【Java】Jsoup 解析HTML报告
一、需求背景
有好几种报告文件,目前是人肉找报告信息填到Excel上生成统计信息
跟用户交流了下需求和提供的几个文件,发现都是html文件
其实所谓的报告的文件,就是一些本地可打开的静态资源,里面也有js、img等等
二、方案选型
前面老板一直说是文档解析,我寻思这不就是写爬虫吗....
因为是在现有系统上加新功能实现,现有系统还是Java做后端服务,所以之前学的Python就不想用了
写Python还需要单独起个服务部署起来,Java有JSOUP能用,没Python那么好用就是...
三、落地实现
1、JSOUP依赖坐标:
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.18.1</version>
</dependency>
2、文件读取问题
我发现每种类型的报告文件的存放方式都不一样
第一种单HTML文件:
这种相对简单,只需要读取路径后直接访问文件内容即可
String reportFilePath = "C:/Users/Administrator/Desktop/report-type/xxx.html";
String htmlContent = new String(Files.readAllBytes(Paths.get(reportFilePath)), StandardCharsets.UTF_8);
Document doc = Jsoup.parse(htmlContent);
第二种单Zip压缩文件:
单层压缩,可以通过zipFile的API访问,取出压缩条目一个个用条目名称进行判断
再通过zipFile打开读取流对该条目进行读取
String targetFile = "index.html";
ZipEntry targetEntry = null;
String reportFilePath = "C:/Users/Administrator/Desktop/report-type/xxxhtml.zip";
ZipFile zipFile = isWinSys() ? new ZipFile(new File(reportFilePath), ZipFile.OPEN_READ, Charset.forName("GBK")) : new ZipFile(reportFilePath);
Enumeration<? extends ZipEntry> zipEntries = zipFile.entries();
while (zipEntries.hasMoreElements()) {
ZipEntry zipEntry = zipEntries.nextElement();
boolean isDirectory = zipEntry.isDirectory();
if (isDirectory) continue;
String name = zipEntry.getName();
if (targetFile.equals(name)) {
targetEntry = zipEntry;
break;
}
}
boolean hasFind = Objects.nonNull(targetEntry);
if (!hasFind) return; /* 没有可读取的目标文件 */
InputStream inputStream = zipFile.getInputStream(targetEntry);
String htmlCode = IoUtil.readUtf8(inputStream);
Document doc = Jsoup.parse(htmlCode);
执行完成后记得要释放资源:
/* 资源释放 */
inputStream.close();
zipFile.close();
第三种多Zip嵌套压缩文件:
文件被压缩了两次,要解压两边才可以访问
1、读取内嵌的Zip文件时发现MALFORM报错,需要根据操作系统设置读取编码...
https://blog.csdn.net/qq_25112523/article/details/136060946
然后在创建ZipFile对象的API加了一个操作系统的判断
public static boolean isWinSys() {
String property = System.getProperty("os.name");
return property.contains("win") || property.contains("Win");
}
2、ZipFile只对单层压缩有用,如果是嵌套的压缩文件就不支持了
这个报告文件的情况是第一层只有一个条目,所以上传上来的文件我只关心里面只有一个内嵌的压缩文件就行
当匹配这个条件交给ZipFile读取输入流,转换成Zip输入流,否则不处理
可以在下面代码看到,对被压缩的文件进行inputStream读取后,要改用ZipInputStream读取
zipInputStream 等效 zipFile + zipEntries的合体,包含了条目迭代信息
但是只有一个getNextEntry方法,只能写While循环不断判断下一个条目是否还存在
文件名叫report.html,判断条目名是否匹配后结束循环
再利用IO工具类直接读取ZipInputStream即可 (getNextEntry方法就是让ZipInputStream不断切换到当前条目的引用)
如果要处理复杂情况要在While里面才能实现的,建议每个条目结束之后调用closeEntry方法
String targetSuffix = ".zip";
String targetFile = "report.html";
String reportFilePath = "C:/Users/Administrator/Desktop/report-type/xx_20240729153751.zip";
ZipFile zipFile = isWinSys() ? new ZipFile(new File(reportFilePath), ZipFile.OPEN_READ, Charset.forName("GBK")) : new ZipFile(reportFilePath);
Enumeration<? extends ZipEntry> enumeration = zipFile.entries();
/* 转换成集合条目,迭代条目不能判断size */
List<ZipEntry> zipEntrieList = new ArrayList<>();
while (enumeration.hasMoreElements()) {
ZipEntry zipEntry = enumeration.nextElement();
zipEntrieList.add(zipEntry);
}
/* 只有1个zip压缩文件时才处理 */
if (CollectionUtils.isEmpty(zipEntrieList)) return;
boolean isOnlyOneEntry = zipEntrieList.size() == 1;
boolean anyMatch = zipEntrieList.stream().anyMatch(ze -> ze.getName().endsWith(targetSuffix));
if (!isOnlyOneEntry || !anyMatch) return;
ZipEntry zipEntry = zipEntrieList.get(0);
/* 通过ZipInputStream不断切换条目找到目标文件 */
InputStream inputStream = zipFile.getInputStream(zipEntry);
ZipInputStream zipInputStream = new ZipInputStream(inputStream);
/* 在内层中寻找目标文件 */
ZipEntry reportEntry = zipInputStream.getNextEntry();
while (Objects.nonNull(reportEntry)) {
String name = reportEntry.getName();
if (targetFile.equals(name)) break;
reportEntry = zipInputStream.getNextEntry();
}
String htmlCode = IoUtil.readUtf8(zipInputStream);
Document doc = Jsoup.parse(htmlCode);
同样这里也需要释放资源:
/* 资源释放 */
zipInputStream.close();
inputStream.close();
zipFile.close();
3、常见查询API使用
一、常见API方法
下班到家才反应过来ownText是元素自己的文本内容,过滤掉其他嵌套的元素文本

也可以直接使用cssQuery
doc.select("table.y-report-ui-report-info-grid")
二、使用兄弟元素查找对应关系
有一个特殊的情况就是有些元素按文档结构应该是一个逐层关联的结构
先有A,然后B在A里面,C又在B里面这样
但是这个是摊开来的结构,A -> B -> C -> D,元素id和类名也没用直接关系,这样是很难构建关联的
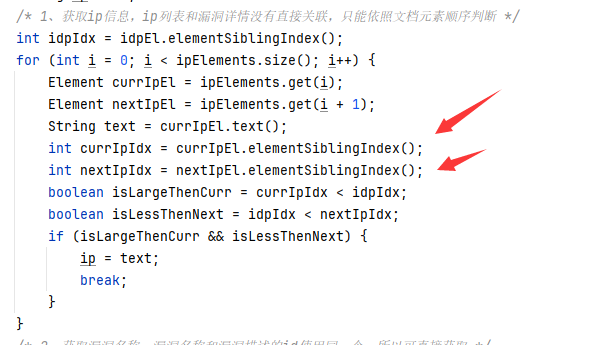
只能通过元素的顺序推断结构:
1、获取当前ip标题元素和下一个ip标题元素的兄弟元素下标值
2、将idp元素的兄弟元素下标值取出
3、比较idp元素是否在两者之间,如果为是表示idp元素属于第一个ip标题元素
【Java】Jsoup 解析HTML报告的更多相关文章
- json-lib-2.4-jdk15.jar所需全部JAR包.rar java jsoup解析开彩网api接口json数据实例
json-lib-2.4-jdk15.jar所需全部JAR包.rar java jsoup解析开彩网api接口json数据实例 json-lib-2.4-jdk15.jar所需全部JAR包.rar ...
- [java] jsoup 解析网页获取省市区域信息
到国家统计局抓取数据, 到该class下解析数据 /** * jsoup解析网页 * @author xwolf * @date 2016-12-13 18:11 * @since V1.0.0 */ ...
- jsoup Java HTML解析器:使用选择器语法来查找元素
jsoup Java HTML解析器:使用选择器语法来查找元素 使用选择器语法来查找元素 问题 你想使用类似于CSS或jQuery的语法来查找和操作元素. 方法 可以使用Element.select( ...
- atitit. java jsoup html table的读取解析 总结
atitit. java jsoup html table的读取解析 总结 1. 两个大的parser ,,,jsoup 跟个 htmlparser 1 2. 资料比较 1 3. jsoup越佳. ...
- Java爬虫系列三:使用Jsoup解析HTML
在上一篇随笔<Java爬虫系列二:使用HttpClient抓取页面HTML>中介绍了怎么使用HttpClient进行爬虫的第一步--抓取页面html,今天接着来看下爬虫的第二步--解析抓取 ...
- [java] jsoup使用简介-汇率换算器实现-插曲2
[java] jsoup使用简介-汇率换算器实现-插曲2 // */ // ]]> [java] jsoup使用简介-汇率换算器实现-插曲2 Table of Contents 1 系列文章 ...
- jsoup解析HTML及简单实例
jsoup 中文参考文献 http://www.open-open.com/jsoup/ 本文将利用jsoup,简单实现网络抓取的功能,并给出一个小实例,该实例效果为:获取作者本人在博客园写的所 ...
- Android开发探秘之三:利用jsoup解析HTML页面
这节主要是讲解jsoup解析HTML页面.由于在android开发过程中,不可避免的涉及到web页面的抓取,解析,展示等等,所以,在这里我主要展示下利用jsoup jar包来抓取cnbeta.com网 ...
- 一步步教你为网站开发Android客户端---HttpWatch抓包,HttpClient模拟POST请求,Jsoup解析HTML代码,动态更新ListView
本文面向Android初级开发者,有一定的Java和Android知识即可. 文章覆盖知识点:HttpWatch抓包,HttpClient模拟POST请求,Jsoup解析HTML代码,动态更新List ...
- Jsoup 解析 HTML
Jsoup 文档 方法 要取得一个属性的值,可以使用Node.attr(String key) 方法 对于一个元素中的文本,可以使用Element.text()方法 对于要取得元素或属性中的HTML内 ...
随机推荐
- 讲课 PPT 公开啦
目前限于时间原因,只在 Github Pages 上托管了. 之后有时间会托管到 pythonanywhere 上,因为 Github Pages 是在太慢了.
- kettle从入门到精通 第三十三课 再谈 kettle 表输出 分区/分片
1.之前第九章有讲过kettle 表输出步骤,里面有简单的提到过表输出步骤里面的表分区设置,这里详细介绍下. 表分区数据:选择此选项可根据"分区"字段中指定的日期字段的值将数据拆分 ...
- 如何防止 Elasticsearch 服务 OOM ?
ES 和传统关系型数据库有很多区别, 比如传统数据中普遍都有一个叫"最大连接数"的设置.目的是使数据库系统工作在可控的负载下,避免出现负载过高,资源耗尽,谁也无法登录的局面. 那 ...
- C#.NET WinForm 多个子Task嵌套 Task.WaitAll 阻塞UI线程
C#.NET WinForm 多个子Task(子线程)嵌套 Task.WaitAll 阻塞UI线程 (界面) 情况: DoIt()方法内,开了2个Task 执行任务,子任务中会更新UI. DoIt( ...
- Oracle使用序列和触发器设置自增字段
一.创建一张工作表 例: create table tv(ID NUMBER primary key,TVNAME VARCHAR(16),ISPASS NUMBER); 二.先创建一个序列 cr ...
- es6数组解构的原理初探
原理 以前只用过数组解构为数组,或者将其他类数组解构为数组,但是还不知道对象为什么不能解构为数组 后面学习到了Symbol.iterator属性以后才知道,只要一个对象是可迭代的,那它就可以迭代为数组 ...
- Mysql性能优化(详解)
引言 今天,数据库的操作越来越成为整个应用的性能瓶颈了,这点对于Web应用尤其明显.关于数据库的性能,这并不只是DBA才需要担心的事,而这更是我们程序员需要去关注的事情.当我们去设计数据库表结构,对操 ...
- spring的问题-能耗、学习曲线
说实话,在过去将近20年中,spring对于it行业的帮助还是很大的,尤其是信息系统建设方面. 但在我看来,spring的发展也许进入了一个困局. 开始的时候,spring的确是一个还是算小巧的工具, ...
- 认真学习CSS3-问题收集-102号-关于定位
css中有关于定位的一个属性position. 在w3cschool中,position的介绍如下: 值 描述 absolute 生成绝对定位的元素,相对于 static 定位以外的第一个父元素进行定 ...
- apisix~14在自定义插件中调用proxy_rewrite
在 Apache APISIX 中,通过 proxy-rewrite 插件来修改上游配置时,需要确保插件的执行顺序和上下文环境正确.你提到在自己的插件中调用 proxy_rewrite.rewrite ...