自然语言处理 Paddle NLP - 情感分析技术及应用SKEP-实践
Part A. 情感分析任务
众所周知,人类自然语言中包含了丰富的情感色彩:表达人的情绪(如悲伤、快乐)、表达人的心情(如倦怠、忧郁)、表达人的喜好(如喜欢、讨厌)、表达人的个性特征和表达人的立场等等。情感分析在商品喜好、消费决策、舆情分析等场景中均有应用。利用机器自动分析这些情感倾向,不但有助于帮助企业了解消费者对其产品的感受,为产品改进提供依据;同时还有助于企业分析商业伙伴们的态度,以便更好地进行商业决策。
被人们所熟知的情感分析任务是将一段文本分类,如分为情感极性为正向、负向、其他的三分类问题:
情感分析任务

- 正向: 表示正面积极的情感,如高兴,幸福,惊喜,期待等。
- 负向: 表示负面消极的情感,如难过,伤心,愤怒,惊恐等。
- 其他: 其他类型的情感。
实际上,以上熟悉的情感分析任务是句子级情感分析任务。
情感分析任务还可以进一步分为句子级情感分析、目标级情感分析等任务。在下面章节将会详细介绍两种任务及其应用场景。
Part B. 情感分析预训练模型SKEP
近年来,大量的研究表明基于大型语料库的预训练模型(Pretrained Models, PTM)可以学习通用的语言表示,有利于下游NLP任务,同时能够避免从零开始训练模型。随着计算能力的发展,深度模型的出现(即 Transformer)和训练技巧的增强使得 PTM 不断发展,由浅变深。
情感预训练模型SKEP(Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis)。SKEP利用情感知识增强预训练模型, 在14项中英情感分析典型任务上全面超越SOTA,此工作已经被ACL 2020录用。SKEP是百度研究团队提出的基于情感知识增强的情感预训练算法,此算法采用无监督方法自动挖掘情感知识,然后利用情感知识构建预训练目标,从而让机器学会理解情感语义。SKEP为各类情感分析任务提供统一且强大的情感语义表示。
论文地址:https://arxiv.org/abs/2005.05635
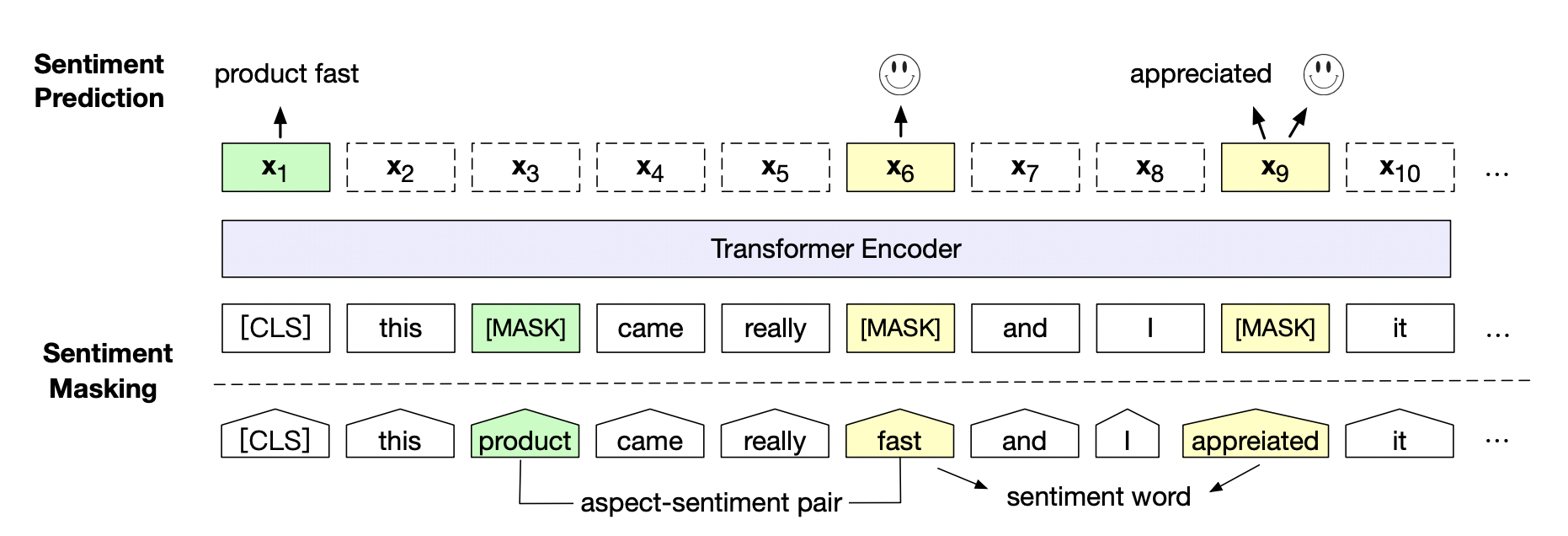
百度研究团队在三个典型情感分析任务,句子级情感分类(Sentence-level Sentiment Classification),评价目标级情感分类(Aspect-level Sentiment Classification)、观点抽取(Opinion Role Labeling),共计14个中英文数据上进一步验证了情感预训练模型SKEP的效果。
具体实验效果参考:https://github.com/baidu/Senta#skep
Part C 句子级情感分析 & 目标级情感分析
Part C.1 句子级情感分析
对给定的一段文本进行情感极性分类,常用于影评分析、网络论坛舆情分析等场景。如:
选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。酒店装修一般,但还算整洁。 泳池在大堂的屋顶,因此很小,不过女儿倒是喜欢。 包的早餐是西式的,还算丰富。 服务吗,一般 1
15.4寸笔记本的键盘确实爽,基本跟台式机差不多了,蛮喜欢数字小键盘,输数字特方便,样子也很美观,做工也相当不错 1
房间太小。其他的都一般。。。。。。。。。 0
其中1表示正向情感,0表示负向情感。
句子级情感分析任务
常用数据集
ChnSenticorp数据集是公开中文情感分析常用数据集, 其为2分类数据集。PaddleNLP已经内置该数据集,一键即可加载。
from paddlenlp.datasets import load_dataset
train_ds, dev_ds, test_ds = load_dataset("chnsenticorp", splits=["train", "dev", "test"])
print(train_ds[0])
print(train_ds[1])
print(train_ds[:10])
100%|██████████| 1909/1909 [00:00<00:00, 37287.30it/s]
{'text': '选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。酒店装修一般,但还算整洁。 泳池在大堂的屋顶,因此很小,不过女儿倒是喜欢。 包的早餐是西式的,还算丰富。 服务吗,一般', 'label': 1, 'qid': ''}
{'text': '15.4寸笔记本的键盘确实爽,基本跟台式机差不多了,蛮喜欢数字小键盘,输数字特方便,样子也很美观,做工也相当不错', 'label': 1, 'qid': ''}
[{'text': '选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。酒店装修一般,但还算整洁。 泳池在大堂的屋顶,因此很小,不过女儿倒是喜欢。 包的早餐是西式的,还算丰富。 服务吗,一般', 'label': 1, 'qid': ''}, {'text': '15.4寸笔记本的键盘确实爽,基本跟台式机差不多了,蛮喜欢数字小键盘,输数字特方便,样子也很美观,做工也相当不错', 'label': 1, 'qid': ''}, {'text': '房间太小。其他的都一般。。。。。。。。。', 'label': 0, 'qid': ''}, {'text': '1.接电源没有几分钟,电源适配器热的不行. 2.摄像头用不起来. 3.机盖的钢琴漆,手不能摸,一摸一个印. 4.硬盘分区不好办.', 'label': 0, 'qid': ''}, {'text': '今天才知道这书还有第6卷,真有点郁闷:为什么同一套书有两种版本呢?当当网是不是该跟出版社商量商量,单独出个第6卷,让我们的孩子不会有所遗憾。', 'label': 1, 'qid': ''}, {'text': '机器背面似乎被撕了张什么标签,残胶还在。但是又看不出是什么标签不见了,该有的都在,怪', 'label': 0, 'qid': ''}, {'text': '呵呵,虽然表皮看上去不错很精致,但是我还是能看得出来是盗的。但是里面的内容真的不错,我妈爱看,我自己也学着找一些穴位。', 'label': 0, 'qid': ''}, {'text': '这本书实在是太烂了,以前听浙大的老师说这本书怎么怎么不对,哪些地方都是误导的还不相信,终于买了一本看一下,发现真是~~~无语,这种书都写得出来', 'label': 0, 'qid': ''}, {'text': '地理位置佳,在市中心。酒店服务好、早餐品种丰富。我住的商务数码房电脑宽带速度满意,房间还算干净,离湖南路小吃街近。', 'label': 1, 'qid': ''}, {'text': '5.1期间在这住的,位置还可以,在市委市政府附近,要去商业区和步行街得打车,屋里有蚊子,虽然空间挺大,晚上熄灯后把窗帘拉上简直是伸手不见五指,很适合睡觉,但是会被该死的蚊子吵醒!打死了两只,第二天早上还是发现又没打死的,卫生间挺大,但是设备很老旧。', 'label': 1, 'qid': ''}]
SKEP模型加载
PaddleNLP已经实现了SKEP预训练模型,可以通过一行代码实现SKEP加载。
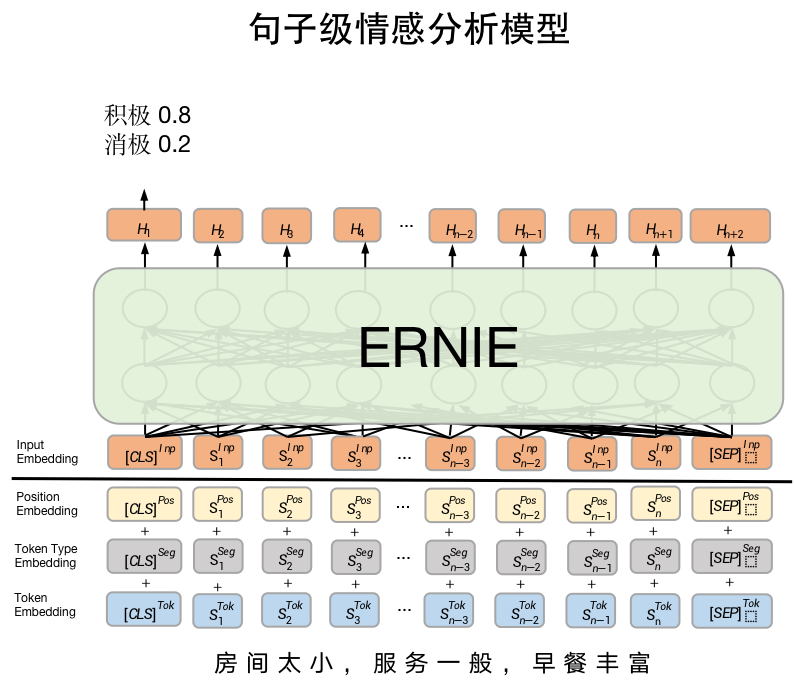
句子级情感分析模型是SKEP fine-tune 文本分类常用模型SkepForSequenceClassification。其首先通过SKEP提取句子语义特征,之后将语义特征进行分类。
from paddlenlp.transformers import SkepForSequenceClassification, SkepTokenizer
# 指定模型名称,一键加载模型
model = SkepForSequenceClassification.from_pretrained(pretrained_model_name_or_path="skep_ernie_1.0_large_ch", num_classes=len(train_ds.label_list))
# 同样地,通过指定模型名称一键加载对应的Tokenizer,用于处理文本数据,如切分token,转token_id等。
tokenizer = SkepTokenizer.from_pretrained(pretrained_model_name_or_path="skep_ernie_1.0_large_ch")
[2023-06-09 11:33:08,208] [ INFO] - Downloading https://paddlenlp.bj.bcebos.com/models/transformers/skep/skep_ernie_1.0_large_ch.pdparams and saved to /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch
[2023-06-09 11:33:08,211] [ INFO] - Downloading skep_ernie_1.0_large_ch.pdparams from https://paddlenlp.bj.bcebos.com/models/transformers/skep/skep_ernie_1.0_large_ch.pdparams
100%|██████████| 1238309/1238309 [00:30<00:00, 40700.73it/s]
W0609 11:33:38.774677 148 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0609 11:33:38.778790 148 device_context.cc:465] device: 0, cuDNN Version: 8.2.
[2023-06-09 11:33:46,676] [ INFO] - Downloading https://paddlenlp.bj.bcebos.com/models/transformers/skep/skep_ernie_1.0_large_ch.vocab.txt and saved to /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch
[2023-06-09 11:33:46,679] [ INFO] - Downloading skep_ernie_1.0_large_ch.vocab.txt from https://paddlenlp.bj.bcebos.com/models/transformers/skep/skep_ernie_1.0_large_ch.vocab.txt
100%|██████████| 55/55 [00:00<00:00, 5570.66it/s]
SkepForSequenceClassification可用于句子级情感分析和目标级情感分析任务。其通过预训练模型SKEP获取输入文本的表示,之后将文本表示进行分类。
pretrained_model_name_or_path:模型名称。支持"skep_ernie_1.0_large_ch","skep_ernie_2.0_large_en"。- "skep_ernie_1.0_large_ch":是SKEP模型在预训练ernie_1.0_large_ch基础之上在海量中文数据上继续预训练得到的中文预训练模型;
- "skep_ernie_2.0_large_en":是SKEP模型在预训练ernie_2.0_large_en基础之上在海量英文数据上继续预训练得到的英文预训练模型;
num_classes: 数据集分类类别数。
关于SKEP模型实现详细信息参考:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/paddlenlp/transformers/skep
数据处理
同样地,我们需要将原始ChnSentiCorp数据处理成模型可以读入的数据格式。
SKEP模型对中文文本处理按照字粒度进行处理,我们可以使用PaddleNLP内置的SkepTokenizer完成一键式处理。
import os
from functools import partial
import numpy as np
import paddle
import paddle.nn.functional as F
from paddlenlp.data import Stack, Tuple, Pad
from utils import create_dataloader
def convert_example(example,
tokenizer,
max_seq_length=512,
is_test=False):
"""
Builds model inputs from a sequence or a pair of sequence for sequence classification tasks
by concatenating and adding special tokens. And creates a mask from the two sequences passed
to be used in a sequence-pair classification task.
A skep_ernie_1.0_large_ch/skep_ernie_2.0_large_en sequence has the following format:
::
- single sequence: ``[CLS] X [SEP]``
- pair of sequences: ``[CLS] A [SEP] B [SEP]``
A skep_ernie_1.0_large_ch/skep_ernie_2.0_large_en sequence pair mask has the following format:
::
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
| first sequence | second sequence |
If `token_ids_1` is `None`, this method only returns the first portion of the mask (0s).
Args:
example(obj:`list[str]`): List of input data, containing text and label if it have label.
tokenizer(obj:`PretrainedTokenizer`): This tokenizer inherits from :class:`~paddlenlp.transformers.PretrainedTokenizer`
which contains most of the methods. Users should refer to the superclass for more information regarding methods.
max_seq_len(obj:`int`): The maximum total input sequence length after tokenization.
Sequences longer than this will be truncated, sequences shorter will be padded.
is_test(obj:`False`, defaults to `False`): Whether the example contains label or not.
Returns:
input_ids(obj:`list[int]`): The list of token ids.
token_type_ids(obj: `list[int]`): List of sequence pair mask.
label(obj:`int`, optional): The input label if not is_test.
"""
# 将原数据处理成model可读入的格式,enocded_inputs是一个dict,包含input_ids、token_type_ids等字段
encoded_inputs = tokenizer(
text=example["text"], max_seq_len=max_seq_length)
# input_ids:对文本切分token后,在词汇表中对应的token id
input_ids = encoded_inputs["input_ids"]
# token_type_ids:当前token属于句子1还是句子2,即上述图中表达的segment ids
token_type_ids = encoded_inputs["token_type_ids"]
if not is_test:
# label:情感极性类别
label = np.array([example["label"]], dtype="int64")
return input_ids, token_type_ids, label
else:
# qid:每条数据的编号
qid = np.array([example["qid"]], dtype="int64")
return input_ids, token_type_ids, qid
# 批量数据大小
batch_size = 32
# 文本序列最大长度
max_seq_length = 256
# 将数据处理成模型可读入的数据格式
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
# 将数据组成批量式数据,如
# 将不同长度的文本序列padding到批量式数据中最大长度
# 将每条数据label堆叠在一起
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
Stack() # labels
): [data for data in fn(samples)]
train_data_loader = create_dataloader(
train_ds,
mode='train',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
dev_data_loader = create_dataloader(
dev_ds,
mode='dev',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
模型训练和评估
定义损失函数、优化器以及评价指标后,即可开始训练。
推荐超参设置:
max_seq_length=256batch_size=48learning_rate=2e-5epochs=10
实际运行时可以根据显存大小调整batch_size和max_seq_length大小。
import time
from utils import evaluate
# 训练轮次
epochs = 1
# 训练过程中保存模型参数的文件夹
ckpt_dir = "skep_ckpt"
# len(train_data_loader)一轮训练所需要的step数
num_training_steps = len(train_data_loader) * epochs
# Adam优化器
optimizer = paddle.optimizer.AdamW(
learning_rate=2e-5,
parameters=model.parameters())
# 交叉熵损失函数
criterion = paddle.nn.loss.CrossEntropyLoss()
# accuracy评价指标
metric = paddle.metric.Accuracy()
# 开启训练
global_step = 0
tic_train = time.time()
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, token_type_ids, labels = batch
# 喂数据给model
logits = model(input_ids, token_type_ids)
# 计算损失函数值
loss = criterion(logits, labels)
# 预测分类概率值
probs = F.softmax(logits, axis=1)
# 计算acc
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
if global_step % 10 == 0:
print(
"global step %d, epoch: %d, batch: %d, loss: %.5f, accu: %.5f, speed: %.2f step/s"
% (global_step, epoch, step, loss, acc,
10 / (time.time() - tic_train)))
tic_train = time.time()
# 反向梯度回传,更新参数
loss.backward()
optimizer.step()
optimizer.clear_grad()
if global_step % 100 == 0:
save_dir = os.path.join(ckpt_dir, "model_%d" % global_step)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 评估当前训练的模型
evaluate(model, criterion, metric, dev_data_loader)
# 保存当前模型参数等
model.save_pretrained(save_dir)
# 保存tokenizer的词表等
tokenizer.save_pretrained(save_dir)
global step 10, epoch: 1, batch: 10, loss: 0.68203, accu: 0.56875, speed: 2.49 step/s
global step 20, epoch: 1, batch: 20, loss: 0.67362, accu: 0.60313, speed: 3.92 step/s
global step 30, epoch: 1, batch: 30, loss: 0.32944, accu: 0.67812, speed: 3.74 step/s
global step 40, epoch: 1, batch: 40, loss: 0.23817, accu: 0.73203, speed: 3.60 step/s
global step 50, epoch: 1, batch: 50, loss: 0.22706, accu: 0.76812, speed: 3.69 step/s
global step 60, epoch: 1, batch: 60, loss: 0.32217, accu: 0.79010, speed: 3.65 step/s
global step 70, epoch: 1, batch: 70, loss: 0.38290, accu: 0.80848, speed: 3.99 step/s
global step 80, epoch: 1, batch: 80, loss: 0.32560, accu: 0.81914, speed: 3.81 step/s
global step 90, epoch: 1, batch: 90, loss: 0.28812, accu: 0.83090, speed: 3.69 step/s
global step 100, epoch: 1, batch: 100, loss: 0.08818, accu: 0.83906, speed: 3.68 step/s
eval loss: 0.22184, accu: 0.91250
global step 110, epoch: 1, batch: 110, loss: 0.19725, accu: 0.90312, speed: 1.06 step/s
global step 120, epoch: 1, batch: 120, loss: 0.13100, accu: 0.90781, speed: 3.58 step/s
global step 130, epoch: 1, batch: 130, loss: 0.19981, accu: 0.90833, speed: 3.68 step/s
global step 140, epoch: 1, batch: 140, loss: 0.15833, accu: 0.90938, speed: 3.77 step/s
global step 150, epoch: 1, batch: 150, loss: 0.11410, accu: 0.91563, speed: 3.76 step/s
global step 160, epoch: 1, batch: 160, loss: 0.22827, accu: 0.91771, speed: 3.78 step/s
global step 170, epoch: 1, batch: 170, loss: 0.13842, accu: 0.91652, speed: 3.62 step/s
global step 180, epoch: 1, batch: 180, loss: 0.03657, accu: 0.91992, speed: 3.88 step/s
global step 190, epoch: 1, batch: 190, loss: 0.20643, accu: 0.91840, speed: 3.65 step/s
global step 200, epoch: 1, batch: 200, loss: 0.40149, accu: 0.91750, speed: 3.84 step/s
eval loss: 0.19440, accu: 0.93083
预测提交结果
使用训练得到的模型还可以对文本进行情感预测。
import numpy as np
import paddle
# 处理测试集数据
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
is_test=True)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # segment
Stack() # qid
): [data for data in fn(samples)]
test_data_loader = create_dataloader(
test_ds,
mode='test',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
# 根据实际运行情况,更换加载的参数路径
params_path = 'skep_ckp/model_500/model_state.pdparams'
if params_path and os.path.isfile(params_path):
# 加载模型参数
state_dict = paddle.load(params_path)
model.set_dict(state_dict)
print("Loaded parameters from %s" % params_path)
label_map = {0: '0', 1: '1'}
results = []
# 切换model模型为评估模式,关闭dropout等随机因素
model.eval()
for batch in test_data_loader:
input_ids, token_type_ids, qids = batch
# 喂数据给模型
logits = model(input_ids, token_type_ids)
# 预测分类
probs = F.softmax(logits, axis=-1)
idx = paddle.argmax(probs, axis=1).numpy()
idx = idx.tolist()
labels = [label_map[i] for i in idx]
qids = qids.numpy().tolist()
results.extend(zip(qids, labels))
res_dir = "./results"
if not os.path.exists(res_dir):
os.makedirs(res_dir)
# 写入预测结果
with open(os.path.join(res_dir, "ChnSentiCorp.tsv"), 'w', encoding="utf8") as f:
f.write("index\tprediction\n")
for qid, label in results:
f.write(str(qid[0])+"\t"+label+"\n")
Part C.2 目标级情感分析
在电商产品分析场景下,除了分析整体商品的情感极性外,还细化到以商品具体的“方面”为分析主体进行情感分析(aspect-level),如下、:
- 这个薯片口味有点咸,太辣了,不过口感很脆。
关于薯片的口味方面是一个负向评价(咸,太辣),然而对于口感方面却是一个正向评价(很脆)。
- 我很喜欢夏威夷,就是这边的海鲜太贵了。
关于夏威夷是一个正向评价(喜欢),然而对于夏威夷的海鲜却是一个负向评价(价格太贵)。
目标级情感分析任务
#### 常用数据集

千言数据集已提供了许多任务常用数据集。
其中情感分析数据集下载链接:https://aistudio.baidu.com/aistudio/competition/detail/50/?isFromLUGE=TRUE
SE-ABSA16_PHNS数据集是关于手机的目标级情感分析数据集。PaddleNLP已经内置了该数据集,加载方式,如下:
train_ds, test_ds = load_dataset("seabsa16", "phns", splits=["train", "test"])
print(train_ds[0])
print(train_ds[1])
print(train_ds[2])
SKEP模型加载
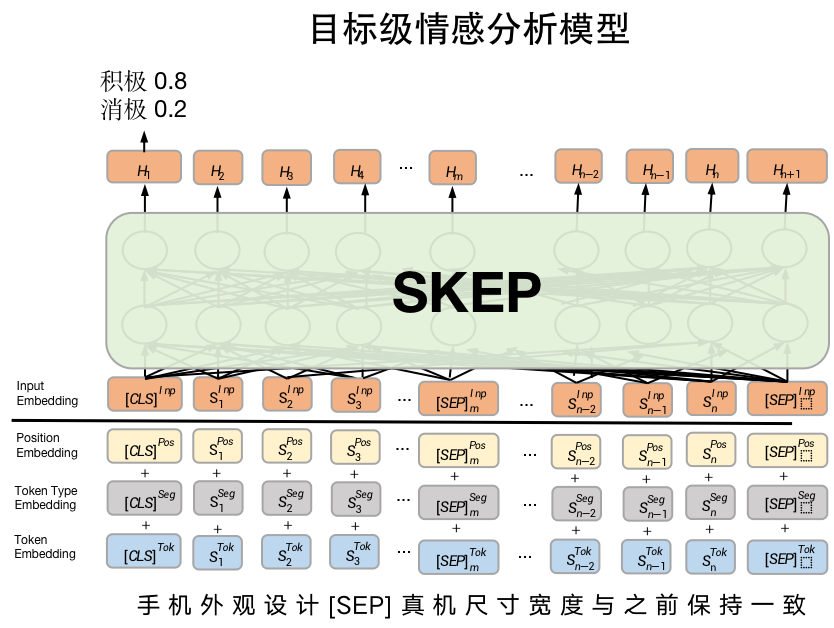
目标级情感分析模型同样使用SkepForSequenceClassification模型,但目标级情感分析模型的输入不单单是一个句子,而是句对。一个句子描述“评价对象方面(aspect)”,另一个句子描述"对该方面的评论"。如下图所示。
# 指定模型名称一键加载模型
model = SkepForSequenceClassification.from_pretrained(
'skep_ernie_1.0_large_ch', num_classes=len(train_ds.label_list))
# 指定模型名称一键加载tokenizer
tokenizer = SkepTokenizer.from_pretrained('skep_ernie_1.0_large_ch')
数据处理
同样地,我们需要将原始SE_ABSA16_PHNS数据处理成模型可以读入的数据格式。
SKEP模型对中文文本处理按照字粒度进行处理,我们可以使用PaddleNLP内置的SkepTokenizer完成一键式处理。
from functools import partial
import os
import time
import numpy as np
import paddle
import paddle.nn.functional as F
from paddlenlp.data import Stack, Tuple, Pad
def convert_example(example,
tokenizer,
max_seq_length=512,
is_test=False,
dataset_name="chnsenticorp"):
"""
Builds model inputs from a sequence or a pair of sequence for sequence classification tasks
by concatenating and adding special tokens. And creates a mask from the two sequences passed
to be used in a sequence-pair classification task.
A skep_ernie_1.0_large_ch/skep_ernie_2.0_large_en sequence has the following format:
::
- single sequence: ``[CLS] X [SEP]``
- pair of sequences: ``[CLS] A [SEP] B [SEP]``
A skep_ernie_1.0_large_ch/skep_ernie_2.0_large_en sequence pair mask has the following format:
::
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
| first sequence | second sequence |
If `token_ids_1` is `None`, this method only returns the first portion of the mask (0s).
note: There is no need token type ids for skep_roberta_large_ch model.
Args:
example(obj:`list[str]`): List of input data, containing text and label if it have label.
tokenizer(obj:`PretrainedTokenizer`): This tokenizer inherits from :class:`~paddlenlp.transformers.PretrainedTokenizer`
which contains most of the methods. Users should refer to the superclass for more information regarding methods.
max_seq_len(obj:`int`): The maximum total input sequence length after tokenization.
Sequences longer than this will be truncated, sequences shorter will be padded.
is_test(obj:`False`, defaults to `False`): Whether the example contains label or not.
dataset_name((obj:`str`, defaults to "chnsenticorp"): The dataset name, "chnsenticorp" or "sst-2".
Returns:
input_ids(obj:`list[int]`): The list of token ids.
token_type_ids(obj: `list[int]`): List of sequence pair mask.
label(obj:`numpy.array`, data type of int64, optional): The input label if not is_test.
"""
encoded_inputs = tokenizer(
text=example["text"],
text_pair=example["text_pair"],
max_seq_len=max_seq_length)
input_ids = encoded_inputs["input_ids"]
token_type_ids = encoded_inputs["token_type_ids"]
if not is_test:
label = np.array([example["label"]], dtype="int64")
return input_ids, token_type_ids, label
else:
return input_ids, token_type_ids
# 处理的最大文本序列长度
max_seq_length=256
# 批量数据大小
batch_size=16
# 将数据处理成model可读入的数据格式
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
# 将数据组成批量式数据,如
# 将不同长度的文本序列padding到批量式数据中最大长度
# 将每条数据label堆叠在一起
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
Stack(dtype="int64") # labels
): [data for data in fn(samples)]
train_data_loader = create_dataloader(
train_ds,
mode='train',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
模型训练
定义损失函数、优化器以及评价指标后,即可开始训练。
# 训练轮次
epochs = 3
# 总共需要训练的step数
num_training_steps = len(train_data_loader) * epochs
# 优化器
optimizer = paddle.optimizer.AdamW(
learning_rate=5e-5,
parameters=model.parameters())
# 交叉熵损失
criterion = paddle.nn.loss.CrossEntropyLoss()
# Accuracy评价指标
metric = paddle.metric.Accuracy()
# 开启训练
ckpt_dir = "skep_aspect"
global_step = 0
tic_train = time.time()
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, token_type_ids, labels = batch
# 喂数据给model
logits = model(input_ids, token_type_ids)
# 计算损失函数值
loss = criterion(logits, labels)
# 预测分类概率
probs = F.softmax(logits, axis=1)
# 计算acc
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
if global_step % 10 == 0:
print(
"global step %d, epoch: %d, batch: %d, loss: %.5f, acc: %.5f, speed: %.2f step/s"
% (global_step, epoch, step, loss, acc,
10 / (time.time() - tic_train)))
tic_train = time.time()
# 反向梯度回传,更新参数
loss.backward()
optimizer.step()
optimizer.clear_grad()
if global_step % 100 == 0:
save_dir = os.path.join(ckpt_dir, "model_%d" % global_step)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 保存模型参数
model.save_pretrained(save_dir)
# 保存tokenizer的词表等
tokenizer.save_pretrained(save_dir)
预测提交结果
使用训练得到的模型还可以对评价对象进行情感预测。
@paddle.no_grad()
def predict(model, data_loader, label_map):
"""
Given a prediction dataset, it gives the prediction results.
Args:
model(obj:`paddle.nn.Layer`): A model to classify texts.
data_loader(obj:`paddle.io.DataLoader`): The dataset loader which generates batches.
label_map(obj:`dict`): The label id (key) to label str (value) map.
"""
model.eval()
results = []
for batch in data_loader:
input_ids, token_type_ids = batch
logits = model(input_ids, token_type_ids)
probs = F.softmax(logits, axis=1)
idx = paddle.argmax(probs, axis=1).numpy()
idx = idx.tolist()
labels = [label_map[i] for i in idx]
results.extend(labels)
return results
# 处理测试集数据
label_map = {0: '0', 1: '1'}
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
is_test=True)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
): [data for data in fn(samples)]
test_data_loader = create_dataloader(
test_ds,
mode='test',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
# 根据实际运行情况,更换加载的参数路径
params_path = 'skep_ckpt/model_900/model_state.pdparams'
if params_path and os.path.isfile(params_path):
# 加载模型参数
state_dict = paddle.load(params_path)
model.set_dict(state_dict)
print("Loaded parameters from %s" % params_path)
results = predict(model, test_data_loader, label_map)
# 写入预测结果
with open(os.path.join("results", "SE-ABSA16_PHNS.tsv"), 'w', encoding="utf8") as f:
f.write("index\tprediction\n")
for idx, label in enumerate(results):
f.write(str(idx)+"\t"+label+"\n")
自然语言处理 Paddle NLP - 情感分析技术及应用SKEP-实践的更多相关文章
- NLP情感分析监督学习样本打标
1). 情感打标 a). 全句 单句 标签 好吃是好吃 pos 真材实料 pos 不过感觉一人份的量就有点小贵 neg 点的是肥牛米线 neu b). 全文本 文本 标签 分量足,味道不错,味道也不错 ...
- NLP入门(十)使用LSTM进行文本情感分析
情感分析简介 文本情感分析(Sentiment Analysis)是自然语言处理(NLP)方法中常见的应用,也是一个有趣的基本任务,尤其是以提炼文本情绪内容为目的的分类.它是对带有情感色彩的主观性 ...
- 情感分析snownlp包部分核心代码理解
snownlps是用Python写的个中文情感分析的包,自带了中文正负情感的训练集,主要是评论的语料库.使用的是朴素贝叶斯原理来训练和预测数据.主要看了一下这个包的几个主要的核心代码,看的过程作了一些 ...
- NLP之中文自然语言处理工具库:SnowNLP(情感分析/分词/自动摘要)
一 安装与介绍 1.1 概述 SnowNLP是一个python写的类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个 ...
- Stanford NLP学习笔记:7. 情感分析(Sentiment)
1. 什么是情感分析(别名:观点提取,主题分析,情感挖掘...) 应用: 1)正面VS负面的影评(影片分类问题) 2)产品/品牌评价: Google产品搜索 3)twitter情感预测股票市场行情/消 ...
- 浅谈NLP 文本分类/情感分析 任务中的文本预处理工作
目录 浅谈NLP 文本分类/情感分析 任务中的文本预处理工作 前言 NLP相关的文本预处理 浅谈NLP 文本分类/情感分析 任务中的文本预处理工作 前言 之所以心血来潮想写这篇博客,是因为最近在关注N ...
- 如何科学地蹭热点:用python爬虫获取热门微博评论并进行情感分析
前言:本文主要涉及知识点包括新浪微博爬虫.python对数据库的简单读写.简单的列表数据去重.简单的自然语言处理(snowNLP模块.机器学习).适合有一定编程基础,并对python有所了解的盆友阅读 ...
- 初学者如何查阅自然语言处理(NLP)领域学术资料
1. 国际学术组织.学术会议与学术论文 自然语言处理(natural language processing,NLP)在很大程度上与计算语言学(computational linguistics,CL ...
- 如何使用百度EasyDL进行情感分析
使用百度EasyDL定制化训练和服务平台有一段时间了,越来越能体会到EasyDL的易用性.在此之前我也接触过不少的深度学习平台,如类脑平台.Google的GCP深度学习平台.AWS深度学习平台,但我觉 ...
- 自然语言处理(NLP)相关学习资料/资源
自然语言处理(NLP)相关学习资料/资源 1. 书籍推荐 自然语言处理 统计自然语言处理(第2版) 作者:宗成庆 出版社:清华大学出版社:出版年:2013:页数:570 内容简介:系统地描述了神经网络 ...
随机推荐
- Spring(Bean详解)
GoF之工厂模式 GoF是指二十三种设计模式 GoF23种设计模式可分为三大类: 创建型(5个):解决对象创建问题. 单例模式 工厂方法模式 抽象工厂模式 建造者模式 原型模式 结构型(7个):一些类 ...
- 二进制安装k8s v1.25.4 IPv4/IPv6双栈
二进制安装k8s v1.25.4 IPv4/IPv6双栈 https://github.com/cby-chen/Kubernetes 开源不易,帮忙点个star,谢谢了 介绍 kubernetes( ...
- [Linux]查看硬件及操作系统信息
许多的软件产品对硬件及操作系统等环境是有具体要求的,那么这时候如何快速知晓目标机器的目标资源信息是较为频繁的操作. 命令 全部硬件及系统信息 dmidecode (软硬件全部信息) hostnamec ...
- vulnhub靶场之DRIFTINGBLUES: 5
准备: 攻击机:虚拟机kali.本机win10. 靶机:DriftingBlues: 5,下载地址:https://download.vulnhub.com/driftingblues/driftin ...
- MySQL(九)InnoDB行格式
InnoDB行格式 查看默认行格式: select @@innodb_default_row_format; 查看数据库表使用的行格式 mysql> use atguigudb; Reading ...
- blog图片资源
- OpenAI的离线音频转文本模型 Whisper 的.NET封装项目
whisper介绍 Open AI在2022年9月21日开源了号称其英文语音辨识能力已达到人类水准的Whisper神经网络,且它亦支持其它98种语言的自动语音辨识. Whisper系统所提供的自动语音 ...
- X配置文件xorg.conf分析
X配置文件xorg.conf分析 转载于:http://blog.csdn.NET/comcat/archive/2007/04/02/1549658.aspx 作者:壮志凌云的csdn博客 X的配置 ...
- 百度飞桨(PaddlePaddle)安装
注意:32位pip没有PaddlePaddle源 # 如果报下列错误,检查 Python 版本,不能过高也不要太低,并且不能是 32位的. ERROR: Could not find a versio ...
- Python获取jsonp数据
使用python爬取数据时,有时候会遇到jsonp的数据格式,由于不是json的,所以不能直接使用json.loads()方法来解析,需要先将其转换为json格式,再进行解析.在前面讲了jsonp的原 ...