无惧百万级并发,GaussDB(for Cassandra)让华为推送服务更快触达
摘要:推送服务(Push Kit)是华为提供的消息推送平台,建立了从云端到终端的消息推送通道。通过集成推送服务,您可以向客户端应用实时推送消息,让应用更精准触达用户,是开发者提升用户感知度和活跃度的一件利器。
本文分享自华为云社区《无惧百万级并发,GaussDB(for Cassandra)让华为Push推送服务更快触达》,作者:GaussDB 数据库。
推送服务(Push Kit)是华为提供的消息推送平台,建立了从云端到终端的消息推送通道。通过集成推送服务,您可以向客户端应用实时推送消息,让应用更精准触达用户,是开发者提升用户感知度和活跃度的一件利器。
华为云GaussDB(for Cassandra) 是一款基于计算存储分离架构的分布式数据库,致力于提供稳定可靠、超高并发,兼容Cassandra生态、弹性伸缩、一键部署、快速恢复、监控告警的分布式数据库服务,在Push业务的高效架构建设中,起到了关键的作用。
业务挑战
Push服务能够协助开发者快速触达用户,其提供的系统级通道推送速度每秒最高可达百万级,消息量每日百亿级,并且支持实时消息回执。如此高到达率的背后,是因为Push使用了大量分布式架构、高性能队列、大数据分析、数据库、AI等技术,用来支撑实时推送、精准送达业务的高效开展。
Push的主要业务链路是发送上行消息和下行消息,接下来我们从发送下行消息流程来了解业务在哪些场景上用到了数据库,以及对数据库的要求有哪些?
下行消息交互图如下所示:
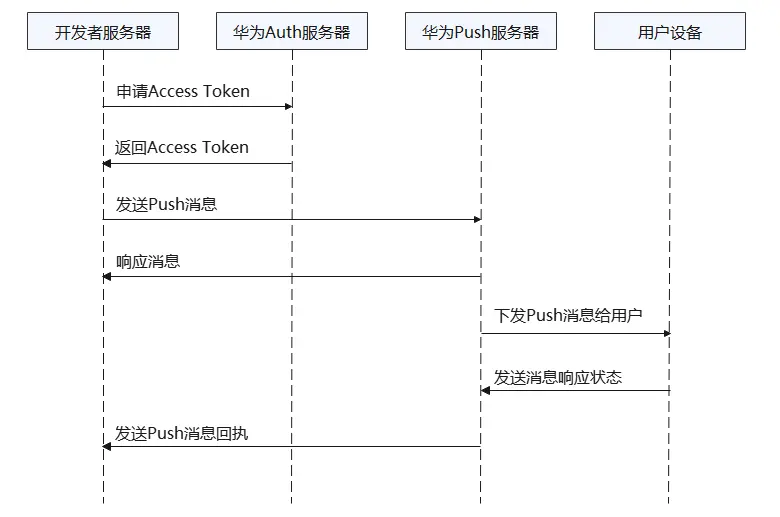
当用户设备网络条件良好且不拥堵的情况下,华为Push服务器在收到消息后,会先将消息存入高性能队列中,然后队列消费消息发送给用户设备。但是当用户设备处于弱网、网络异常,或不在线、熄屏状态时,消息无法到达设备,或此时发送消息价值较低。Push业务为了保障消息不丢失,以及提升消息的有效率,利用数据库为底座,来支持离线消息缓存能力。
离线消息缓存是指当消息到达华为Push平台后,如果设备不在线,华为Push平台会将消息缓存起来,等到设备上线后,华为Push平台会将缓存的消息再次推送给用户。如果用户很长时间不在线,这些缓存的消息默认保存24小时,最长保存15天,超期的消息会被Push平台丢弃。
此时,在数据库的选型上就需要考虑以下几个问题:
- 推送速度每秒百万级,极端场景下,大部分写入数据库,会有每秒百万写入请求,数据库需要具备超高的写入能力;
- 当设备恢复正常状态时,消息会从数据库中读出发送给用户,消息的实时性会直接影响到消息的价值,此时就要求数据库的读时延低且长尾时延稳定;
- 推送的消息中,多与时事热点相关,容易引发流量突增,且不可预知,这就要求数据库具有快速弹性伸缩的能力;
- 为达成AI智能推送的能力,可能需要对数据库中的数据进行数据挖掘和分析,从而实施智能推送策略,数据库需支持与主流大数据引擎兼容的接口和解决方案。
为什么选择GaussDB(for Cassandra)?
基于以上挑战,Push业务经过一系列技术选型,最终选择了GaussDB(for Cassandra)数据库。GaussDB(for Cassandra)凭借丰富强大的特性,可以帮助Push业务很好地应对消息缓存的挑战:
- 从请求量上看,GaussDB(for Cassandra)轻松支持千万级并发访问,高并发不在话下;
- 从时延上看,GaussDB(for Cassandra)除了本身具备超低时延的能力外,在并发量大的情况下,可通过扩容和规格变更,增加分区和负载均衡保证业务时延基本无变化;
- 从弹性伸缩上看,GaussDB(for Cassandra)基于存算分离架构,支持秒级存储扩容,分钟级计算扩容,轻松应对流量高峰;
- 从兼容能力看,GaussDB(for Cassandra)支持CQL语法和灵活的数据定义,同时兼容主流的批式/流式处理引擎(Spark/Flink等),且提供动态增量+全量的解决方案,供大数据分析引擎接入,充分满足不同类型数据的接入需求。
如何利用GaussDB(for Cassandra)提升消息缓存体验
下面,我们将从具体的几个技术改进来聊聊,GaussDB(for Cassandra)是如何帮助Push业务获得更好的消息缓存体验。
降本增效
- 降低Push集群对数据库请求量:
- 表结构设计时,将同一用户设备的多条信息存入同一partition中
- 在读取时,可使用范围查询将同一用户设备的多条信息批量查出,且时延较低
- 在写入时,使用Batch写入,降低客户端与数据库的交互次数
- 降低存储使用量:业务科通过TTL、范围删除、单行删除等多种手段,根据业务情况灵活使用达到数据消亡的目的,降低存储用量。
弹性伸缩,热点无忧
每当出现重大新闻,各大应用均产生了海量的推送消息,Push业务收到消息后,流量激增,集群规模难以支撑巨大的流量。但依靠GaussDB(for Cassandra)的快速扩容能力,Push业务实现了分钟级别的计算扩容,业务不受影响,而且当流量回归正常后,可以进行缩容降低成本。
超强可靠性,底座无忧
GaussDB(for Cassandra)不仅在读写性能上表现优异,在数据可靠性上也表现突出。因为采用多节点分布式架构,当任意盘或节点出现故障,读写操作会自动切换至其他节点,理论上可以达到N-1个节点故障容忍,即集群任一节点存活即可提供完整服务。同时还支持异地双活,实现业务恢复和故障恢复解耦,Region级高可用。
综上所述,GaussDB(for Cassandra) 为Push业务提供了高效、稳定、安全的数据库底座,助力Push业务实现了离线消息缓存架构。我们相信,借助GaussDB(for Cassandra), Push业务在消息推送领域,会为开发者提供更优质的服务和工具,助力企业提升业务价值和用户体验。
无惧百万级并发,GaussDB(for Cassandra)让华为推送服务更快触达的更多相关文章
- 总结:如何使用redis缓存加索引处理数据库百万级并发
前言:事先说明:在实际应用中这种做法设计需要各位读者自己设计,本文只提供一种思想.准备工作:安装后本地数redis服务器,使用mysql数据库,事先插入1000万条数据,可以参考我之前的文章插入数据, ...
- 使用redis缓存加索引处理数据库百万级并发
使用redis缓存加索引处理数据库百万级并发 前言:事先说明:在实际应用中这种做法设计需要各位读者自己设计,本文只提供一种思想.准备工作:安装后本地数redis服务器,使用mysql数据库,事先插入1 ...
- Netty系列之Netty百万级推送服务设计要点
1. 背景 1.1. 话题来源 最近很多从事移动互联网和物联网开发的同学给我发邮件或者微博私信我,咨询推送服务相关的问题.问题五花八门,在帮助大家答疑解惑的过程中,我也对问题进行了总结,大概可以归纳为 ...
- Netty_Netty系列之Netty百万级推送服务设计要点
1. 背景 1.1. 话题来源 最近很多从事移动互联网和物联网开发的同学给我发邮件或者微博私信我,咨询推送服务相关的问题.问题五花八门,在帮助大家答疑解惑的过程中,我也对问题进行了总结,大概可以归纳为 ...
- 【netty】Netty系列之Netty百万级推送服务设计要点
1. 背景 1.1. 话题来源 最近很多从事移动互联网和物联网开发的同学给我发邮件或者微博私信我,咨询推送服务相关的问题.问题五花八门,在帮助大家答疑解惑的过程中,我也对问题进行了总结,大概可以归纳为 ...
- Netty系列之Netty百万级推送服务设计要点(转)
1. 背景 1.1. 话题来源 最近很多从事移动互联网和物联网开发的同学给我发邮件或者微博私信我,咨询推送服务相关的问题.问题五花八门,在帮助大家答疑解惑的过程中,我也对问题进行了总结,大概可以归纳为 ...
- Netty学习总结(3)——Netty百万级推送服务
1. 背景 1.1. 话题来源 最近很多从事移动互联网和物联网开发的同学给我发邮件或者微博私信我,咨询推送服务相关的问题.问题五花八门,在帮助大家答疑解惑的过程中,我也对问题进行了总结,大概可以归纳为 ...
- Worktile中百万级实时消息推送服务的实现
Worktile中百万级实时消息推送服务的实现 出自:http://blog.jobbole.com/81125/
- dns 服务架构优化 - 百万级并发不是梦 - bind+namedmanager+dnsmasq
bind: DNS服务端. namedmanager: DNS web管理页面. dnsmasq: 并发查询上游dns域名解析. 问题:作为消息推送业务,单台业务机器域名解析并发达到上万次.业务机器集 ...
- 【Java并发工具类】StampedLock:比读写锁更快的锁
前言 ReadWriteLock适用于读多写少的场景,允许多个线程同时读取共享变量.但在读多写少的场景中,还有更快的技术方案.在Java 1.8中, 提供了StampedLock锁,它的性能就比读写锁 ...
随机推荐
- 单元测试之Mockito+Junit使用和总结
https://www.letianbiji.com/java-mockito/mockito-thenreturn.html Mockito 使用 thenReturn 设置方法的返回值 thenR ...
- Java系列:Java8 新特性:强大的 Stream API(创建 Stream、中间操作、终止操作)
Java8中有两大最为重要的改变.第一个是 Lambda 表达式:另外一个则是 Stream API. Stream API ( java.util.stream) 把真正的函数式编程风格引入到Jav ...
- SNN_文献阅读_Spiking neural networks, an introduction
Spiking neural networks, an introduction 脉冲神经网络的生物学背景+两种采用脉冲编码的神经元模型 概论 本文介绍了脉冲神经网络的生物学背景,并将介绍两种采用脉冲 ...
- 请问您今天要来点 ODT 吗
梗出处:请问您今天要来点兔子吗? 这篇文章主要记录一下自己学习 \(\text{ODT}\) 发生的种种. CF896C Willem, Chtholly and Seniorious \(\text ...
- 如何通过 wireshark 捕获 C# 上传的图片
一:背景 1. 讲故事 这些天计划好好研究下tcp/ip,以及socket套接字,毕竟工控中设计到各种交互协议,如果只是模模糊糊的了解,对分析此类dump还是非常不利的,而研究协议最好的入手点就是用抓 ...
- Java——面向对象(static关键字开始)
一.static 可以修饰成员变量和成员方法 关键字特点: 随着类的加载而加载: 优先于对象存在: 被类的所有对象共享: 可以通过类名直接调用: 注意事项: 在静态方法中是没有this关键字的 静态的 ...
- SQL与NoSQL数据库选型及实际业务场景探讨
在企业系统架构设计中,选择合适的数据库类型是一项关键决策.本文将对比SQL和NoSQL数据库的特点,分析它们在数据模型.可扩展性.一致性与事务.查询复杂性与频率,以及性能与延迟等方面的优势和劣势.同时 ...
- 常用【描述性统计指标】含义(by python)
统计学有时候会被误解,好像必须有大量的样本数据,才能使统计结果有意义.这会让我们觉得统计学离我们的日常生活很遥远. 其实,如果数据的准确度高的话,少量的样本数据同样能反映出真实的情况.比如,很多国家选 ...
- Linux MIPI 调试中常见的问题
一.概述 做嵌入式工作的小伙伴知道,有时候程序编写没有调试过程中费时,之间笔记里有 MIPI 摄像头驱动开发的过程,有需要的小伙伴可以参考:Linux RN6752 驱动编写. 而我也是第一次琢磨 M ...
- 洛谷2151 [SDOI2009]HH去散步(矩阵快速幂,边点互换)
题意:HH有个一成不变的习惯,喜欢饭后百步走.所谓百步走,就是散步,就是在一定的时间 内,走过一定的距离. 但是同时HH又是个喜欢变化的人,所以他不会立刻沿着刚刚走来的路走回. 又因为HH是个喜欢变化 ...