【Java】Jsoup 解析HTML报告
一、需求背景
有好几种报告文件,目前是人肉找报告信息填到Excel上生成统计信息
跟用户交流了下需求和提供的几个文件,发现都是html文件
其实所谓的报告的文件,就是一些本地可打开的静态资源,里面也有js、img等等
二、方案选型
前面老板一直说是文档解析,我寻思这不就是写爬虫吗....
因为是在现有系统上加新功能实现,现有系统还是Java做后端服务,所以之前学的Python就不想用了
写Python还需要单独起个服务部署起来,Java有JSOUP能用,没Python那么好用就是...
三、落地实现
1、JSOUP依赖坐标:
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.18.1</version>
</dependency>
2、文件读取问题
我发现每种类型的报告文件的存放方式都不一样
第一种单HTML文件:
这种相对简单,只需要读取路径后直接访问文件内容即可
String reportFilePath = "C:/Users/Administrator/Desktop/report-type/xxx.html";
String htmlContent = new String(Files.readAllBytes(Paths.get(reportFilePath)), StandardCharsets.UTF_8);
Document doc = Jsoup.parse(htmlContent);
第二种单Zip压缩文件:
单层压缩,可以通过zipFile的API访问,取出压缩条目一个个用条目名称进行判断
再通过zipFile打开读取流对该条目进行读取
String targetFile = "index.html";
ZipEntry targetEntry = null;
String reportFilePath = "C:/Users/Administrator/Desktop/report-type/xxxhtml.zip";
ZipFile zipFile = isWinSys() ? new ZipFile(new File(reportFilePath), ZipFile.OPEN_READ, Charset.forName("GBK")) : new ZipFile(reportFilePath);
Enumeration<? extends ZipEntry> zipEntries = zipFile.entries();
while (zipEntries.hasMoreElements()) {
ZipEntry zipEntry = zipEntries.nextElement();
boolean isDirectory = zipEntry.isDirectory();
if (isDirectory) continue;
String name = zipEntry.getName();
if (targetFile.equals(name)) {
targetEntry = zipEntry;
break;
}
}
boolean hasFind = Objects.nonNull(targetEntry);
if (!hasFind) return; /* 没有可读取的目标文件 */
InputStream inputStream = zipFile.getInputStream(targetEntry);
String htmlCode = IoUtil.readUtf8(inputStream);
Document doc = Jsoup.parse(htmlCode);
执行完成后记得要释放资源:
/* 资源释放 */
inputStream.close();
zipFile.close();
第三种多Zip嵌套压缩文件:
文件被压缩了两次,要解压两边才可以访问
1、读取内嵌的Zip文件时发现MALFORM报错,需要根据操作系统设置读取编码...
https://blog.csdn.net/qq_25112523/article/details/136060946
然后在创建ZipFile对象的API加了一个操作系统的判断
public static boolean isWinSys() {
String property = System.getProperty("os.name");
return property.contains("win") || property.contains("Win");
}
2、ZipFile只对单层压缩有用,如果是嵌套的压缩文件就不支持了
这个报告文件的情况是第一层只有一个条目,所以上传上来的文件我只关心里面只有一个内嵌的压缩文件就行
当匹配这个条件交给ZipFile读取输入流,转换成Zip输入流,否则不处理
可以在下面代码看到,对被压缩的文件进行inputStream读取后,要改用ZipInputStream读取
zipInputStream 等效 zipFile + zipEntries的合体,包含了条目迭代信息
但是只有一个getNextEntry方法,只能写While循环不断判断下一个条目是否还存在
文件名叫report.html,判断条目名是否匹配后结束循环
再利用IO工具类直接读取ZipInputStream即可 (getNextEntry方法就是让ZipInputStream不断切换到当前条目的引用)
如果要处理复杂情况要在While里面才能实现的,建议每个条目结束之后调用closeEntry方法
String targetSuffix = ".zip";
String targetFile = "report.html";
String reportFilePath = "C:/Users/Administrator/Desktop/report-type/xx_20240729153751.zip";
ZipFile zipFile = isWinSys() ? new ZipFile(new File(reportFilePath), ZipFile.OPEN_READ, Charset.forName("GBK")) : new ZipFile(reportFilePath);
Enumeration<? extends ZipEntry> enumeration = zipFile.entries();
/* 转换成集合条目,迭代条目不能判断size */
List<ZipEntry> zipEntrieList = new ArrayList<>();
while (enumeration.hasMoreElements()) {
ZipEntry zipEntry = enumeration.nextElement();
zipEntrieList.add(zipEntry);
}
/* 只有1个zip压缩文件时才处理 */
if (CollectionUtils.isEmpty(zipEntrieList)) return;
boolean isOnlyOneEntry = zipEntrieList.size() == 1;
boolean anyMatch = zipEntrieList.stream().anyMatch(ze -> ze.getName().endsWith(targetSuffix));
if (!isOnlyOneEntry || !anyMatch) return;
ZipEntry zipEntry = zipEntrieList.get(0);
/* 通过ZipInputStream不断切换条目找到目标文件 */
InputStream inputStream = zipFile.getInputStream(zipEntry);
ZipInputStream zipInputStream = new ZipInputStream(inputStream);
/* 在内层中寻找目标文件 */
ZipEntry reportEntry = zipInputStream.getNextEntry();
while (Objects.nonNull(reportEntry)) {
String name = reportEntry.getName();
if (targetFile.equals(name)) break;
reportEntry = zipInputStream.getNextEntry();
}
String htmlCode = IoUtil.readUtf8(zipInputStream);
Document doc = Jsoup.parse(htmlCode);
同样这里也需要释放资源:
/* 资源释放 */
zipInputStream.close();
inputStream.close();
zipFile.close();
3、常见查询API使用
一、常见API方法
下班到家才反应过来ownText是元素自己的文本内容,过滤掉其他嵌套的元素文本

也可以直接使用cssQuery
doc.select("table.y-report-ui-report-info-grid")
二、使用兄弟元素查找对应关系
有一个特殊的情况就是有些元素按文档结构应该是一个逐层关联的结构
先有A,然后B在A里面,C又在B里面这样
但是这个是摊开来的结构,A -> B -> C -> D,元素id和类名也没用直接关系,这样是很难构建关联的
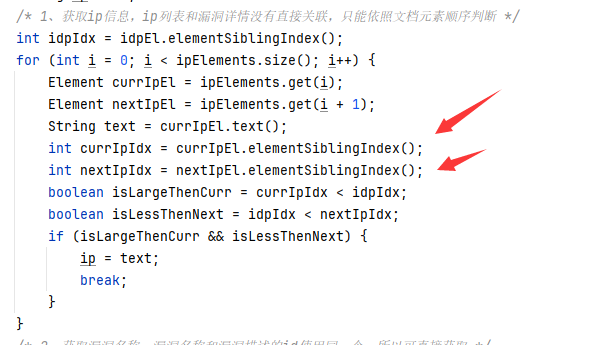
只能通过元素的顺序推断结构:
1、获取当前ip标题元素和下一个ip标题元素的兄弟元素下标值
2、将idp元素的兄弟元素下标值取出
3、比较idp元素是否在两者之间,如果为是表示idp元素属于第一个ip标题元素
【Java】Jsoup 解析HTML报告的更多相关文章
- json-lib-2.4-jdk15.jar所需全部JAR包.rar java jsoup解析开彩网api接口json数据实例
json-lib-2.4-jdk15.jar所需全部JAR包.rar java jsoup解析开彩网api接口json数据实例 json-lib-2.4-jdk15.jar所需全部JAR包.rar ...
- [java] jsoup 解析网页获取省市区域信息
到国家统计局抓取数据, 到该class下解析数据 /** * jsoup解析网页 * @author xwolf * @date 2016-12-13 18:11 * @since V1.0.0 */ ...
- jsoup Java HTML解析器:使用选择器语法来查找元素
jsoup Java HTML解析器:使用选择器语法来查找元素 使用选择器语法来查找元素 问题 你想使用类似于CSS或jQuery的语法来查找和操作元素. 方法 可以使用Element.select( ...
- atitit. java jsoup html table的读取解析 总结
atitit. java jsoup html table的读取解析 总结 1. 两个大的parser ,,,jsoup 跟个 htmlparser 1 2. 资料比较 1 3. jsoup越佳. ...
- Java爬虫系列三:使用Jsoup解析HTML
在上一篇随笔<Java爬虫系列二:使用HttpClient抓取页面HTML>中介绍了怎么使用HttpClient进行爬虫的第一步--抓取页面html,今天接着来看下爬虫的第二步--解析抓取 ...
- [java] jsoup使用简介-汇率换算器实现-插曲2
[java] jsoup使用简介-汇率换算器实现-插曲2 // */ // ]]> [java] jsoup使用简介-汇率换算器实现-插曲2 Table of Contents 1 系列文章 ...
- jsoup解析HTML及简单实例
jsoup 中文参考文献 http://www.open-open.com/jsoup/ 本文将利用jsoup,简单实现网络抓取的功能,并给出一个小实例,该实例效果为:获取作者本人在博客园写的所 ...
- Android开发探秘之三:利用jsoup解析HTML页面
这节主要是讲解jsoup解析HTML页面.由于在android开发过程中,不可避免的涉及到web页面的抓取,解析,展示等等,所以,在这里我主要展示下利用jsoup jar包来抓取cnbeta.com网 ...
- 一步步教你为网站开发Android客户端---HttpWatch抓包,HttpClient模拟POST请求,Jsoup解析HTML代码,动态更新ListView
本文面向Android初级开发者,有一定的Java和Android知识即可. 文章覆盖知识点:HttpWatch抓包,HttpClient模拟POST请求,Jsoup解析HTML代码,动态更新List ...
- Jsoup 解析 HTML
Jsoup 文档 方法 要取得一个属性的值,可以使用Node.attr(String key) 方法 对于一个元素中的文本,可以使用Element.text()方法 对于要取得元素或属性中的HTML内 ...
随机推荐
- 查看SO KO 执行程序相关信息命令
1 查看SO 查看so库的方法__臣本布衣_新浪博客 (sina.com.cn) 1.nm -D libxxx.so 打印出符号信息. 一般这样用:nm -D libxxx.so |grep T $ ...
- vue过滤器 - filters
在数据被渲染之前,可以对其进行进一步处理,比如将字符截取或者将小写统一转换为大写等等,过滤器本身就是一个方法. 过滤器可以定义全局或局部 # 全局 // 回调函数中的参数1永久是绑定的数据 Vue.f ...
- Vue学习:10.v标签综合-进阶版
再来一节v标签综合... 实例:水果购物车 实现功能: 显示水果列表:展示可供选择的水果列表,包括名称.价格等信息. 修改水果数量:允许用户在购物车中增加或减少水果的数量. 删除水果:允许用户从购物车 ...
- 🌟 简单理解 React 的 createContext 和 Provider 🚀
在 React 应用中,我们经常需要在组件之间共享状态和数据.而 React 的 createContext 和 Provider 就是为了解决这个问题而诞生的. createContext:创建自定 ...
- linux elasticsearch-8.2.0安装
1.下载,解压缩,命令行前不要留空格 官网下载地址: https://www.elastic.co/cn/downloads/elasticsearch https://artifacts.elast ...
- FreeRTOS简单内核实现3 任务管理
0.思考与回答 0.1.思考一 对于 Cotex-M4 内核的 MCU 在发生异常/中断时,哪些寄存器会自动入栈,哪些需要手动入栈? 会自动入栈的寄存器如下 R0 - R3:通用寄存器 R12:通用寄 ...
- 探索Semantic Kernel内置插件:深入了解ConversationSummaryPlugin的应用
前言 经过前几章的学习我们已经熟悉了Semantic Kernel 插件的概念,以及基于Prompts构造的Semantic Plugins和基于本地方法构建的Native Plugins.本章我们来 ...
- DELL服务器安装racadm检测服务器硬件状态
1.下载racadm命令 For Linux 7及以上版本: https://dl.dell.com/FOLDER07423496M/1/DellEMC-iDRACTools-Web-LX-10.1. ...
- 麒麟操作系统V10安装mysql8.0.26
今年mysql装得有点多,大概有4次了,快变系统工程师了! 本文重点说下如何识别版本和配置服务! 首先两点: 1)麒麟本质是linux内核,所以基本上centos的操作在这里可以通用 2)虽然通用,但 ...
- Ubuntu 22.04扩容LVM空间
今天为了编译ThingsBoard的源代码,发现原来给虚拟机分配的40个G不够用了.于是乎在VMWare Workstation中扩容了40G的磁盘空间.但是此时lvm是不会自动扩容的,因此我们需要手 ...