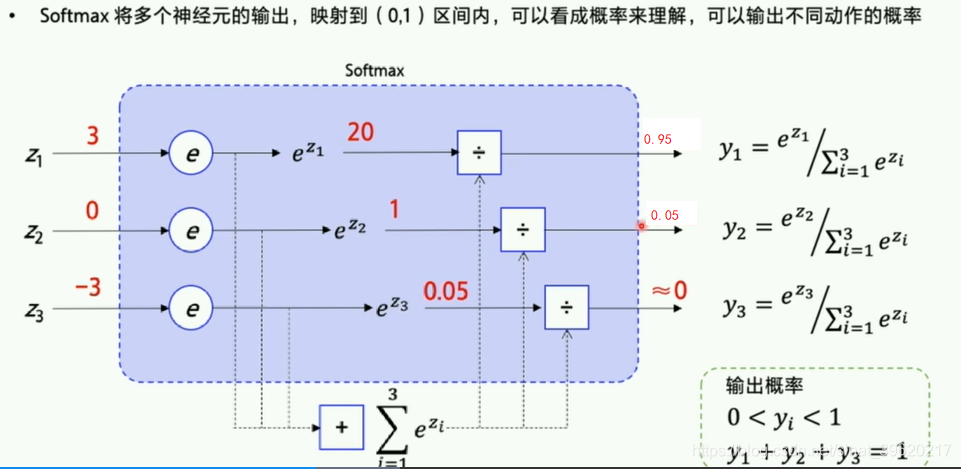
softmax转化为概率
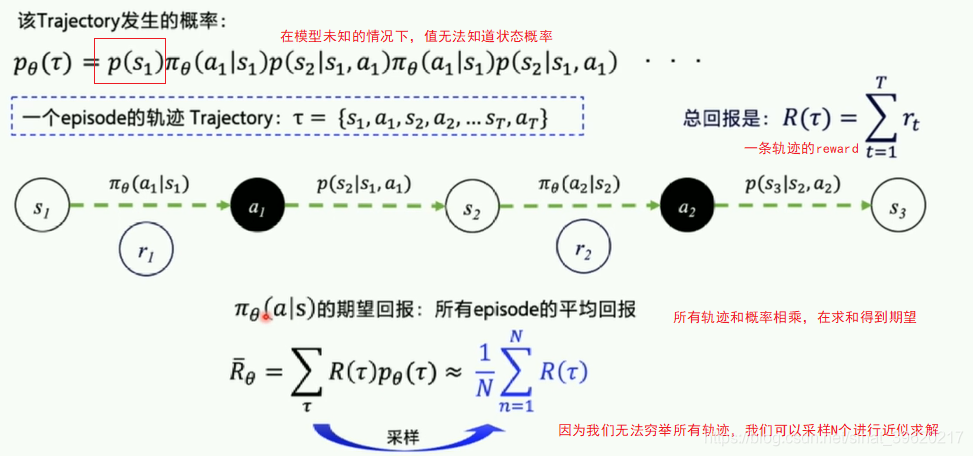
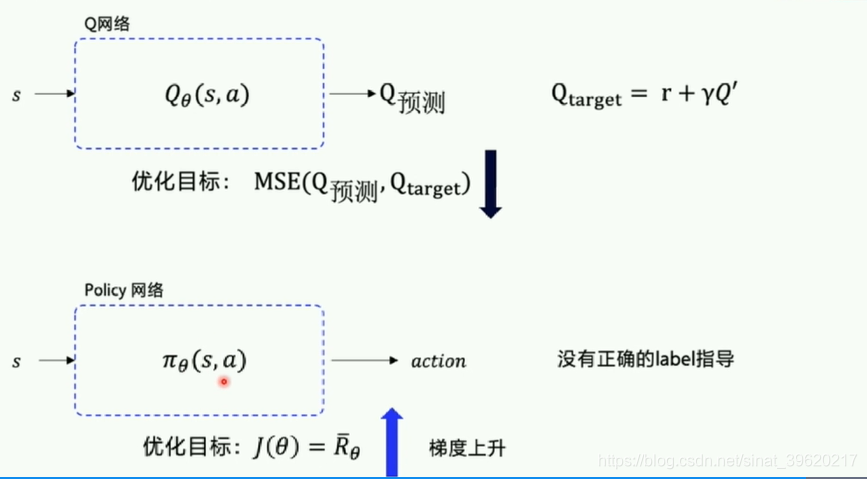
采用神经网络拟合策略函数,需计算策略梯度用于优化策略网络。
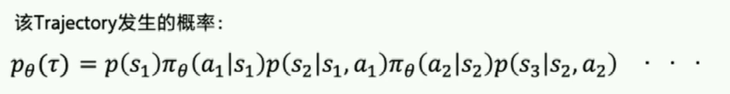 轨迹改正一下
轨迹改正一下
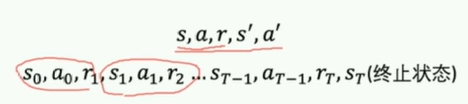
- 优化的目标是在策略
π(s,a)的期望回报:所有的轨迹获得的回报R与对应的轨迹发生概率p的加权和,当N足够大时,可通过采样N个Episode求平均的方式近似表达。
优化策略函数
- 优化目标对参数
θ求导后得到策略梯度:
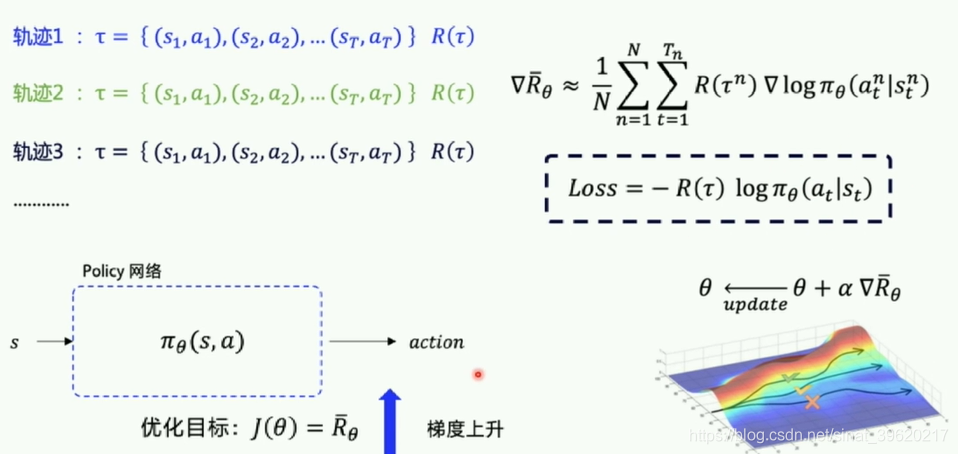
程序里有自带优化器一般都是梯度下降,只要加个负号loss进行转变梯度上升。
2.PG算法
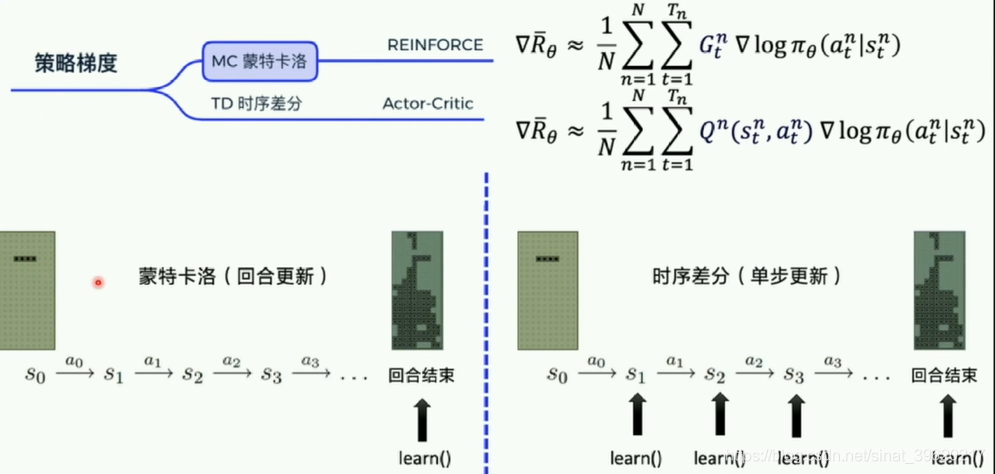
2.1 MC蒙特卡洛--reinforce
拿到一条轨迹,在进行learn,可以得到每个轨迹的reward进行求解期望,未来总收益-------回合更新
表示当前t时刻后续可以拿到的收益,
def calc_reward_to_go(reward_list, gamma=1.0):
for i in range(len(reward_list) - 2, -1, -1):
# G_i = r_i + γ·G_i+1
reward_list[i] += gamma * reward_list[i + 1] # Gt
return np.array(reward_list)每个step得到的reward转化成未来每个总收益。

- 通过采样
,消除外面的
- 这里对theta求导,p和theta无关,直接删掉,连乘log变连加
reinforce伪代码:

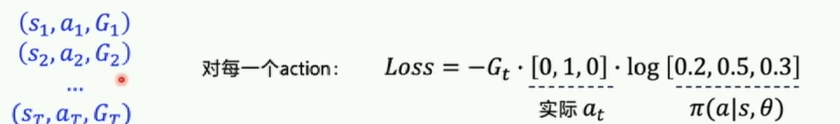
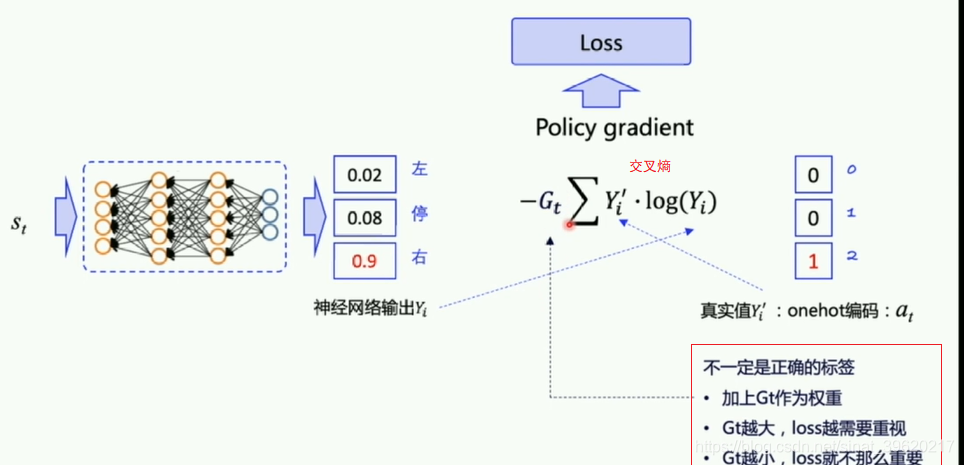
LOSS得到情况。

def learn(self, obs, action, reward):
""" 用policy gradient 算法更新policy model
"""
act_prob = self.model(obs) # 获取输出动作概率
# log_prob = layers.cross_entropy(act_prob, action) # 交叉熵
log_prob = layers.reduce_sum(
-1.0 * layers.log(act_prob) * layers.one_hot(
action, act_prob.shape[1]),
dim=1)
cost = log_prob * reward
cost = layers.reduce_mean(cost)
optimizer = fluid.optimizer.Adam(self.lr)
optimizer.minimize(cost)
return costobs, action, reward分别是S、A、R;先得到预测动作概率然后和onehot(实际动作)相乘;再乘以reward,就得到LOSS。即上面对应的公式。
reduce_mean求出每条轨迹平均的reward然后得到平均loss,然后放入优化器中。【每个轨迹都会对应一个loss,算出所有轨迹的平均loss放到Adam优化器优化】
2.1.2 MC流程解析
Agent把产生的数据传给algorithm,algorithm根据model的模型结构计算出Loss,使用SGD或者其他优化器不断的优化,PARL这种架构可以很方便的应用在各类深度强化学习问题中。
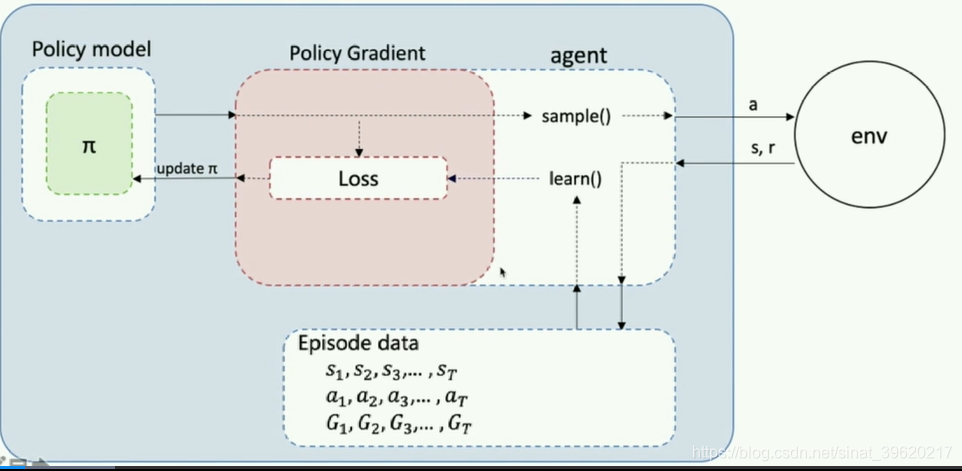
对应封装程序:
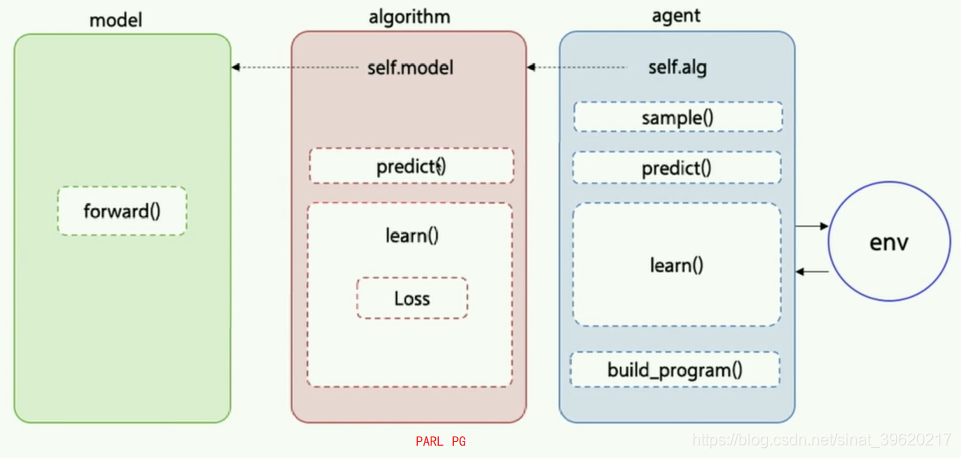
- forward()
Model用来定义前向(Forward)网络,用户可以自由的定制自己的网络结构。
class Model(parl.Model):
def __init__(self, act_dim):
act_dim = act_dim
hid1_size = act_dim * 10
self.fc1 = layers.fc(size=hid1_size, act='tanh')
self.fc2 = layers.fc(size=act_dim, act='softmax')
def forward(self, obs): # 可直接用 model = Model(5); model(obs)调用
out = self.fc1(obs)
out = self.fc2(out)
return out- algorithm
Algorithm定义了具体的算法来更新前向网络(Model),也就是通过定义损失函数来更新Model,和算法相关的计算都放在algorithm中。
class PolicyGradient(parl.Algorithm):
def __init__(self, model, lr=None):
""" Policy Gradient algorithm
Args:
model (parl.Model): policy的前向网络.
lr (float): 学习率.
"""
self.model = model
assert isinstance(lr, float)
self.lr = lr
def predict(self, obs):
""" 使用policy model预测输出的动作概率
"""
return self.model(obs)
def learn(self, obs, action, reward):
""" 用policy gradient 算法更新policy model
"""
act_prob = self.model(obs) # 获取输出动作概率
# log_prob = layers.cross_entropy(act_prob, action) # 交叉熵 和下一行公式效果相同
log_prob = layers.reduce_sum(
-1.0 * layers.log(act_prob) * layers.one_hot(
action, act_prob.shape[1]),
dim=1)
cost = log_prob * reward
cost = layers.reduce_mean(cost)
optimizer = fluid.optimizer.Adam(self.lr)
optimizer.minimize(cost)
return cost- agent
Agent负责算法与环境的交互,在交互过程中把生成的数据提供给Algorithm来更新模型(Model),数据的预处理流程也一般定义在这里。
class Agent(parl.Agent):
def __init__(self, algorithm, obs_dim, act_dim):
self.obs_dim = obs_dim
self.act_dim = act_dim
super(Agent, self).__init__(algorithm) def build_program(self):
self.pred_program = fluid.Program()
self.learn_program = fluid.Program() with fluid.program_guard(self.pred_program): # 搭建计算图用于 预测动作,定义输入输出变量
obs = layers.data(
name='obs', shape=[self.obs_dim], dtype='float32')
self.act_prob = self.alg.predict(obs) with fluid.program_guard(
self.learn_program): # 搭建计算图用于 更新policy网络,定义输入输出变量
obs = layers.data(
name='obs', shape=[self.obs_dim], dtype='float32')
act = layers.data(name='act', shape=[1], dtype='int64')
reward = layers.data(name='reward', shape=[], dtype='float32')
self.cost = self.alg.learn(obs, act, reward)
def sample(self, obs):
obs = np.expand_dims(obs, axis=0) # 增加一维维度
act_prob = self.fluid_executor.run(
self.pred_program,
feed={'obs': obs.astype('float32')},
fetch_list=[self.act_prob])[0]
act_prob = np.squeeze(act_prob, axis=0) # 减少一维维度
act = np.random.choice(range(self.act_dim), p=act_prob) # 根据动作概率选取动作
return act
#self.fluid_executor.run训练器是一个batch训练的,所以要输入时增加一维输出减少一维
def predict(self, obs):
obs = np.expand_dims(obs, axis=0)
act_prob = self.fluid_executor.run(
self.pred_program,
feed={'obs': obs.astype('float32')},
fetch_list=[self.act_prob])[0]
act_prob = np.squeeze(act_prob, axis=0)
act = np.argmax(act_prob) # 根据动作概率选择概率最高的动作
return act def learn(self, obs, act, reward):
act = np.expand_dims(act, axis=-1)
feed = {
'obs': obs.astype('float32'),
'act': act.astype('int64'),
'reward': reward.astype('float32')
}
cost = self.fluid_executor.run(
self.learn_program, feed=feed, fetch_list=[self.cost])[0]
return cost
- tarin
def main():
env = gym.make('CartPole-v0')
# env = env.unwrapped # Cancel the minimum score limit
obs_dim = env.observation_space.shape[0]
act_dim = env.action_space.n
logger.info('obs_dim {}, act_dim {}'.format(obs_dim, act_dim))
# 根据parl框架构建agent
model = Model(act_dim=act_dim)
alg = PolicyGradient(model, lr=LEARNING_RATE)
agent = Agent(alg, obs_dim=obs_dim, act_dim=act_dim)
# 加载模型
# if os.path.exists('./model.ckpt'):
# agent.restore('./model.ckpt')
# run_episode(env, agent, train_or_test='test', render=True)
# exit()
for i in range(1000):
obs_list, action_list, reward_list = run_episode(env, agent)
if i % 10 == 0:
logger.info("Episode {}, Reward Sum {}.".format(
i, sum(reward_list)))
batch_obs = np.array(obs_list)
batch_action = np.array(action_list)
batch_reward = calc_reward_to_go(reward_list)
agent.learn(batch_obs, batch_action, batch_reward)
if (i + 1) % 100 == 0:
total_reward = evaluate(env, agent, render=True)
logger.info('Test reward: {}'.format(total_reward))
# save the parameters to ./model.ckpt
agent.save('./model.ckpt')
batch_reward = calc_reward_to_go(reward_list) 把reward转变为G_t ,得到所有episode数据后, learn一下计算期望。run_episode计算一次知道done为true,evaluate计算5次episode求平均。
2.1.3 调试结果
?[32m[03-22 15:38:26 MainThread @train.py:95]?[0m Episode 800, Reward Sum 118.0.
?[32m[03-22 15:38:29 MainThread @train.py:95]?[0m Episode 810, Reward Sum 177.0.
?[32m[03-22 15:38:32 MainThread @train.py:95]?[0m Episode 820, Reward Sum 86.0.
?[32m[03-22 15:38:37 MainThread @train.py:95]?[0m Episode 830, Reward Sum 200.0.
?[32m[03-22 15:38:40 MainThread @train.py:95]?[0m Episode 840, Reward Sum 200.0.
?[32m[03-22 15:38:44 MainThread @train.py:95]?[0m Episode 850, Reward Sum 59.0.
?[32m[03-22 15:38:48 MainThread @train.py:95]?[0m Episode 860, Reward Sum 61.0.
?[32m[03-22 15:38:52 MainThread @train.py:95]?[0m Episode 870, Reward Sum 156.0.
?[32m[03-22 15:38:57 MainThread @train.py:95]?[0m Episode 880, Reward Sum 99.0.
?[32m[03-22 15:39:00 MainThread @train.py:95]?[0m Episode 890, Reward Sum 16.0.
?[32m[03-22 15:39:22 MainThread @train.py:104]?[0m Test reward: 200.0
?[32m[03-22 15:39:23 MainThread @train.py:95]?[0m Episode 900, Reward Sum 165.0.
?[32m[03-22 15:39:27 MainThread @train.py:95]?[0m Episode 910, Reward Sum 141.0.
?[32m[03-22 15:39:32 MainThread @train.py:95]?[0m Episode 920, Reward Sum 200.0.
?[32m[03-22 15:39:37 MainThread @train.py:95]?[0m Episode 930, Reward Sum 200.0.
?[32m[03-22 15:39:42 MainThread @train.py:95]?[0m Episode 940, Reward Sum 200.0.
?[32m[03-22 15:39:47 MainThread @train.py:95]?[0m Episode 950, Reward Sum 200.0.
?[32m[03-22 15:39:52 MainThread @train.py:95]?[0m Episode 960, Reward Sum 113.0.
?[32m[03-22 15:39:58 MainThread @train.py:95]?[0m Episode 970, Reward Sum 152.0.
?[32m[03-22 15:40:03 MainThread @train.py:95]?[0m Episode 980, Reward Sum 200.0.
?[32m[03-22 15:40:09 MainThread @train.py:95]?[0m Episode 990, Reward Sum 180.0.
?[32m[03-22 15:40:30 MainThread @train.py:104]?[0m Test reward: 200.0可以看到在训练过程得到的reward 分值不高是因为 选取动作采用随机性,但是在检验的时候是选择概率最大的动作所以reward最大。随这参数迭代,训练选择最大动作概率也会越来越大。
【七】强化学习之Policy Gradient---PaddlePaddlle【PARL】框架{飞桨}的更多相关文章
- 深度学习-深度强化学习(DRL)-Policy Gradient与PPO笔记
Policy Gradient 初始学习李宏毅讲的强化学习,听台湾的口音真是费了九牛二虎之力,后来看到有热心博客整理的很细致,于是转载来看,当作笔记留待复习用,原文链接在文末.看完笔记再去听一听李宏毅 ...
- 强化学习算法Policy Gradient
1 算法的优缺点 1.1 优点 在DQN算法中,神经网络输出的是动作的q值,这对于一个agent拥有少数的离散的动作还是可以的.但是如果某个agent的动作是连续的,这无疑对DQN算法是一个巨大的挑战 ...
- 深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO)
深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO) 2018-07-17 16:54:51 Reference: https://b ...
- 告别炼丹,Google Brain提出强化学习助力Neural Architecture Search | ICLR2017
论文为Google Brain在16年推出的使用强化学习的Neural Architecture Search方法,该方法能够针对数据集搜索构建特定的网络,但需要800卡训练一个月时间.虽然论文的思路 ...
- Deep Learning专栏--强化学习之从 Policy Gradient 到 A3C(3)
在之前的强化学习文章里,我们讲到了经典的MDP模型来描述强化学习,其解法包括value iteration和policy iteration,这类经典解法基于已知的转移概率矩阵P,而在实际应用中,我们 ...
- 强化学习--Actor-Critic---tensorflow实现
完整代码:https://github.com/zle1992/Reinforcement_Learning_Game Policy Gradient 可以直接预测出动作,也可以预测连续动作,但是无 ...
- 强化学习--QLearning
1.概述: QLearning基于值函数的方法,不同与policy gradient的方法,Qlearning是预测值函数,通过值函数来选择 值函数最大的action,而policy gradient ...
- 基于Keras的OpenAI-gym强化学习的车杆/FlappyBird游戏
强化学习 课程:Q-Learning强化学习(李宏毅).深度强化学习 强化学习是一种允许你创造能从环境中交互学习的AI Agent的机器学习算法,其通过试错来学习.如上图所示,大脑代表AI Agent ...
- 强化学习(十七) 基于模型的强化学习与Dyna算法框架
在前面我们讨论了基于价值的强化学习(Value Based RL)和基于策略的强化学习模型(Policy Based RL),本篇我们讨论最后一种强化学习流派,基于模型的强化学习(Model Base ...
- [Reinforcement Learning] 强化学习介绍
随着AlphaGo和AlphaZero的出现,强化学习相关算法在这几年引起了学术界和工业界的重视.最近也翻了很多强化学习的资料,有时间了还是得自己动脑筋整理一下. 强化学习定义 先借用维基百科上对强化 ...
随机推荐
- 阿里云的“终端云化”实践,基于ENS进行边缘架构构建
终端无休止的更新迭代,是软件对计算资源的需求激增. 作者|王广芳 编辑|IMMENSE 终端云化:打破硬件的桎梏 近几年,"终端云化"技术开始规模化落地,其核心思想是"计 ...
- MVVM架构
一.MVVM架构和Jetpack MVVM即Model-View-ViewModel的缩写,它的出现是为了将图形界面和业务逻辑,数据模型进行解耦.在前面章节所学习的Jetpack组件,大部分是为了能够 ...
- Codeforces Round #629 (Div. 3) & 19级暑假第六场训练赛
A:Codeforces 1328A Divisibility Problem 整除+模 Input 5 10 4 13 9 100 13 123 456 92 46 Output 2 5 4 333 ...
- liunx基础概述
一.liunx起源 1.1991,芬兰研究生Liunus Torvalds编写了liunx的代码,并上传到互联网 2.Liunx基于UNIX,但是有别与UNIX 3.Liunx的软件产品使用了社区开发 ...
- Chrome 控制台 换行编写js调试代码
转载请注明出处: 在 chrome 浏览器的console 控制台编写 js 调试或验证代码时,每输一行换行时,就会执行当前行的函数,再重新换行输入时,就会将之前的代码忽略,这种方式就会导致 chro ...
- 最新版TikTok 抖音国际版解锁版 v33.1.4 去广告 免拔卡
软件简介: 抖音国际版App是全球最受欢迎的短视频应用,抖音国际版TikTok(海外版)横扫全球下载量常居榜首.这是最新抖音国际版解锁版,无视封锁和下载限制,国内免拔卡,去除了广告,下载视频无水印(T ...
- [转帖]OS、PFS、DFS 有啥区别?一文搞懂 6 大临床试验终点
https://oncol.dxy.cn/article/670607 说到肿瘤临床研究,就不得不说临床试验终点(End Point),比如大家熟知的 OS.PFS.ORR 还有 DFS.TTP.TT ...
- [转帖]如何查看Docker容器环境变量,如何向容器传递环境变量
https://www.cnblogs.com/larrydpk/p/13437535.html 1 前言 欢迎访问南瓜慢说 www.pkslow.com获取更多精彩文章! 了解Docker容器的运行 ...
- idb单副本时-TiKV节点损坏后有损数据恢复的方法
Tidb单副本时-TiKV节点损坏后有损数据恢复的方法 背景 UAT环境下,为了减少存储. 搭建了一套单副本的TiDB集群 但是随着数据量的增多, UAT上面的数据可以丢失,但是表结构等信息是无法接受 ...
- [转帖]LSM-Tree:从入门到放弃——入门:基本概念、操作和Trade-Off分析
https://zhuanlan.zhihu.com/p/428267241 LSM-Tree,全程为日志结构合并树,有趣的是,这个数据结构实际上重点在于日志结构合并,和 tree 本身的关系并不是特 ...