spark读取hive表,org.apache.spark.sql.AnalysisException: Unsupported data source type for direct query on files: hive;
异常出现:spark读取hive表时,spark.read.table(hive.test)
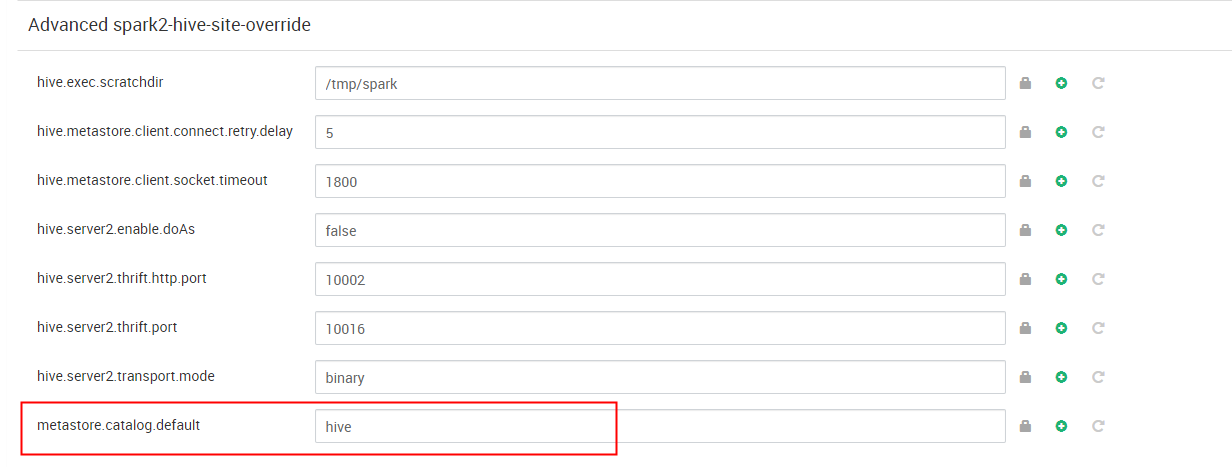
hdp版本的spark默认的catalog是spark,配置项 metastore.catalog.default 默认值是spark,即读取SparkSQL自己的metastore_db。所以才会出现上述相互是查看不到的对方的创建的数据的问题。
org.apache.spark.sql.AnalysisException: Unsupported data source type for direct query on files: hive;;
at org.apache.spark.sql.catalyst.analysis.package$AnalysisErrorAt.failAnalysis(package.scala:47)
at org.apache.spark.sql.execution.datasources.ResolveSQLOnFile$$anonfun$apply$1.applyOrElse(rules.scala:64)
at org.apache.spark.sql.execution.datasources.ResolveSQLOnFile$$anonfun$apply$1.applyOrElse(rules.scala:42)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$transformUp$1.apply(TreeNode.scala:289)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$transformUp$1.apply(TreeNode.scala:289)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:70)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:288)
at org.apache.spark.sql.execution.datasources.ResolveSQLOnFile.apply(rules.scala:42)
at org.apache.spark.sql.execution.datasources.ResolveSQLOnFile.apply(rules.scala:37)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1$$anonfun$apply$1.apply(RuleExecutor.scala:87)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1$$anonfun$apply$1.apply(RuleExecutor.scala:84)
at scala.collection.LinearSeqOptimized$class.foldLeft(LinearSeqOptimized.scala:124)
at scala.collection.immutable.List.foldLeft(List.scala:84)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1.apply(RuleExecutor.scala:84)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1.apply(RuleExecutor.scala:76)
at scala.collection.immutable.List.foreach(List.scala:381)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.execute(RuleExecutor.scala:76)
at org.apache.spark.sql.catalyst.analysis.Analyzer.org$apache$spark$sql$catalyst$analysis$Analyzer$$executeSameContext(Analyzer.scala:124)
at org.apache.spark.sql.catalyst.analysis.Analyzer.execute(Analyzer.scala:118)
at org.apache.spark.sql.catalyst.analysis.Analyzer.executeAndCheck(Analyzer.scala:103)
at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:57)
at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:55)
at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:47)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:74)
at org.apache.spark.sql.SparkSession.table(SparkSession.scala:628)
at org.apache.spark.sql.SparkSession.table(SparkSession.scala:624)
at org.apache.spark.sql.DataFrameReader.table(DataFrameReader.scala:654)
... 49 elided
Caused by: org.apache.spark.sql.AnalysisException: Unsupported data source type for direct query on files: hive;
at org.apache.spark.sql.execution.datasources.ResolveSQLOnFile$$anonfun$apply$1.applyOrElse(rules.scala:56)
... 74 more
spark读取hive表,org.apache.spark.sql.AnalysisException: Unsupported data source type for direct query on files: hive;的更多相关文章
- 【原创】大叔经验分享(60)hive和spark读取kudu表
从impala中创建kudu表之后,如果想从hive或spark sql直接读取,会报错: Caused by: java.lang.ClassNotFoundException: com.cloud ...
- Spark(1) - Getting Started with Apache Spark
Introduction Apache Spark is a general-purpose cluster computing system to process big data workload ...
- java.lang.NoSuchMethodError: org.apache.spark.internal.Logging.$init$(Lorg/apache/spark/internal/Logging;)V
1.sparkML的版本不对应 请参考官网找到对于版本, 比如我的 spark2.3.3 spark MLlib 也是2.3.3
- Caused by: java.sql.SQLException: Failed to start database 'metastore_db' with class loader org.apache.spark.sql.hive.client.IsolatedClientLoader$$anon$1@d7c365, see the next exception for details.
解决方法:https://stackoverflow.com/questions/37442910/spark-shell-startup-errors 异常: 18/01/29 19:04:27 W ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- spark相关介绍-提取hive表(一)
本文环境说明 centos服务器 jupyter的scala核spylon-kernel spark-2.4.0 scala-2.11.12 hadoop-2.6.0 本文主要内容 spark读取hi ...
- Spark访问与HBase关联的Hive表
知识点1:创建关联Hbase的Hive表 知识点2:Spark访问Hive 知识点3:Spark访问与Hbase关联的Hive表 知识点1:创建关联Hbase的Hive表 两种方式创建,内部表和外部表 ...
- Spark记录-本地Spark读取Hive数据简单例子
注意:将mysql的驱动包拷贝到spark/lib下,将hive-site.xml拷贝到项目resources下,远程调试不要使用主机名 import org.apache.spark._ impor ...
- 新手福利:Apache Spark入门攻略
[编者按]时至今日,Spark已成为大数据领域最火的一个开源项目,具备高性能.易于使用等特性.然而作为一个年轻的开源项目,其使用上存在的挑战亦不可为不大,这里为大家分享SciSpike软件架构师Ash ...
随机推荐
- [GPT] Linux 如何查看 crontab 的运行记录
要查看crontab的运行记录,可以使用以下命令: $ grep CRON /var/log/syslog 或者 $ tail /var/log/syslog 这将在 /var/log/syslo ...
- 使用Elasticsearch在Rails中进行全文本搜索
使用Elasticsearch在Rails中进行全文本搜索 参考: https://blog.csdn.net/cunjie3951/article/details/106921108
- WEB服务与NGINX(26)- 实现Nginx高并发系统内核参数优化
1. 实现Nginx高并发系统内核参数优化 由于默认的Linux内核参数考虑的是最通用场景,这明显不符合用于支持高并发访问的Web服务器的定义,所以需要修改Linux内核参数,使得Nginx可以拥有更 ...
- iPad 远程控制 Mac 电脑远程办公的终极解决方案
作为安全技术人员来说,用 iPad 远程控制 Mac 电脑,在我看来是一件很酷的事情! 首先吐槽一下自己为什么会有这个奇怪的想法,原因是因为,目前我有一个16寸的mac,我每天下班的第一个动作就是先把 ...
- Mark Lee:Splashtop 如何成为最新的 10 亿美元估值技术独角兽
从左至右:Splashtop联合创始人Rob.Philip.Mark和Thomas Splashtop 刚刚完成了由我们的长期投资者 Sapphire Ventures 领投的 5000 万美元的新融 ...
- paramiko连接windows10详解,远程管理windows服务器
1.win10安装 OpenSSH 官网链接:https://docs.microsoft.com/zh-cn/windows-server/administration/openssh/openss ...
- 慢查询SQL优化
记一次慢查询的SQL优化 测试表结构 MariaDB [shoppings]> desc login_userinfo; +------------+-------------+------+- ...
- pwn杂项之linux命令执行
通常pwn题目,时常会考到对Linux命令的一些使用,比如当cat被禁用的时候,可以使用tac,或者别的命令代替 下面是buu上的应该题目,考察的就是对liunx命令的理解,以及对程序的分析. 题目地 ...
- 异构数据源同步之数据同步 → datax 再改造,开始触及源码
开心一刻 其实追女生,没那么复杂 只要你花心思,花时间,陪她聊天,带她吃好吃的,耍好玩的,买好看的 慢慢你就会发现什么叫做 打水漂 不说了,我要去陪她看电影了 前情回顾 异构数据源同步之数据同步 → ...
- 解决老旧电脑在win7中浏览器访问https网站出现的Let‘sEncrypt证书过期的问题
原因LetsEncrypt证书未过期,但是其顶级ca根证书 "DST Root CA X3"在2021-09-01过期了,老旧设备上的win系统会被影响到. 解决步骤下载三张Let ...