SQLserver 数据库自定义函数
起源
最近项目开发上使用的SQLserver数据库是2008版本,由于08版本的数据是没有字符串合并(STRING_AGG)这个函数(2017版本及以上支持)的,只有用stuff +for xml path('') 来达到效果。所以才有萌生出了自定义聚合函数的想法。
使用 Visual Studio 创建数据库项目生成调用的 DLL
第一步新建项目:
2008版本选择 文件→新建→项目→SQL Server项目
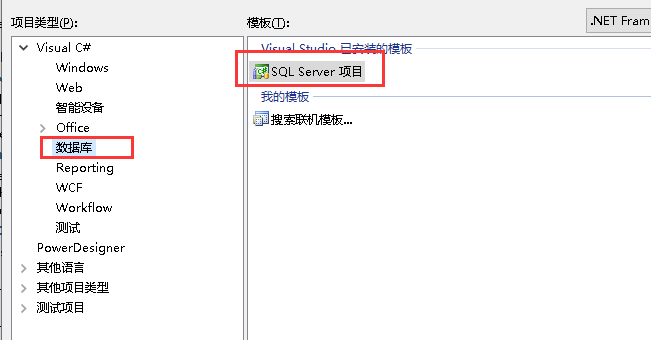
创建成功结果如下:

第二步新建项→聚合:
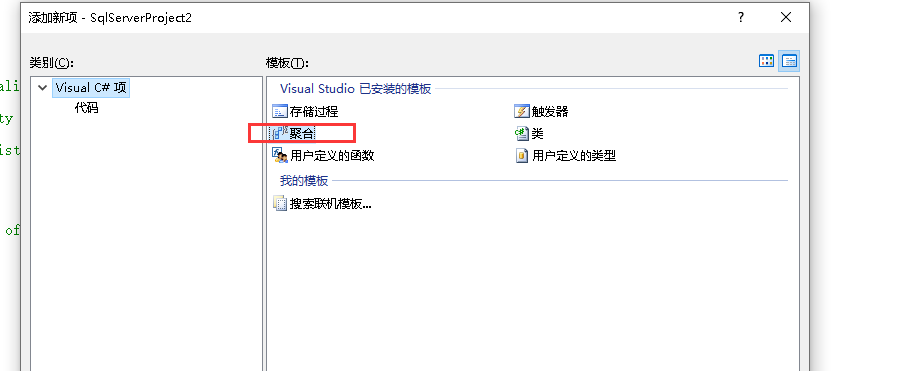
第三步:编写代码(实现字符串合并的函数代码如下)
聚合函数代码
using System;
using System.Data;
using Microsoft.SqlServer.Server;
using System.Data.SqlTypes;
using System.IO;
using System.Text;
[Serializable]
[SqlUserDefinedAggregate(
Format.UserDefined, //use clr serialization to serialize the intermediate result
IsInvariantToNulls = true, //optimizer property
IsInvariantToDuplicates = false, //optimizer property
IsInvariantToOrder = false, //optimizer property
MaxByteSize = 8000) //maximum size in bytes of persisted value
]
public class Concatenate : IBinarySerialize
{
/// <summary>
/// The variable that holds the intermediate result of the concatenation
/// </summary>
private StringBuilder intermediateResult;
/// <summary>
/// Initialize the internal data structures
/// </summary>
public void Init()
{
this.intermediateResult = new StringBuilder();
}
/// <summary>
/// Accumulate the next value, not if the value is null
/// </summary>
/// <param name="value"></param>
public void Accumulate(SqlString value)
{
if (value.IsNull)
{
return;
}
this.intermediateResult.Append(value.Value).Append(',');
}
/// <summary>
/// Merge the partially computed aggregate with this aggregate.
/// </summary>
/// <param name="other"></param>
public void Merge(Concatenate other)
{
this.intermediateResult.Append(other.intermediateResult);
}
/// <summary>
/// Called at the end of aggregation, to return the results of the aggregation.
/// </summary>
/// <returns></returns>
public SqlString Terminate()
{
string output = string.Empty;
//delete the trailing comma, if any
if (this.intermediateResult != null
&& this.intermediateResult.Length > 0)
{
output = this.intermediateResult.ToString(0, this.intermediateResult.Length - 1);
}
return new SqlString(output);
}
public void Read(BinaryReader r)
{
intermediateResult = new StringBuilder(r.ReadString());
}
public void Write(BinaryWriter w)
{
w.Write(this.intermediateResult.ToString());
}
}
第四步:生成项目DLL并放于其他目录下面(非必须,C盘可能存在权限问题在注册时无法使用)
我放在F盘下面的这个路径

SQLserver 注册刚才编写的聚合函数 DLL
第一步:允许SQLserver安装外部程序集
数据库默认是不允许安装外部程序级的,需要通过sp_configure命令 修改clr enabled
/*允许程序使用外部程序集*/
EXEC sp_configure 'clr enabled', 1
RECONFIGURE WITH OVERRIDE
GO
第二步:解决安全权限的配置引发的问题(不执行这一步就会触发安全权限配置问题)
具体链接安全问题链接:https://blog.csdn.net/weixin_34150503/article/details/92828414
/*sp_add_trusted_assembly的方式添加信任到数据库里去.*/
DECLARE @hash AS BINARY(64) = (SELECT HASHBYTES('SHA2_512', (SELECT * FROM OPENROWSET (BULK 'F:\ConactDll\Database3.dll', SINGLE_BLOB) AS [Data])))
第三步:创建程序集与聚合函数
CREATE ASSEMBLY MyAgg FROM 'F:\ConactDll\Database3.dll'
WITH PERMISSION_SET = SAFE;
GO
CREATE AGGREGATE MyAgg (@input nvarchar(200)) RETURNS nvarchar(max)
EXTERNAL NAME MyAgg.Concatenate;
注册完成之后系统数据库会出现我们自定义的聚合函数
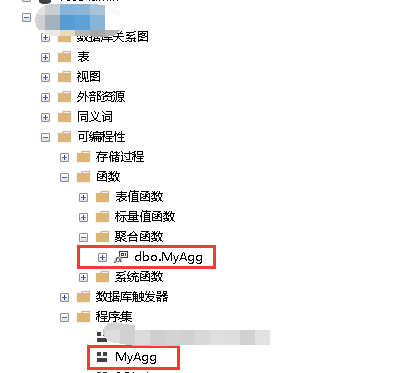
SQL 中使用自定义聚合函数
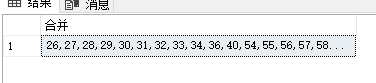
select dbo.myagg(需要合并的表字段) 结果 from 表 where 查询条件
使用效果如下:
额外篇
使用VS2019新建SQLserver数据库项目
第一步:创建项目
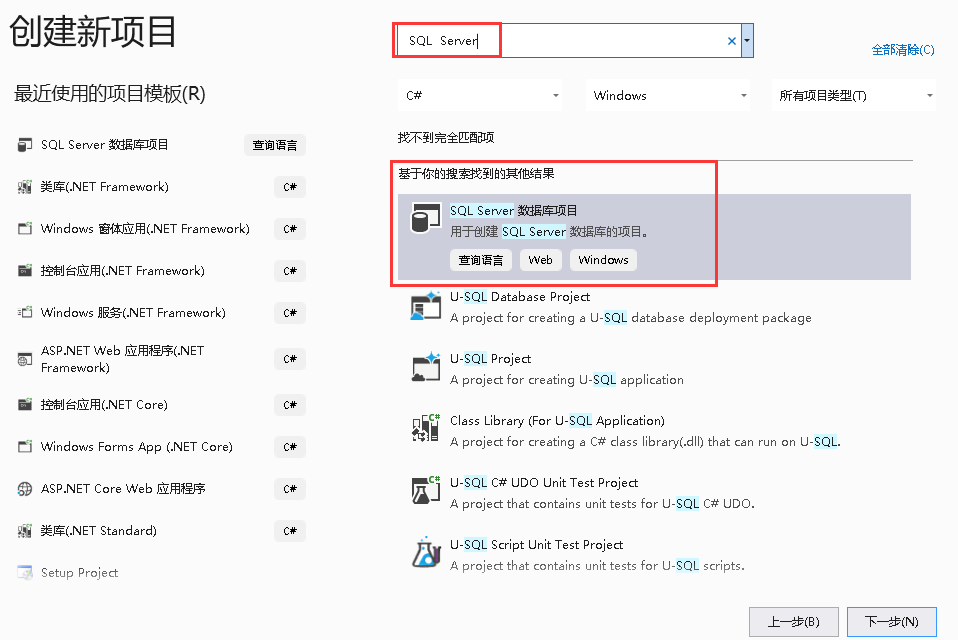

第二步:添加新项
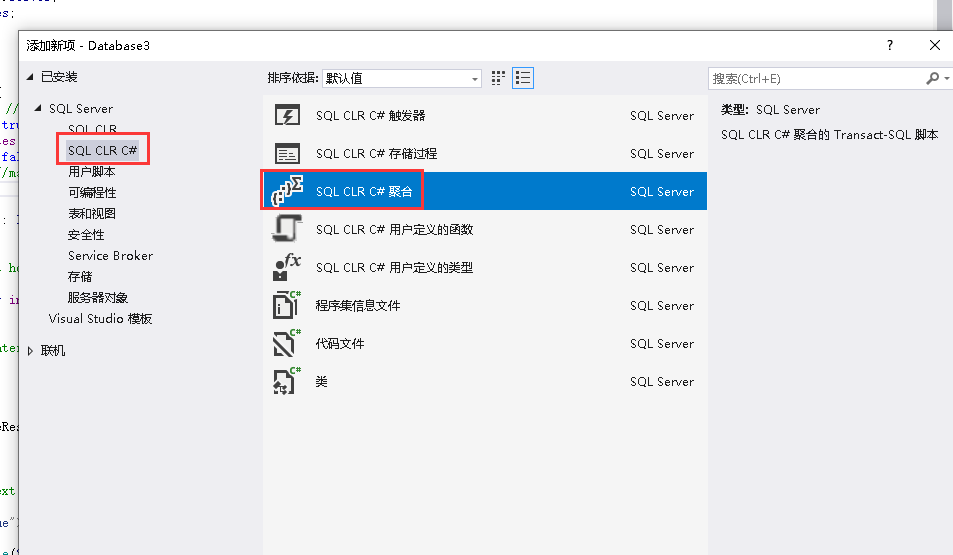
后面就可以开始编写代码了,操作流程跟之前的 08 版本一样
最后附上已经写好的两个版本,需要的同学自取:https://pan.baidu.com/s/1encGUxiMpFcZXLum1zr3Ug 提取码: 8wyq
文章参考:https://dotblogs.com.tw/stanley14/2018/05/26/tsql_string_agg_insql2016
SQLserver 数据库自定义函数的更多相关文章
- sqlserver中自定义函数+存储过程实现批量删除
由于项目的需要,很多模块都要实现批量删除的功能.为了方便模块的调用,把批量删除方法写成自定义函数.直接上代码. 自定义函数: ALTER FUNCTION [dbo].[func_SplitById] ...
- Jpa 重写方言dialect 使用oracle / mysql 数据库自定义函数
在使用criteria api进行查询时 criteriaBuilder只提供了一个部分标准的sql函数,但当我们需要使用oracle特有的行转列函数wm_concat或 mysql特有的行转列函数g ...
- Postgre数据库自定义函数
自定函数 1.查询函数: select prosrc from pg_proc where proname='test' 参数说明 : test 为函数名. 2.删除函数: drop function ...
- 用sqlserver的自定义函数直接获取多级部门全名
好久没写存储过程了,今日正好同事的开发需要,实现显示多级部门的部门全名称. 如 财务部/会计部/会计一部 部门表 人员表 函数 getOrgAllName --OrgID 72 当前的部门ID A ...
- sqlserver 存储过程 自定义函数 游标???
create proc cur_fun( @cur cursor --输入参数 ) as begin declare @mytpye tb1_type ) fetch next from @cur i ...
- orcl数据库自定义函数--金额小写转大写
很多时候在打印票据的时候需要用到大写,ireport无法转换,只能先在查询语句里面进行转换,首先定义好函数,之后再调用函数 CREATE OR REPLACE Function MoneyToChin ...
- Oracle数据库自定义函数练习20181031
--测试函数3 CREATE OR REPLACE FUNCTION FN_TEST3 (NUM IN VARCHAR2) RETURN VARCHAR2 IS TYPE VARCHAR2_ARR ) ...
- Sqlserver中存储过程,触发器,自定义函数(一)
Sqlserver中存储过程,触发器,自定义函数 1.存储过程有关内容存储过程的定义:存储过程的分类:存储过程的创建,修改,执行:存储过程中参数的传递,返回与接收:存储过程的返回值:存储过程使用游标. ...
- Sqlserver中存储过程,触发器,自定义函数
Sqlserver中存储过程,触发器,自定义函数: 1. 触发器:是针对数据库表或数据库的特殊存储过程,在某些行为发生的时候就会被激活 触发器的分类: DML触发器:发生在数据操作语言执行时触发执行的 ...
- 【转载】 Sqlserver中查看自定义函数被哪些对象引用
Sqlserver数据库中支持自定义函数,包含表值函数和标量值函数,表值函数一般返回多个数据行即数据集,而标量值函数一般返回一个值,在数据库的存储过程中可调用自定义函数,也可在该自定义函数中调用另一个 ...
随机推荐
- 《DNK210使用指南 -CanMV版 V1.0》第一章 本书学习方法
第一章 本书学习方法 1)实验平台:正点原子DNK210开发板 2)章节摘自[正点原子]DNK210使用指南 - CanMV版 V1.0 3)购买链接:https://detail.tmall.com ...
- MyBatis插件:通用mapper(tk.mapper)
简单认识通用mapper 了解mapper 作用:就是为了帮助我们自动的生成sql语句 通用mapper是MyBatis的一个插件,是pageHelper的同一个作者进行开发的 作者gitee地址:h ...
- 怎么判断一个变量arr的话是否为数组(此题用 typeof 不行)?
arr instanceof Array arr.constructor == Array Object.protype.toString.call(arr) == '[Object Array]'
- SpringBoot中使用Servlet3.0注解开发自定义的拦截器
使用Servlet3.0的注解进行配置步骤 启动类里面加@ServletComponentScan,进行扫描 新建一个Filter类,implements Filter,并实现对应的接口 @WebFi ...
- JDK9之后 Eureka依赖
<!--Eureka添加依赖开始--> <dependency> <groupId>javax.xml.bind</groupId> <artif ...
- Vue2 移动端 ui库 MintUI
MintUI MintUI是饿了么团队开发的基于移动端的vue组件库.用于搭建移动端界面. http://mint-ui.github.io/docs/#/zh-cn2
- linux date格式化获取时间
转载请注明出处: 在编写shell脚本时,需要在shell脚本中格式化时间,特此整理下date命令相关参数的应用 root@controller1:~# date --help 用法:date [选项 ...
- Nuxt.js 中使用 useHydration 实现数据水合与同步
title: Nuxt.js 中使用 useHydration 实现数据水合与同步 date: 2024/7/18 updated: 2024/7/18 author: cmdragon excerp ...
- 浅谈:HTTP 和 HTTPS 通信原理
1.HTTP基本概念 1.1 HTTP是什么? HTTP (超文本传输协议)协议被用于在 Web 浏览器和网站服务器之间传递信息, HTTP 协议以明文方式发送内容,不提供任何方式的数据加密,如果攻 ...
- Known框架实战演练——进销存框架搭建
本文介绍如何使用Known开发框架搭建进销存管理系统的项目结构,以及开发前的一些配置和基础代码. 项目代码:JxcLite 开源地址: https://gitee.com/known/JxcLite ...