.NET快速实现网页数据抓取
前言
今天我们来讲讲如何使用.NET开源(MIT License)的轻量、灵活、高性能、跨平台的分布式网络爬虫框架DotnetSpider来快速实现网页数据抓取功能。
注意:为了自身安全请在国家法律允许范围内开发网页爬虫功能。
网页数据抓取需求
本文我们以抓取博客园10天推荐排行榜第一页的文章标题、文章简介和文章地址为示例,并把抓取下来的数据保存到对应的txt文本中。

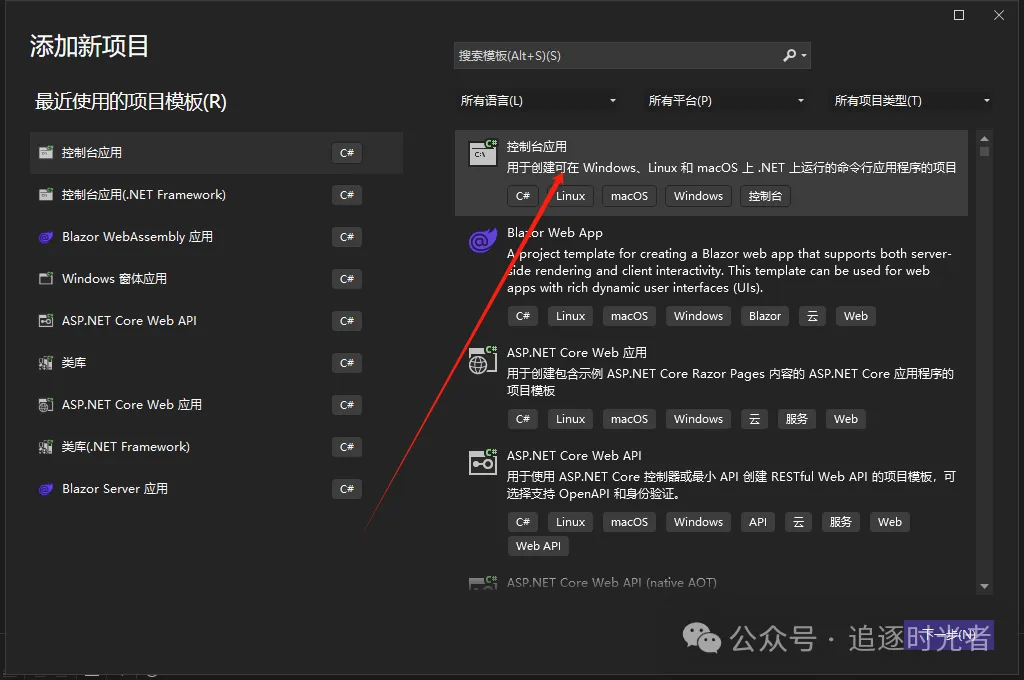
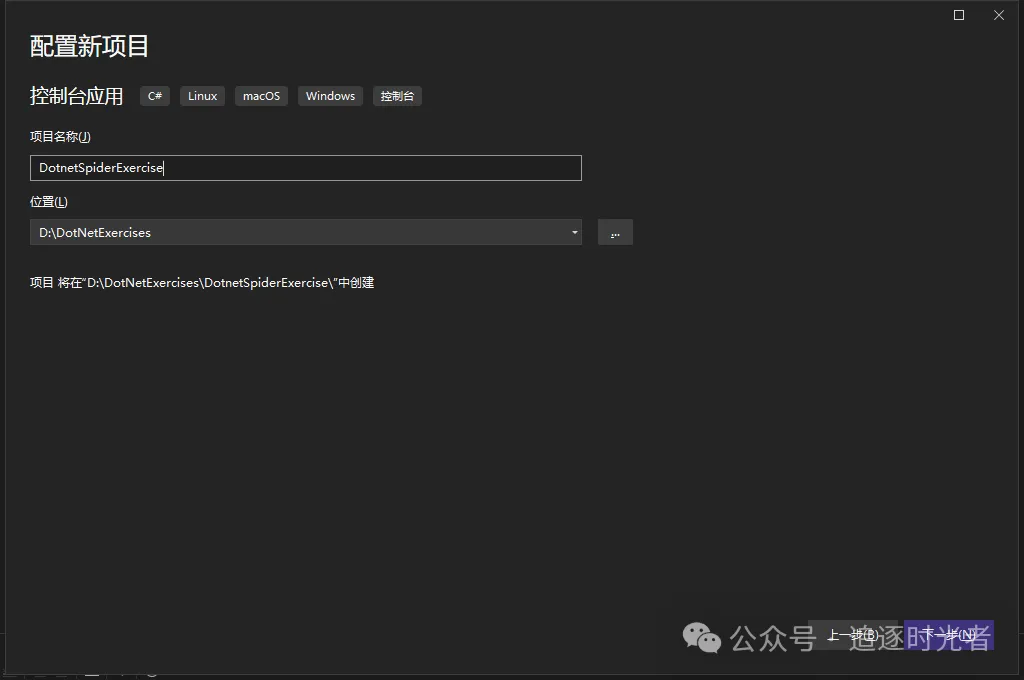
创建控制台应用
创建名为DotnetSpiderExercise的控制台应用。
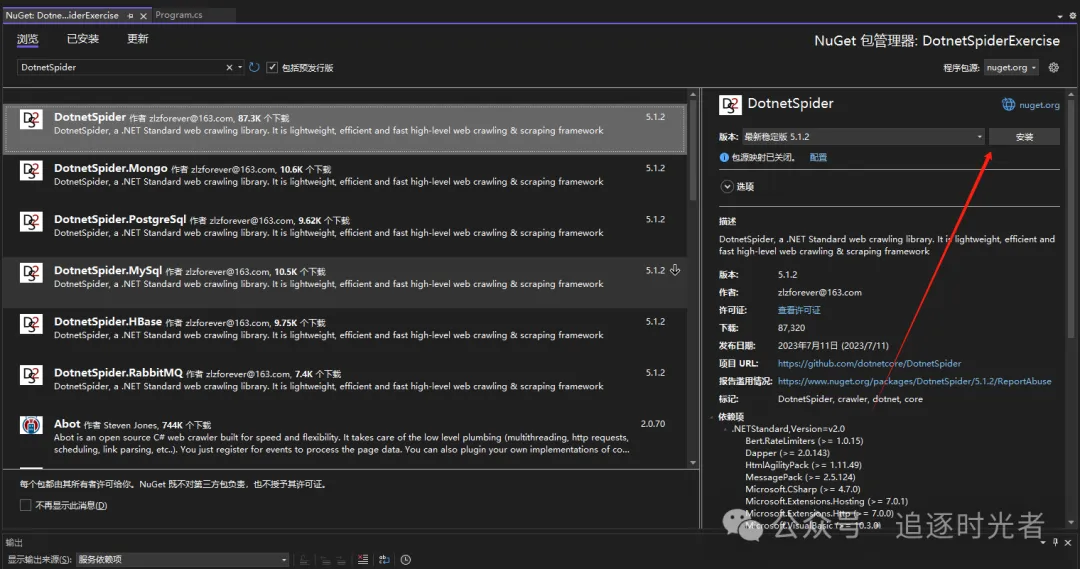
安装DotnetSpider NuGet包
NuGet包管理器搜索:DotnetSpider
添加Serilog日志组件
NuGet包管理器搜索:Serilog.AspNetCore
添加RecommendedRankingModel
namespace DotnetSpiderExercise
{
public class RecommendedRankingModel
{
/// <summary>
/// 文章标题
/// </summary>
public string ArticleTitle { get; set; }
/// <summary>
/// 文章简介
/// </summary>
public string ArticleSummary { get; set; }
/// <summary>
/// 文章地址
/// </summary>
public string ArticleUrl { get; set; }
}
}
添加RecommendedRankingSpider
网页数据抓取的业务逻辑都在这里面。
using DotnetSpider.DataFlow.Parser;
using DotnetSpider.DataFlow;
using DotnetSpider.Downloader;
using DotnetSpider.Http;
using DotnetSpider.Scheduler.Component;
using DotnetSpider.Selector;
using DotnetSpider;
using Microsoft.Extensions.Logging;
using Microsoft.Extensions.Options;
using Serilog;
using DotnetSpider.Scheduler;
using Microsoft.Extensions.Hosting;
using System.Reflection;
namespace DotnetSpiderExercise
{
public class RecommendedRankingSpider : Spider
{
public RecommendedRankingSpider(IOptions<SpiderOptions> options,
DependenceServices services,
ILogger<Spider> logger) : base(options, services, logger)
{
}
public static async Task RunAsync()
{
var builder = Builder.CreateDefaultBuilder<RecommendedRankingSpider>();
builder.UseSerilog();
builder.UseDownloader<HttpClientDownloader>();
builder.UseQueueDistinctBfsScheduler<HashSetDuplicateRemover>();
await builder.Build().RunAsync();
}
protected override async Task InitializeAsync(CancellationToken stoppingToken = default)
{
//添加自定义解析
AddDataFlow(new Parser());
//使用控制台存储器
AddDataFlow(new ConsoleStorage());
//添加采集请求:博客园10天推荐排行榜
await AddRequestsAsync(new Request("https://www.cnblogs.com/aggsite/topdiggs")
{
//请求超时10秒
Timeout = 10000
});
}
class Parser : DataParser
{
public override Task InitializeAsync()
{
return Task.CompletedTask;
}
protected override Task ParseAsync(DataFlowContext context)
{
var recommendedRankingList = new List<RecommendedRankingModel>();
// 网页数据解析
var number = 1;
var recommendedList = context.Selectable.SelectList(Selectors.XPath(".//article[@class='post-item']"));
foreach (var news in recommendedList)
{
var articleTitle = news.Select(Selectors.XPath(".//a[@class='post-item-title']"))?.Value;
var articleSummary = news.Select(Selectors.XPath(".//p[@class='post-item-summary']"))?.Value?.Replace("\n", "").Replace(" ", "");
var articleUrl = news.Select(Selectors.XPath(".//a[@class='post-item-title']/@href"))?.Value;
Console.WriteLine($"第{number}篇文章 标题:{articleTitle}");
recommendedRankingList.Add(new RecommendedRankingModel
{
ArticleTitle = articleTitle,
ArticleSummary = articleSummary,
ArticleUrl = articleUrl
});
number++;
}
using (StreamWriter sw = new StreamWriter("RecommendedRanking.txt"))
{
foreach (RecommendedRankingModel model in recommendedRankingList)
{
string line = $"文章标题:{model.ArticleTitle}\r\n文章简介:{model.ArticleSummary}\r\n文章地址:{model.ArticleUrl}";
sw.WriteLine(line + "\r\n ========================================================================================== \r\n");
}
}
return Task.CompletedTask;
}
}
}
}
Program执行数据抓取
namespace DotnetSpiderExercise
{
public class Program
{
static async Task Main(string[] args)
{
Console.WriteLine("网页数据抓取开始...");
await RecommendedRankingSpider.RunAsync();
Console.WriteLine("网页数据抓取完成...");
}
}
}
抓取数据和页面数据对比
抓取数据

页面数据
项目源码地址
更多项目实用功能和特性欢迎前往项目开源地址查看,别忘了给项目一个Star支持。
- GitHub源码地址:https://github.com/dotnetcore/DotnetSpider
- GitHub wiki:https://github.com/dotnetcore/DotnetSpider/wiki
- 本文示例源码:https://github.com/YSGStudyHards/DotNetExercises/tree/master/DotnetSpiderExercise
优秀项目和框架精选
该项目已收录到C#/.NET/.NET Core优秀项目和框架精选中,关注优秀项目和框架精选能让你及时了解C#、.NET和.NET Core领域的最新动态和最佳实践,提高开发工作效率和质量。坑已挖,欢迎大家踊跃提交PR推荐或自荐(让优秀的项目和框架不被埋没)。
DotNetGuide技术社区交流群
- DotNetGuide技术社区是一个面向.NET开发者的开源技术社区,旨在为开发者们提供全面的C#/.NET/.NET Core相关学习资料、技术分享和咨询、项目框架推荐、求职和招聘资讯、以及解决问题的平台。
- 在DotNetGuide技术社区中,开发者们可以分享自己的技术文章、项目经验、学习心得、遇到的疑难技术问题以及解决方案,并且还有机会结识志同道合的开发者。
- 我们致力于构建一个积极向上、和谐友善的.NET技术交流平台。无论您是初学者还是有丰富经验的开发者,我们都希望能为您提供更多的价值和成长机会。
.NET快速实现网页数据抓取的更多相关文章
- 爬虫---selenium动态网页数据抓取
动态网页数据抓取 什么是AJAX: AJAX(Asynchronouse JavaScript And XML)异步JavaScript和XML.过在后台与服务器进行少量数据交换,Ajax 可以使网页 ...
- 网页数据抓取工具,webscraper 最简单的数据抓取教程,人人都用得上
Web Scraper 是一款免费的,适用于普通用户(不需要专业 IT 技术的)的爬虫工具,可以方便的通过鼠标和简单配置获取你所想要数据.例如知乎回答列表.微博热门.微博评论.淘宝.天猫.亚马逊等电商 ...
- Android登录client,验证码的获取,网页数据抓取与解析,HttpWatch基本使用
大家好,我是M1ko.在互联网时代的今天,假设一个App不接入互联网.那么这个App一定不会有长时间的生命周期,因此Android网络编程是每个Android开发人员必备的技能.博主是在校大学生,自学 ...
- 【Android 我的博客APP】1.抓取博客首页文章列表内容——网页数据抓取
打算做个自己在博客园的博客APP,首先要能访问首页获取数据获取首页的文章列表,第一步抓取博客首页文章列表内容的功能已实现,在小米2S上的效果图如下: 思路是:通过编写的工具类访问网页,获取页面源代码, ...
- 网页数据抓取(B/S)
C# 抓取网页内容(转) 1.抓取一般内容 需要三个类:WebRequest.WebResponse.StreamReader 所需命名空间:System.Net.System.IO 核心代码: We ...
- Web网页数据抓取(C/S)
通过程序自动的读取其它网站网页显示的信息,类似于爬虫程序.比方说我们有一个系统,要提取BaiDu网站上歌曲搜索排名.分析系统在根据得到的数据进行数据分析.为业务提供参考数据. 为了完成以上的需求,我们 ...
- java网页数据抓取实例
在很多行业中,要对行业数据进行分类汇总,及时分析行业数据,对于公司未来的发展,有很好的参照和横向对比.所以,在实际工作,我们可能要遇到数据采集这个概念,数据采集的最终目的就是要获得数据,提取有用的数据 ...
- Python爬虫之-动态网页数据抓取
什么是AJAX: AJAX(Asynchronouse JavaScript And XML)异步JavaScript和XML.过在后台与服务器进行少量数据交换,Ajax 可以使网页实现异步更新.这意 ...
- python 入门实践之网页数据抓取
这个不错.正好入门学习使用. 1.其中用到 feedparser: 技巧:使用 Universal Feed Parser 驾驭 RSS http://www.ibm.com/developerwor ...
- 一个我经常用到的采集网页数据抓取网页获取数据的PHP函数类
class get_c_str { var $str; var $start_str; var $end_str; var $start_pos; var $end_pos; var $c_str_l ...
随机推荐
- Numpy通用函数及向量化计算
Python(Cpython)对于较大数组的循环操作会比较慢,因为Python的动态性和解释性,在做每次循环时,必须做数据类型的检查和函数的调度. Numpy为很多类型的操作提供了非常方便的.静态类型 ...
- 利用BCEL字节码构造内存马
****# 前言 BCEL加载类有一个特点,只可以加载jdk原生的类,其它框架的类,都会报错ClassnotFound的错误.但是,BCEL的ClassLoader在8u252后被删除了 注入流程分析 ...
- 网上 server2008数据库恢复方法
从网下下载文件有两个:XX_DB_log.ldf 和XX_DB.mdf 首先:文件处理:右键--属性--安全---编辑--勾选"完全控制"--确定--即可.(两个文件都是相同操作) ...
- std::thread 一:创建线程的三种方式
前言: #include <thread> thread.join() // 阻塞 thread.detach() // 非阻塞 thread.joinable() // bool,判断线 ...
- MogDB/openGauss 自定义snmptrapd告警信息
MogDB/openGauss 自定义 snmptrapd 告警信息 在实际使用中,默认的报警规则信息并不能很好的满足 snmp 服务端的需求,需要定制化报警信息,这里以添加 ip 为例,看似一个简单 ...
- cv.calibrateCamera
相机造成的失真类型 如何找到相机的内在和外在特性 如何基于这些特性来消除图像失真 基础 一些针孔相机会对图像造成严重失真.两种主要的畸变是径向畸变和切向畸变. 径向变形会使直线看起来是弯曲的.点离图像 ...
- 鸿蒙开发套件之DevEco Profiler助您轻松分析应用性能问题
作者:shizhengtao,华为性能调优工具专家 应用的性能优化一直以来都是开发者所面临的一大难题,在2023HDC大会上全新亮相的HarmonyOS NEXT开发者预览版,其中鸿蒙开发套件Dev ...
- spring boot properties 编码问题[四]
情景 application.properties 中: server.port=8081 person.last-name=张三 person.age=18 person.birth=2017/12 ...
- java调用QQ影音进行截图
import java.awt.Graphics2D; import java.awt.Image; import java.awt.Robot; import java.awt.Toolkit; i ...
- 字节面试:如何解决MQ消息积压问题?
MQ(Message Queue)消息积压问题指的是在消息队列中累积了大量未处理的消息,导致消息队列中的消息积压严重,超出系统处理能力,影响系统性能和稳定性的现象. 1.消息积压是哪个环节的问题? M ...