SQL:聚集索引和非聚集索引
聚集(clustered)索引,也叫聚簇索引
定义:数据行的物理顺序与列值(一般是主键的那一列)的逻辑顺序相同,一个表中只能拥有一个聚集索引。

注:第一列的地址表示该行数据在磁盘中的物理地址,后面三列才是我们SQL里面用的表里的列,其中id是主键,建立了聚集索引。
结合上面的表格就可以理解这句话了吧:数据行的物理顺序与列值的顺序相同,如果我们查询id比较靠后的数据,那么这行数据的地址在磁盘中的物理地址也会比较靠后。而且由于物理排列方式与聚集索引的顺序相同,所以也就只能建立一个聚集索引了。

** 聚集索引实际存放的示意图**
从上图可以看出聚集索引的好处了,索引的叶子节点就是对应的数据节点(MySQL的MyISAM除外,此存储引擎的聚集索引和非聚集索引只多了个唯一约束,其他没什么区别),可以直接获取到对应的全部列的数据,而非聚集索引在索引没有覆盖到对应的列的时候需要进行二次查询,后面会详细讲。因此在查询方面,聚集索引的速度往往会更占优势。
创建聚集索引
如果不创建索引,系统会自动创建一个隐含列作为表的聚集索引。
1.创建表的时候指定主键(注意:SQL Sever默认主键为聚集索引,也可以指定为非聚集索引,而MySQL里主键就是聚集索引)
create table t1( id int primary key, name nvarchar(255) )
2.创建表后添加聚集索引
MySQL
alter table table_name add primary key(colum_name)
值得注意的是,最好还是在创建表的时候添加聚集索引,由于聚集索引的物理顺序上的特殊性,因此如果再在上面创建索引的时候会根据索引列的排序移动全部数据行上面的顺序,会非常地耗费时间以及性能。
非聚集(unclustered)索引
定义:该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同,一个表中可以拥有多个非聚集索引。
其实按照定义,除了聚集索引以外的索引都是非聚集索引,只是人们想细分一下非聚集索引,分成普通索引,唯一索引,全文索引。如果非要把非聚集索引类比成现实生活中的东西,那么非聚集索引就像新华字典的偏旁字典,他结构顺序与实际存放顺序不一定一致。

非聚集索引的二次查询问题
非聚集索引叶节点仍然是索引节点,只是有一个指针指向对应的数据块,此如果使用非聚集索引查询,而查询列中包含了其他该索引没有覆盖的列,那么他还要进行第二次的查询,查询节点上对应的数据行的数据。
有表t1:

其中有 聚集索引clustered index(id), 非聚集索引index(username)。
使用以下语句进行查询,不需要进行二次查询,直接就可以从非聚集索引的节点里面就可以获取到查询列的数据。
select id, username from t1 where username = '小明' select username from t1 where username = '小明'
但是使用以下语句进行查询,就需要二次的查询去获取原数据行的score:
select username, score from t1 where username = '小明'
在SQL Server里面查询效率如下所示,Index Seek就是索引所花费的时间,Key Lookup就是二次查询所花费的时间。可以看的出二次查询所花费的查询开销占比很大,达到50%。
这篇博客有一个简单示例:https://blog.csdn.net/jiadajing267/article/details/54581262
总结如下:
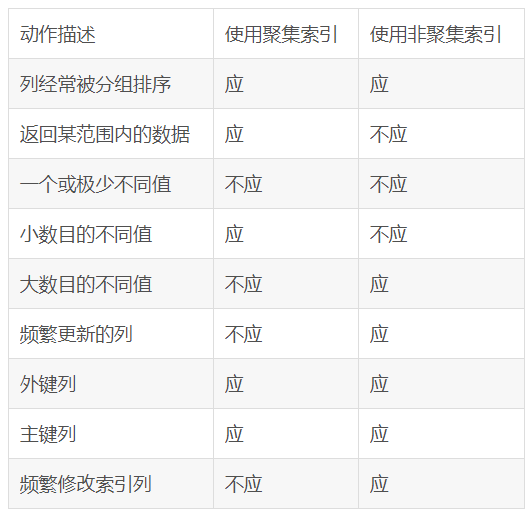
我们需要搞清楚以下几个问题:
第一:聚集索引的约束是唯一性,是否要求字段也是唯一的呢? ** 不要求唯一!**
分析:如果认为是的朋友,可能是受系统默认设置的影响,一般我们指定一个表的主键,如果这个表之前没有聚集索引,同时建立主键时候没有强制指定使用非聚集索引,SQL会默认在此字段上创建一个聚集索引,而主键都是唯一的,所以理所当然的认为创建聚集索引的字段也需要唯一。
结论:聚集索引可以创建在任何一列你想创建的字段上,这是从理论上讲,实际情况并不能随便指定,否则在性能上会是恶梦。
第二:为什么聚集索引可以创建在任何一列上,如果此表没有主键约束,即有可能存在重复行数据呢?
粗一看,这还真是和聚集索引的约束相背,但实际情况真可以创建聚集索引。
分析其原因是:如果未使用 UNIQUE 属性创建聚集索引,数据库引擎将向表自动添加一个四字节 uniqueifier 列。必要时,数据库引擎 将向行自动添加一个 uniqueifier 值,使每个键唯一。此列和列值供内部使用,用户不能查看或访问。
第三:是不是聚集索引就一定要比非聚集索引性能优呢?
如果想查询学分在60-90之间的学生的学分以及姓名,在学分上创建聚集索引是否是最优的呢?
答:否。既然只输出两列,我们可以在学分以及学生姓名上创建联合非聚集索引,此时的索引就形成了覆盖索引,即索引所存储的内容就是最终输出的数据,这种索引在比以学分为聚集索引做查询性能更好。
第四:在数据库中通过什么描述聚集索引与非聚集索引的?
索引是通过二叉树的形式进行描述的,我们可以这样区分聚集与非聚集索引的区别:聚集索引的叶节点就是最终的数据节点,而非聚集索引的叶节仍然是索引节点,但它有一个指向最终数据的指针。
第五:在主键是创建聚集索引的表在数据插入上为什么比主键上创建非聚集索引表速度要慢?
有了上面第四点的认识,我们分析这个问题就有把握了,在有主键的表中插入数据行,由于有主键唯一性的约束,所以需要保证插入的数据没有重复。我们来比较下主键为聚集索引和非聚集索引的查找情况:聚集索引由于索引叶节点就是数据页,所以如果想检查主键的唯一性,需要遍历所有数据节点才行,但非聚集索引不同,由于非聚集索引上已经包含了主键值,所以查找主键唯一性,只需要遍历所有的索引页就行(索引的存储空间比实际数据要少),这比遍历所有数据行减少了不少IO消耗。这就是为什么主键上创建非聚集索引比主键上创建聚集索引在插入数据时要快的真正原因。
SQL:聚集索引和非聚集索引的更多相关文章
- SQL Server-聚焦聚集索引对非聚集索引的影响(四)
前言 在学习SQL 2012基础教程过程中会时不时穿插其他内容来进行讲解,相信看过SQL Server 2012 T-SQL基础教程的童鞋知道前面写的所有内容并非都是摘抄书上内容,如若是这样那将没有任 ...
- SQL SERVER 索引之聚集索引和非聚集索引的描述
索引是与表或视图关联的磁盘上结构,可以加快从表或视图中检索行的速度. 索引包含由表或视图中的一列或多列生成的键. 这些键存储在一个结构(B 树)中,使 SQL Server 可以快速有效地查找与键值关 ...
- SQL Server中的联合主键、聚集索引、非聚集索引、mysql 联合索引
我们都知道在一个表中当需要2列以上才能确定记录的唯一性的时候,就需要用到联合主键,当建立联合主键以后,在查询数据的时候性能就会有很大的提升,不过并不是对联合主键的任何列单独查询的时候性能都会提升,但我 ...
- SQL Server索引 (原理、存储)聚集索引、非聚集索引、堆 <第一篇>
一.存储结构 在SQL Server中,有许多不同的可用排列规则选项. 二进制:按字符的数字表示形式排序(ASCII码中,用数字32表示空格,用68表示字母"D").因为所有内容都 ...
- SQL Server索引 - 聚集索引、非聚集索引、非聚集唯一索引 <第八篇>
聚集索引.非聚集索引.非聚集唯一索引 我们都知道建立适当的索引能够提高查询速度,优化查询.先说明一下,无论是聚集索引还是非聚集索引都是B树结构. 聚集索引默认与主键相匹配,在设置主键时,SQL Ser ...
- SQL Server 深入解析索引存储(非聚集索引)
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/索引体系结构/非聚集索引 概述 非聚集索引与聚集索引具有相同的 B 树结构,它们之间的显著差别在于以下两点: 基础表的数据行不按非 ...
- SQL Server - 索引详细教程 (聚集索引,非聚集索引)
转载自:https://www.cnblogs.com/hyd1213126/p/5828937.html 作者:爱不绝迹 (一)必读:深入浅出理解索引结构 实际上,您可以把索引理解为一种特殊的目录. ...
- 浅谈sql server聚集索引与非聚集索引
今天同事的服务程序在执行批量插入数据操作时,会超时失败,代码debug了几遍一点问题都没有,SQL单条插入也可以正常录入数据,调试了一上午还是很迷茫,场面一度很尴尬,最后还是发现了问题的根本,原来是另 ...
- SQL有三个类型的索引,唯一索引 不能有重复,但聚集索引,非聚集索引可以有重复
重要: (1) SQL如果创建时候,不指定类型那么默认是非聚集索引 (2) 聚集索引和非聚集索引都可以有重复记录,唯一索引不能有重复记录. (3) 主键 默认是加了唯一约束的聚集索引,但是也可以在主键 ...
- SQL Server的聚集索引和非聚集索引
微软的SQL SERVER提供了两种索引:聚集索引(clustered index,也称聚类索引.簇集索引)和非聚集索引(nonclustered index,也称非聚类索引.非簇集索引)…… (一) ...
随机推荐
- SSL/TSL 总结
参考:https://blog.csdn.net/qq153471503/article/details/109524764 (一)生成CA证书 1.创建CA证书私钥openssl genrsa -a ...
- WPF在ListView中绑定Command命令的写法
假定:ViewModel中有一个数据源叫Persons,有一个命令叫DoCommand,通过System.Windows.Interactivity触发器绑定鼠标MouseUp事件,当UI端绑定了Da ...
- C++笔记(4)友元
通常情况下,公有类方法是访问类对象私有部分的唯一途径.除此之外,C++还提供了另外一种形式的访问权限:友元. 友元有三种: 友元函数 友元类 友元成员函数 通过让函数成为类的友元,可以赋予该函数与类的 ...
- mysql binlog查看指定数据库
1.mysql binlog查看指定数据库的方法 MySQL 的 binlog(二进制日志)主要记录了数据库上执行的所有更改数据的 SQL 语句,包括数据的插入.更新和删除等操作.但直接查看 binl ...
- itest work(爱测试) 开源一站式接口测试&敏捷测试工作站 9.0.3
(一)itest work 简介 itest work (爱测试) 一站式工作站让测试变得简单.敏捷,"好用.好看,好敏捷" ,是itest wrok 追求的目标.itest w ...
- 震惊!docker镜像还有这些知识你都知道吗
震惊!docker镜像还有这些知识你都知道吗? 镜像搜索 语法 [root@hmm docker-hello]# docker search -h Flag shorthand -h has been ...
- vue devtools工具安装 Vue实现数据绑定的原理
通过chrome中的谷歌插件商店安装Vue Devtools工具,此工具帮助我们进行vue数据调试所用,一定要安装. https://chrome.google.com/webstore?utm_so ...
- ABC326
上次说我的写法low的人的AT号在这里!!( 我又来提供 low 算法了. 从 D 开始. T4 我们把 \(\text{A}\) 看成 \(1\),把 \(\text{B}\) 看成 \(2\),把 ...
- 自建yum源
自定义yum本地仓库 你不需要依赖外网的yum仓库,可能导致该仓库无法访问,下载软件失败.. 大公司,会自建yum仓库 防止出现网络问题,自建了yum仓库,本地yum仓库 你可以去阿里云上,部署一个在 ...
- Javascript高级程序设计第三章 | ch3 | 阅读笔记
语言基础 语法 标识符 注释 // /* */ 严格模式 // 也可以单独指定在一个函数中进行 'use strict' 语句 语句末尾分号不是必须的,但是最好加上 加上分号方便开发者删除空行压缩代码 ...