Hybrid-PSC:基于对比学习的混合网络,解决长尾图片分类 | CVPR 2021
论文提出新颖的混合网络用于解决长尾图片分类问题,该网络由用于图像特征学习的对比学习分支和用于分类器学习的交叉熵分支组成,在训练过程逐步将训练权重调整至分类器学习,达到更好的特征得出更好的分类器的思想。另外,为了节省内存消耗,论文提出原型有监督对比学习。从实验结果来看,论文提出的方法效果还是很不错的,值得一看
来源:晓飞的算法工程笔记 公众号
论文: Contrastive Learning based Hybrid Networks for Long-Tailed Image Classification

Introduction
在实际场景中,图片类别通常都会呈现长尾分布,不常见的类别通常由于数据不足而无法被充分学习,给分类器的学习带来巨大的挑战。当前大多研究都通过减轻尾部类别的数据短缺来应对数据不平衡的问题,防止模型被头部类别控制,如数据重采样和数据增强等。
最近,有新的研究提出将长尾数据分类问题分解为特征学习和分类器学习两个阶段,认为这两个阶段适用不同的数据采样策略进行学习,比如随机采样更适合特征学习,而类别平衡采样更适合分类器学习。
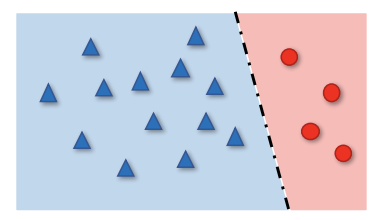
但有一点需要注意的是,上述两类研究都没有考虑到,在数据不平衡场景下,交叉熵损失是否仍为特征学习的理想损失函数。交叉熵损失学习到的特征分布可能会高度倾斜,如上图所示,导致分类器存在偏向性,会影响长尾分类。
为此,论文研究了高效的对比学习策略,将其适配到不平衡数据中学习特征表达,提高长尾图片分类场景的性能。论文采用了新颖的混合网络结构,由用于特征表达学习的对比损失和用于分类器学习的交叉熵损失组成。两个损失联合训练,在训练过程中逐渐调整两个损失的权重,从特征学习逐步转移为分类器学习,遵循更好的特征产生更好的分类器的思想。
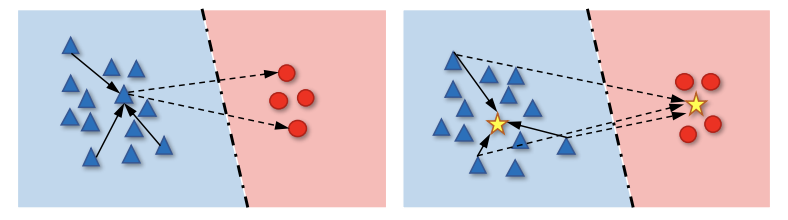
论文一开始采用从无监督对比(UC)中延伸出来的有监督对比(SC)损失用于特征学习,该损失使用batch内的样本进行相互对比,通过区分负样本来优化正样本间的一致性,如图左所示。如果想要保证优化效果,需要确保对比的正样本够多以及负样本覆盖足够多的类别,通常需要使用较大的batch,导致内存消耗过多。为了解决这个问题,论文提出了原型有监督对比(PSC)学习策略,从batch内的样本间对比改为batch内的样本与额外维护的原型进行对比,如图右所示。在保持原本有监督对比的特性的情况下,原型有监督对比避免了过多的内存消耗,还能使数据采样更灵活和高效。
论文的主要贡献如下:
- 提出用于长尾数据分类的混合网络结构,由用于特征表达学习的对比损失和用于分类器学习的交叉熵损失组成。在训练过程中逐渐调整两个损失的权重,从特征学习逐步转移为分类器学习,遵循更好的特征产生更好的分类器的思想。
- 研究高效的有监督对比学习策略用于更优的特征学习,提高长尾分类性能。另外,论文提出原型有监督对比来解决标准有监督对比的内存问题。
- 验证在长尾分类场景中,有监督对比学习能更好地替代交叉熵损失进行特征学习。得益于学习到更好的特征,论文提出的混合网络能够极大地超越基于交叉熵的网络。
Contrastive learning
Unsupervised contrastive
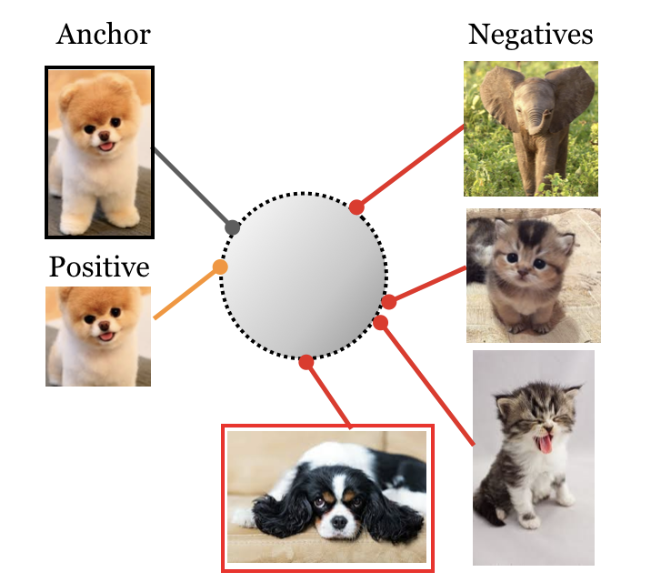
无监督对比学习在无标签的场景下,通过同源图片与非同源图片之间的特征对比来进行特征表达的学习。比如先随机选取n张原图片,经过数据增强后变成2n张图片组成batch,将同源副本相互认为正样本、非同源副本认为负样本进行距离学习。
Supervised contrastive
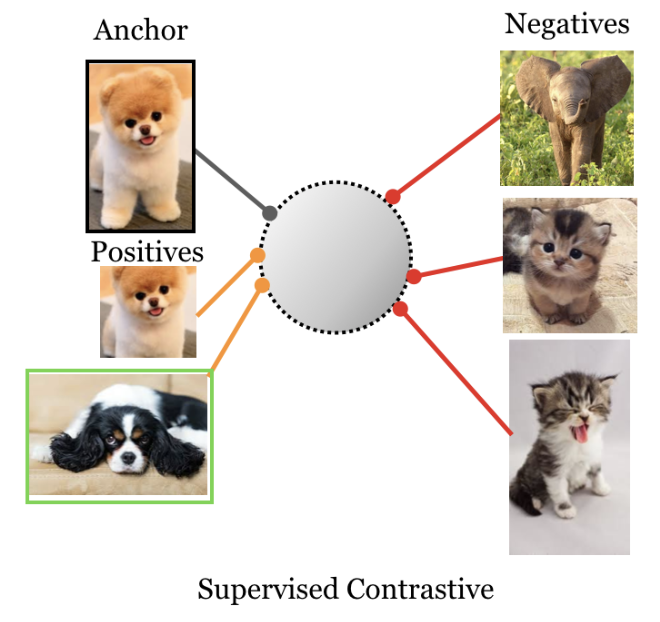
有监督对比学习主在有标签的场景下,通过同类别图片与非同类别图片之间的特征对比来进行特征表达的学习。有监督对比学习也是需要进行数据增强生成同源副本的,所以正样本包含同源副本和同类别副本。比如选取n张原图片,经过数据增强后变成2n张图片组成batch,将同类图片相互认为正样本、非同类图片认为负样本进行距离学习。这里的n张图片选取不能随机选,为达到有监督的目的,同类别图片要大于1张。
Main Approach
A Hybrid Framework for Long-tailed Classification

论文提出的用于长尾图像分类的混合框架如上图所示,包含两个分支:
- 用于图像特征学习的对比学习分支,构造同类内聚、异类分离的特征空间。
- 用于分类器学习的交叉熵分支,基于对比学习分支得到的显著特征学习类别偏向较少的分类器。
为了达到用更好的特征帮助分类器进行学习,从而得到更通用的分类器的目的。论文参考了BBN的双分支联合训练方法,在训练阶段逐步调整这两个分支的权重。在训练初期以特征学习作为主导,随着训练的进行,分类器学习逐级主导训练。
主干网络在分支间共享,共同帮助主干网络学习每个图片的特征\(r\in\mathcal{R}^{D_E}\)。两个分支分别进行不同的操作:
- 对比学习分支先通过MLP层\(f_e(\cdot)\)将图片特征\(r\)映射成向量表达\(z\in\mathcal{R}^{D_S}\),适配后续对比损失函数的计算。另外,这样的特征向量化转换也有助于提升前一层的特征质量。随后,对特征\(z\)进行\(\mathcal{l}_2\)归一化,使其能够用于距离计算。最后,使用输出的归一化特征计算有监督对比损失\(\mathcal{L}_{SCL}\)。
- 分类器学习分支先通过单个线性层从图像特征\(r\)预测类别结果\(s\in\mathcal{R}^{D_C}\),随后直接计算交叉熵损失\(\mathcal{L}_{CE}\)。
需要注意的是,为了适应其损失函数的特性,两个分支的数据采样方式是不同的。特征学习分支需要附带样本\(x_i\)的同类正样本\(\{x^{+}_i\}=\{x_j|y_i=y_j,i\ne j\}\)和异类负样本\(\{x^{-}_i\}=\{x_j|y_i=y_j,i\ne j\}\),组成单个batch输入\(\mathcal{B}_{SC}=\{x_i, \{x^{+}_i\}, \{x^{-}_i\}\}\),而分类器学习分支则直接输入图片和标签\(\mathcal{B}_{CE}=\{\{x_i, y_i\}\}\)即可。
混合网络的最终损失函数为:
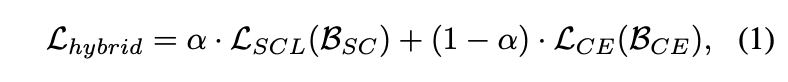
\(\alpha\)是权重因子,与周期数成反相关。
Supervised contrastive loss and its memory issue
有监督对比损失(supervised contrastive loss, SC loss)是对无监督对比损失(unsupervised contrastive loss, UC loss)的扩展,区别在于单batch内的正负样本构成。假设目标图片的正负样本的向量特征为\(\{z^{+}_i\}\)和\(\{z^{-}_i\}\),对于大小为N的minibatch,SC loss的计算为:
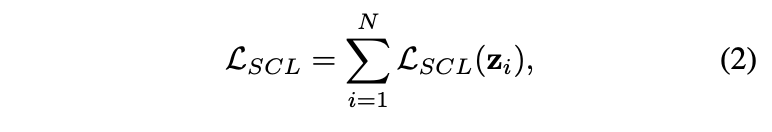
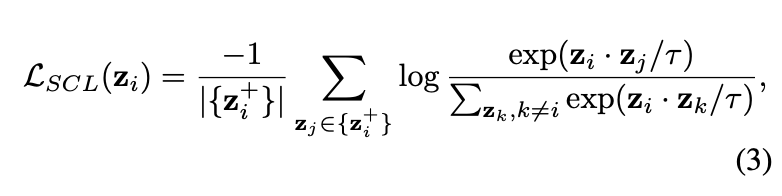
相对于UC loss,SC loss可采用任意数量的正样本。由于对比损失是通过区分负样本来优化正样本间的一致性,所以负样本数量十分重要的,而SC损失加入同类图片作为正样本,为保证负样本数量而不得不成倍地增加batch大小,导致内存消耗成倍地增加,导致内存消耗的成倍地增加,限制了SC loss的使用场景。
一个解决内存消耗的做法就是缩小负样本数量,但这样在类别数多的场景下会有问题。负样本数小意味着只能采样到少量负样本类别,肯定会影响学到的特征质量。
Prototypical supervised contrastive loss
为了同时兼顾内存消耗和特征质量,论文提出了原型有监督对比损失(prototypical supervised contrastive loss, PSC loss),为每个类别学习一个原型,强迫每个图片的数据增强副本尽量靠近其所属类别的原型以及远离其他类别的原型。使用原型有两个好处:1)允许更灵活的数据采样方式,不再需要显示地控制正负样本,可使用随机采样或类别平衡采样。2)数据采样更高效,假设有\(\mathcal{C}\)类别,则每次采样保证都有\(\mathcal{C}-1\)个负样本,这对于类别多的数据集特别重要。
PSC loss的计算如下:
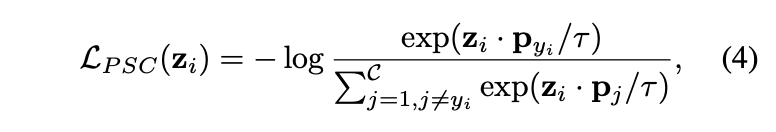
\(p_{ij}\)是类别\(y_i\)的原型特征,归一化为\(\mathcal{R}^{D_S}\)下的单位超球面,即满足L2归一化。这里没有提到原型是如何初始化和学习的,需要等源码放出来再看看。
PSC loss也可以延伸为每个类别多个原型,主要为了迎合单类别可能存在有多种数据分布的情况。多原型有监督对比损失(multiple prototype supervised contrastive loss, MPSC loss)的计算为:
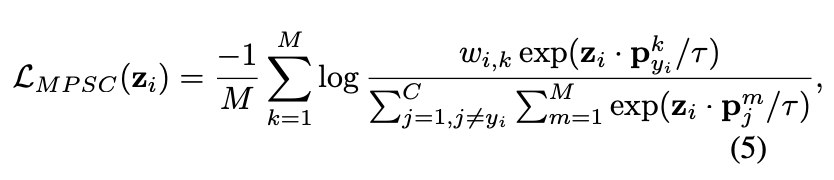
\(M\)为每个类别的原型数,\(p^i_j\)为类别j的第\(i\)个原型,\(w_{i,k}(w_{i,k}\ge 0,{\sum}^M_{k=1})w_{i,k}=1\)为\(z_i\)与第\(k\)个原型之间的关系值,用于更细粒度地控制每个样本,这将会在未来的工作中进行进一步地验证。
Experiment
Datasets
论文主要在三个长尾图片分类数据集进行实验:
- Long-tailed CIFAR-10和CIFAR-100:原版的CIFAR数据集是平衡的,通过减少每个类别的图片数来生成长尾版本,注意验证集不变。用一个不平衡比例\(\beta=N_{max}/N_{min}\)来表示生成的长尾数据集的不平衡程度。
- iNaturalist 2018:iNaturalist 2018是一个大型的生物品种数据集,包含8142个品种、437513张训练图片以及24424张验证图片。
Implementation details
对于长尾CIFAR数据集和iNaturalist数据集,论文使用了不同的实验配置:
- Implementation details for long-tailed CIFAR:混合网络使用ResNet-32作为主干,两个分支共享的数据增强方法有:\(32\times 32\)的随机裁剪、水平翻转以及概率为0.2的随机灰度。另外,PSC loss也跟随SC loss使用额外的数据增强方法。在实验中,论文简单地使用有颜色扰动和无颜色扰动的图片作为数据增强副本对,batch size为512,使用momentum=0.9、weight decay=\(1\times 10^{-4}\)的SGD优化器。网络共训练200个周期,学习率初始为0.5并在第120周期和160周期下降10倍。权重因子\(\alpha=1-(T/T_{max})^2\)与周期数成抛物线衰减。对于SC loss,公式3的\(\tau\)固定为0.1,而对于PSC loss,在CIFAR-10和CIFAR-100上分别设置为1和0.1。
- Implementation details for iNaturalist 2018:混合网络使用ResNet-50作为主干网络,数据增强跟长尾CIFAR一样,只是随机裁剪的图片大小为\(224\times 224\),batch size为100。网络共训练100轮,使用momentum=0.9、weight decay=\(1\times 10^{-4}\)的SGD优化器,学习率初始为0.05并在第60周期和第80周期下降10倍。考虑这个数据集的类别多,学习器训练较难,权重因子\(\alpha=1-T/T_{max}\)设置为线性下降,公式3的\(\tau\)固定为0.1。对于SC loss,正样本数固定为2。
Result
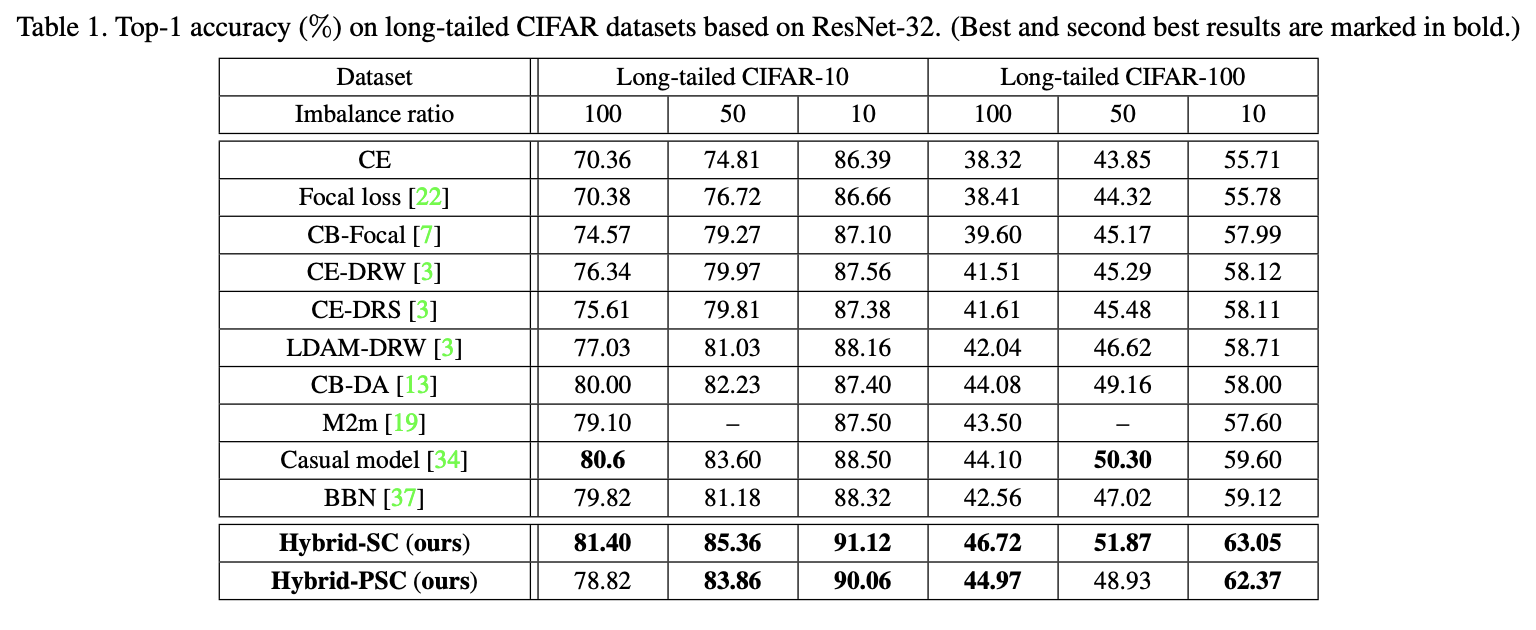
长尾CIFAR上的结果对比。
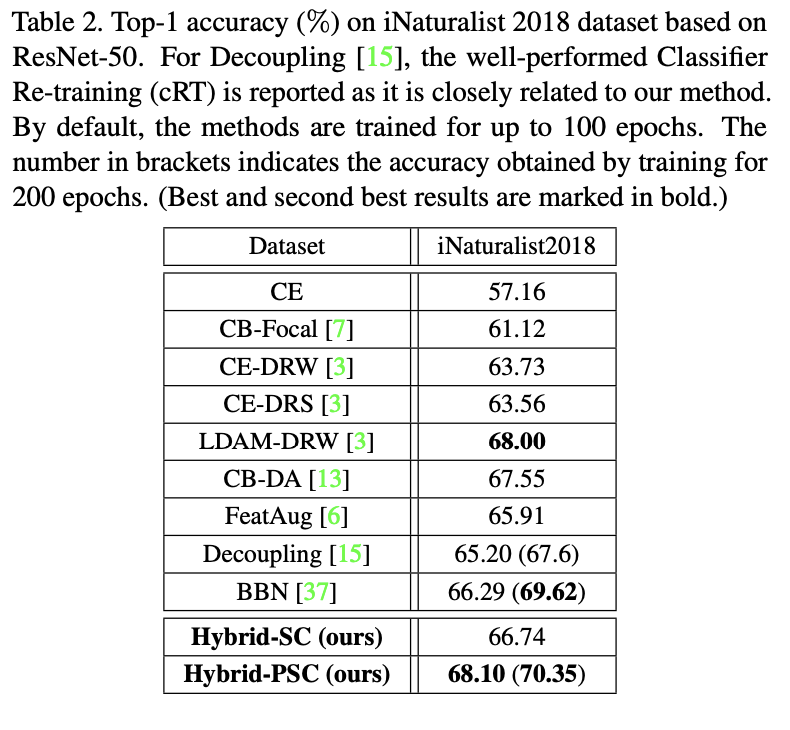
iNaturalist 2018上的结果对比。
Conclusion
论文提出新颖的混合网络用于解决长尾图片分类问题,该网络由用于图像特征学习的对比学习分支和用于分类器学习的交叉熵分支组成,在训练过程逐步将训练权重从特征学习调整至分类器学习,遵循更好的特征可得出更好的分类器的思想。另外,为了节省内存消耗,论文提出原型有监督对比学习。从实验结果来看,论文提出的方法效果还是很不错的,值得一看。
参考内容
- [Supervised Contrastive Learning
-Prannay Khosla
](https://arxiv.org/abs/2004.11362)
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

Hybrid-PSC:基于对比学习的混合网络,解决长尾图片分类 | CVPR 2021的更多相关文章
- 机器学习框架ML.NET学习笔记【6】TensorFlow图片分类
一.概述 通过之前两篇文章的学习,我们应该已经了解了多元分类的工作原理,图片的分类其流程和之前完全一致,其中最核心的问题就是特征的提取,只要完成特征提取,分类算法就很好处理了,具体流程如下: 之前介绍 ...
- 体验AI乐趣:基于AI Gallery的二分类猫狗图片分类小数据集自动学习
摘要:直接使用AI Gallery里面现有的数据集进行自动学习训练,很简单和方便,节约时间,不用自己去训练了,AI Gallery 里面有很多类似的有趣数据集,也非常好玩,大家一起试试吧. 本文分享自 ...
- 基于深度学习的安卓恶意应用检测----------android manfest.xml + run time opcode, use 深度置信网络(DBN)
基于深度学习的安卓恶意应用检测 from:http://www.xml-data.org/JSJYY/2017-6-1650.htm 苏志达, 祝跃飞, 刘龙 摘要: 针对传统安卓恶意程序检测 ...
- 基于深度学习和迁移学习的识花实践——利用 VGG16 的深度网络结构中的五轮卷积网络层和池化层,对每张图片得到一个 4096 维的特征向量,然后我们直接用这个特征向量替代原来的图片,再加若干层全连接的神经网络,对花朵数据集进行训练(属于模型迁移)
基于深度学习和迁移学习的识花实践(转) 深度学习是人工智能领域近年来最火热的话题之一,但是对于个人来说,以往想要玩转深度学习除了要具备高超的编程技巧,还需要有海量的数据和强劲的硬件.不过 Tens ...
- 基于深度学习的人脸识别系统(Caffe+OpenCV+Dlib)【三】VGG网络进行特征提取
前言 基于深度学习的人脸识别系统,一共用到了5个开源库:OpenCV(计算机视觉库).Caffe(深度学习库).Dlib(机器学习库).libfacedetection(人脸检测库).cudnn(gp ...
- [转帖]技术扫盲:新一代基于UDP的低延时网络传输层协议——QUIC详解
技术扫盲:新一代基于UDP的低延时网络传输层协议——QUIC详解 http://www.52im.net/thread-1309-1-1.html 本文来自腾讯资深研发工程师罗成的技术分享, ...
- Matlab与.NET基于类型安全的接口混合编程入门
原文:[原创]Matlab与.NET基于类型安全的接口混合编程入门 如果这些文章对你有用,有帮助,期待更多开源组件介绍,请不要吝啬手中的鼠标. [原创分享]Matlab.NET混编调用Figure窗体 ...
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
object detection我的理解,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别.object detection要解决的问题就是物体在哪里,是什么这整个流程的问题.然而,这个问题 ...
- Native APP ,Web APP,Hybrid APP三者对比
Native APP Native APP 指的是原生程序(Android.iOS.WP),一般依托于操作系统,有很强的交互,可拓展性强,需要用户下载安装使用,是一个完整的App. 原生应用程序是某一 ...
- 腾讯优图&港科大提出一种基于深度学习的非光流 HDR 成像方法
目前最好的高动态范围(HDR)成像方法通常是先利用光流将输入图像对齐,随后再合成 HDR 图像.然而由于输入图像存在遮挡和较大运动,这种方法生成的图像仍然有很多缺陷.最近,腾讯优图和香港科技大学的研究 ...
随机推荐
- Springboot实现remember-me记住我功能
1.什么是remeber-me? remeber-me即记住我功能,是我们在登录web系统时的常见勾选项.当我们登录一个web系统时除了输入常规的用户名.密码后还可以勾选记住我选项(假设该系统提供了该 ...
- Oracle设置和删除不可用列
Oracle设置和删除不可用列 1.不可用列是什么? 就是表中的1个或多个列被ALTER TABLE-SET UNUSED 语句设置为无法再被程序利用的列. 2.使用场景? If you are co ...
- Spring rce CVE-2022-22965
原理大致是这样:spring框架在传参的时候会与对应实体类自动参数绑定,通过"."还可以访问对应实体类的引用类型变量.使用getClass方法,通过反射机制最终获取tomcat的日 ...
- Linux驱动开发笔记(四):设备驱动介绍、熟悉杂项设备驱动和ubuntu开发杂项设备Demo
前言 驱动的开发需要先熟悉基本概念类型,本篇讲解linux杂项设备基础,还是基于虚拟机ubuntu去制作驱动,只需要虚拟机就可以尝试编写注册杂项设备的基本流程. linux三大设备驱动 字符设 ...
- 05-Redis系列之-主从复制配置和优化,fork和aof两大阻塞
主从复制 原理 一台主服务器配多台从服务器,主服务器宕机后,从服务器挑选一台顶上去. 从服务器同步主服务器的数据,这个同步是单向的,并且从服务器不能设置值,否则会造成数据的混乱 功能 0.故障处理:s ...
- 【Azure 应用服务】Azure Function 中运行Powershell 脚本,定位 -DefaultProfile 引发的错误
问题描述 突然之间,使用PowerShell脚本 Get-AzVirtualNetwork 获取虚拟网络信息时,如果带上 -DefaultProfile $sub 参数,就出现 Azure cred ...
- 分布式事务框架seata入门
一.简介 在近几年流行的微服务架构中,由于对服务和数据库进行了拆分,原来的一个单进程本地事务变成多个进程的本地事务,这时要保证数据的一致性,就需要用到分布式事务了.分布式事务的解决方案有很多,其中国内 ...
- 一文了解 Nebula Graph DBaaS 服务——Nebula Graph Cloud Service
Nebula Graph DBaaS 作为一款 DBaaS(DataBase as s Service)的产品,Nebula Graph Cloud Service 极大地降低了研发人员使用 Nebu ...
- 从零开始写 Docker(四)---使用 pivotRoot 切换 rootfs 实现文件系统隔离
change-rootfs-by-pivot-root.png 本文为从零开始写 Docker 系列第四篇,在mydocker run 基础上使用 pivotRoot 系统调用切换 rootfs 实现 ...
- 以Servlet来解释 抽象实现类
在 Java Servlet API 中: Servlet 接口定义了一个 Servlet 的基本行为.这个接口是抽象的,因为它包含抽象方法,比如 service(), init(), 和 destr ...