SkipList原理与实现
机制
链表中查询的效率的复杂度是O(n), 有没有办法提升这个查询复杂度呢? 最简单的想法就是在原始的链表上构建多层索引. 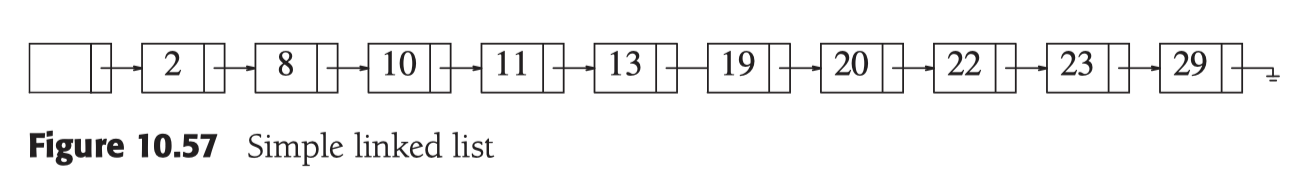
在level 1(最底层为0), 每2位插入一个索引, 查询复杂度便是 O(N/2 + 1) 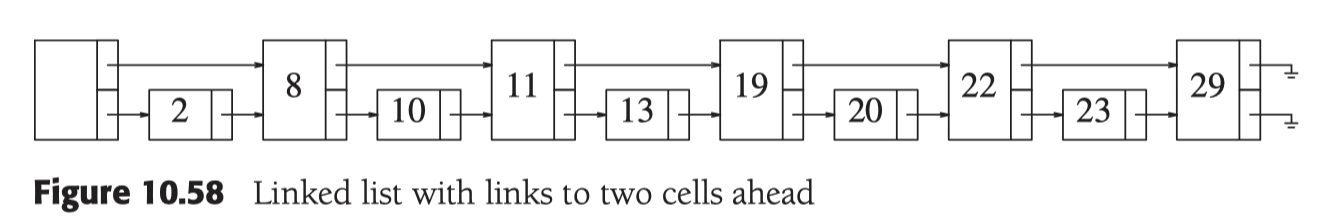
在level 2, 每四位插入一个索引, 查询复杂度便是 O(N/4 + 2) 
那么推广开来, 如果我们有这样的一组链表, 在level i, 每间隔第  元素就有一个链接
元素就有一个链接 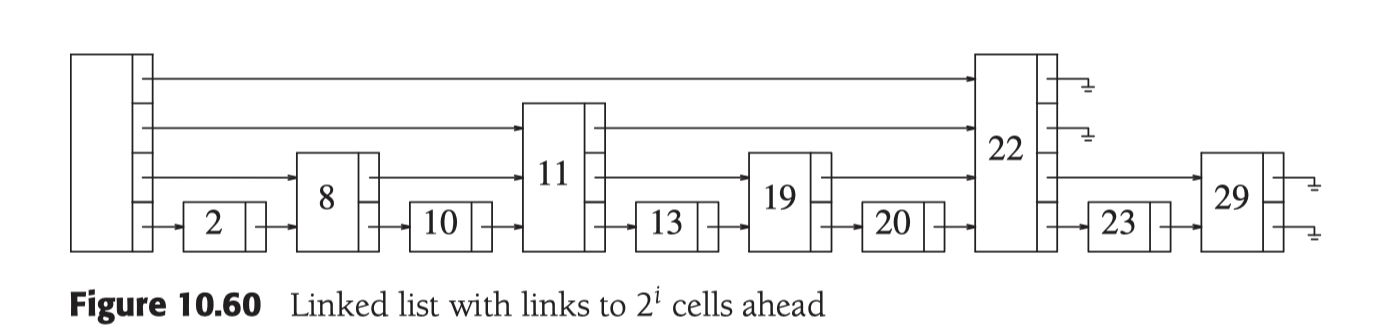 在level 1, 每一个节点之间有一个链接 在level 2, 每两个节点之间有一个链接 在level 3, 每四个节点之间有一个链接 在level 4, 每八个节点之间有一个链接. 这样我们可以看到, 每向上一层, 数据量就减少了 1/2, 所以查询的过程就近似变成了2分查找, 查询性能就变成了稳定的O(logN). 索引的存储空间为
在level 1, 每一个节点之间有一个链接 在level 2, 每两个节点之间有一个链接 在level 3, 每四个节点之间有一个链接 在level 4, 每八个节点之间有一个链接. 这样我们可以看到, 每向上一层, 数据量就减少了 1/2, 所以查询的过程就近似变成了2分查找, 查询性能就变成了稳定的O(logN). 索引的存储空间为 其中
其中 &id=TUi8g)

两式相减得到  所以
所以  所以
所以  因此这样的数据结构总的空间复杂度为 2n - 2.
因此这样的数据结构总的空间复杂度为 2n - 2.
但是这样的数据结构存在一个问题, 严格要求每一层按照  的间隔链接很难在持续插入的过程中维护.
的间隔链接很难在持续插入的过程中维护.
当插入一个新元素的时候, 需要为他分配一个新的节点, 此时我们需要决定该节点是多少阶的. 通过观察 Figure 10.60 可以发现, 有1/2的元素是1阶的, 有 1/4 的元素是2阶的, 所以大约  的节点是第 i 阶的. 那么根据这个性质, 我们就可以通过随机统计的方式来判断新元素应该插入的阶数. 最容易得做法就是抛一枚硬币直到正面出现并把抛硬币的总次数用作该节点的阶数.
的节点是第 i 阶的. 那么根据这个性质, 我们就可以通过随机统计的方式来判断新元素应该插入的阶数. 最容易得做法就是抛一枚硬币直到正面出现并把抛硬币的总次数用作该节点的阶数.
连续抛i次才出现正面的概率是 , 而的节点是属于第 i 阶的.
通常的计算阶数的方法
/**
* 这个函数返回的是levelCount, 最小为1, 表示不构建索引.
*
* <p>
* <li>1/2 概率返回1 表示不用构建索引
* <li>1/2 概率返回2 表示构建一级索引
* <li>1/4 概率返回3 表示构建二级索引
* <li>1/8 概率返回4 表示构建三级索引
*
* @return
*/
private int randomLevel() {
int level = 1;
while (Math.random() < SKIPLIST_P && level < MAX_LEVEL) {
level++;
}
return level;
}通常p取值为 1/2 或者 1/4 表示两层之间的数据分布概率, Math.random()随机返回一个0-1之间的数, 这个就是模拟不断抛硬币的过程, height 为累计的抛硬币的次数.
因此跳表的实现, 是利用了随机化算法来计算新插入节点的阶数, 而这个阶数的数学期望能保证每一层数据能随机化的递减 1/2, 通过这样来保证最终插入和查找复杂度的期望都为 O(logN).
相比于红黑树 优势
插入 查找 删除的复杂度和红黑树一样
区间查找的效率更高
代码实现更简单
并且可以通过插入节点阶数生成的策略来平衡时间和空间复杂度的不同需求. 比如我们可以让每一层的数据为下一层的1/3. 这种情况下索引存储量 为 n/3 + n/9 + n/27 + ... 2 = n / 2 空间占用就缩小一半.
劣势
跳表的内存占用相比会大一点, 不过因为索引其实可以只存储key和指针, 实际的空间开销往往没有那么大
实现
查找
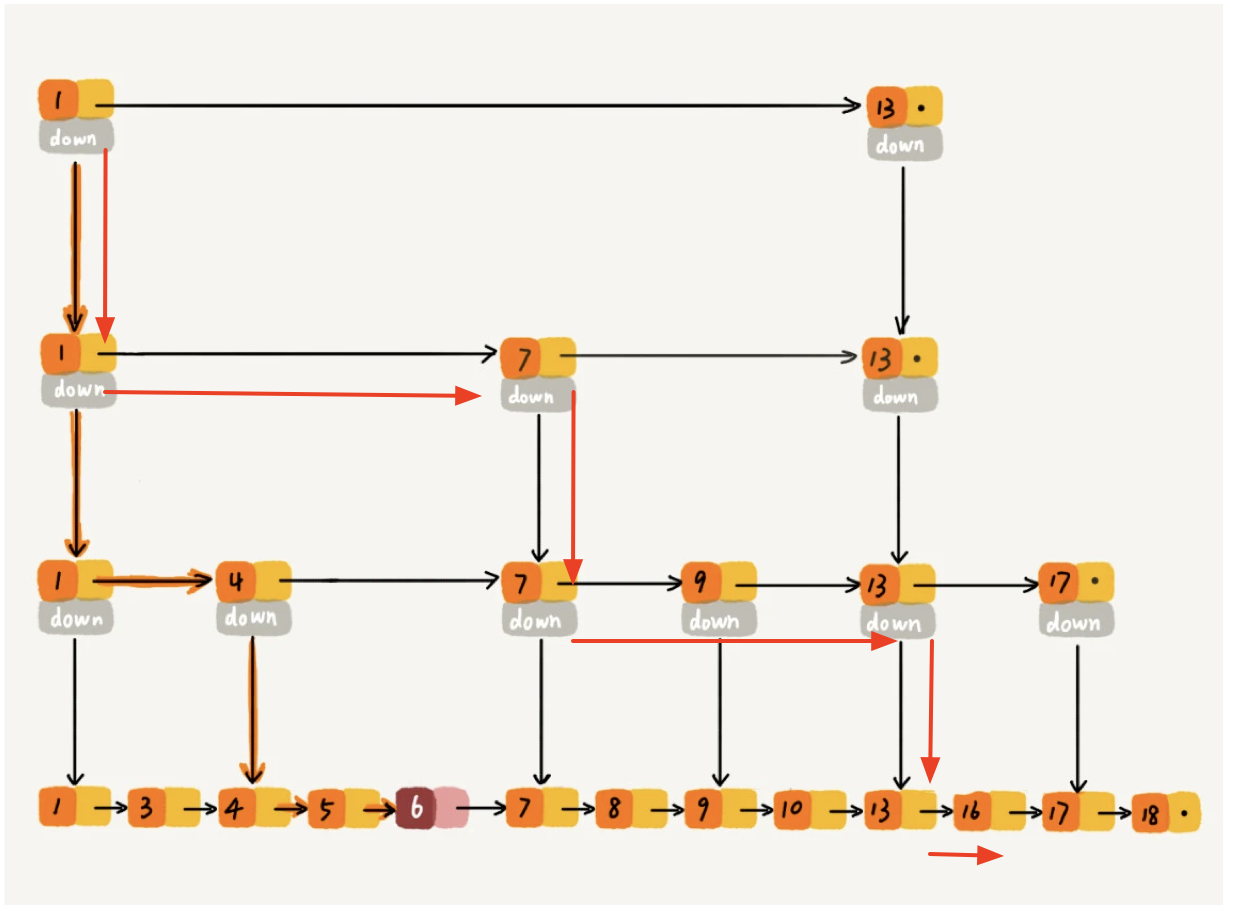 例如查找16
例如查找16
从head处开始查找, 同一层中遍历向前直到next节点为空或者next节点的value大于当前值
跳转到level + 1的索引处, 继续上述流程
最后一定会到达level 0. 指针非空则找到了相应的value
插入
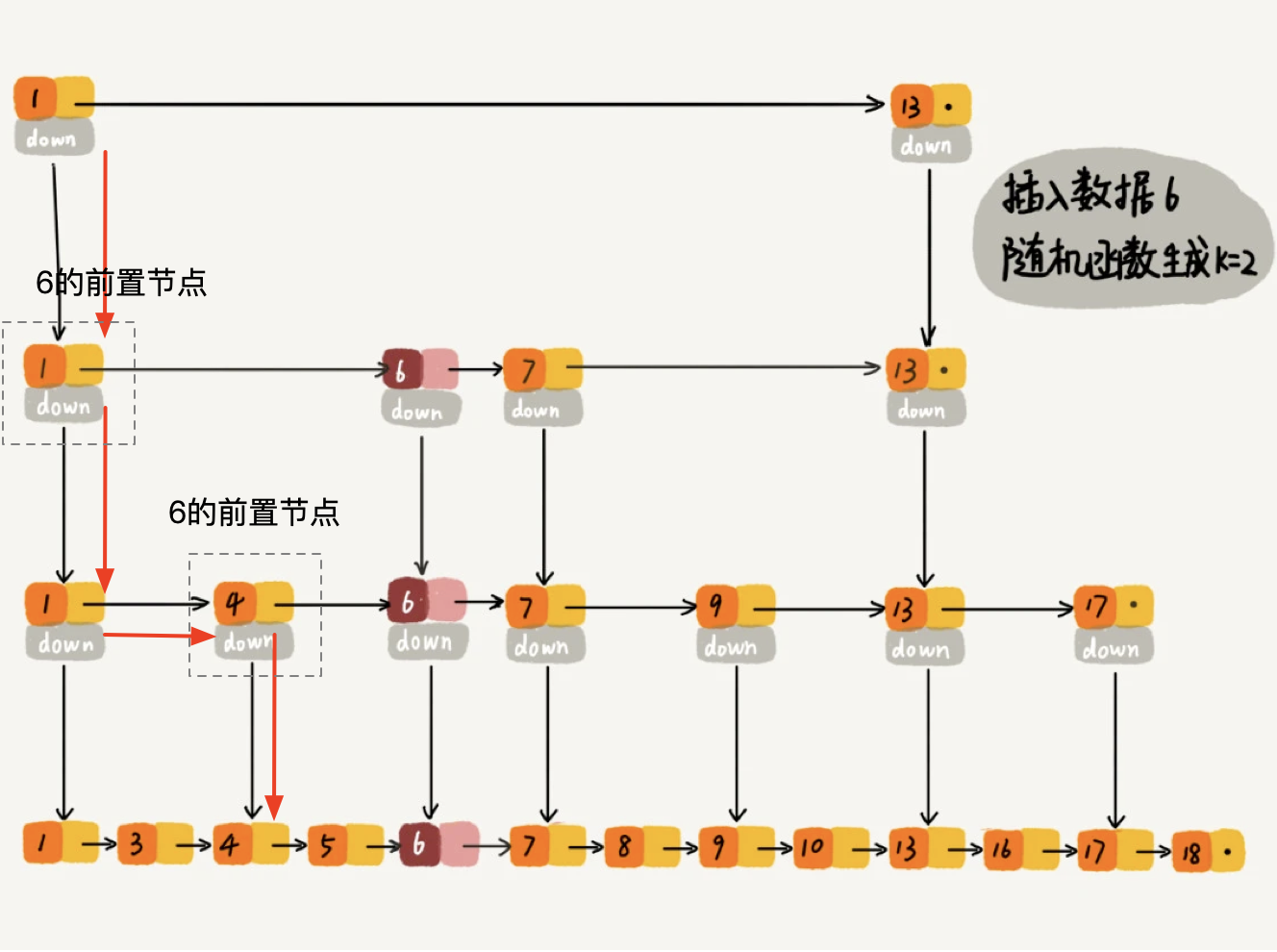
通过随机函数生成此value插入的高度为2.
同查找一样的遍历流程, 找到比6大的那个位置. 在此过程中, 每一次向下迭代需要记录转折点如图中的1和4.这两个节点会作为6的前置节点
将新value的next指向原来前置节点的next, 将原来前置节点的next指向新的节点
同时新生成的level是可能高于原始高度的
删除
删除相比插入更简单, 在遍历每一层的时候不需要单独去记录前置节点了. 虽然以下实现是记录了前置节点后统一更新的, 但我感觉是没有必要的, delete可以改成 https://github.com/wangzheng0822/algo/blob/master/java/17_skiplist/SkipList.java
public void delete2(int value) {
Node p = head;
// 找到前置节点
for (int i = levelCount - 1; i >= 0; i--) {
while (p.forwards[i] != null && p.forwards[i].value < value) {
p = p.forwards[i];
}
if (p.forwards[i] != null && p.forwards[i].value == value) {
p.forwards[i] = p.forwards[i].forwards[i];
}
}
// head 指向为空的节点都剔除.
while (levelCount > 1 && head.forwards[levelCount] == null) {
levelCount--;
}
}工业实现
redis的sorted set hbase中内存的有序集合 java ConcurrentSkipListSet ConcurrentSkipListMap
参考
<数据结构与算法分析 Java描述> 10.4.2
<HBase原理与实践> 2.1 跳跃表
https://zhuanlan.zhihu.com/p/33674267
SkipList原理与实现的更多相关文章
- 跳表(SkipList)原理篇
1.什么是跳表? 维基百科:跳表是一种数据结构.它使得包含n个元素的有序序列的查找和插入操作的平均时间复杂度都是 O(logn),优于数组的 O(n)复杂度.快速的查询效果是通过维护一个多层次的链表实 ...
- 浅析SkipList跳跃表原理及代码实现
本文将总结一种数据结构:跳跃表.前半部分跳跃表性质和操作的介绍直接摘自<让算法的效率跳起来--浅谈“跳跃表”的相关操作及其应用>上海市华东师范大学第二附属中学 魏冉.之后将附上跳跃表的源代 ...
- 【转】浅析SkipList跳跃表原理及代码实现
SkipList在Leveldb以及lucence中都广为使用,是比较高效的数据结构.由于它的代码以及原理实现的简单性,更为人们所接受.首先看看SkipList的定义,为什么叫跳跃表? "S ...
- 算法: skiplist 跳跃表代码实现和原理
SkipList在leveldb以及lucence中都广为使用,是比较高效的数据结构.由于它的代码以及原理实现的简单性,更为人们所接受. 所有操作均从上向下逐层查找,越上层一次next操作跨度越大.其 ...
- 跳跃表 SkipList【数据结构】原理及实现
为什么选择跳表 目前经常使用的平衡数据结构有:B树,红黑树,AVL树,Splay Tree, Treep等. 想象一下,给你一张草稿纸,一只笔,一个编辑器,你能立即实现一颗红黑树,或者AVL树出来吗? ...
- skiplist(跳表)的原理及JAVA实现
前记 最近在看Redis,之间就尝试用sortedSet用在实现排行榜的项目,那么sortedSet底层是什么结构呢? "Redis sorted set的内部使用HashMap和跳跃表(S ...
- JAVA SkipList 跳表 的原理和使用例子
跳跃表是一种随机化数据结构,基于并联的链表,其效率可比拟于二叉查找树(对于大多数操作需要O(log n)平均时间),并且对并发算法友好. 关于跳跃表的具体介绍可以参考MIT的公开课:跳跃表 跳跃表的应 ...
- skip-list(跳表)原理及C++代码实现
跳表是一个很有意思的数据结构,它实现简单,但是性能又可以和平衡二叉搜索树差不多. 据MIT公开课上教授的讲解,它的想法和纽约地铁有异曲同工之妙,简而言之就是不断地增加“快线”,从而降低时间复杂度. 当 ...
- 跳跃表Skip List的原理和实现
>>二分查找和AVL树查找 二分查找要求元素可以随机访问,所以决定了需要把元素存储在连续内存.这样查找确实很快,但是插入和删除元素的时候,为了保证元素的有序性,就需要大量的移动元素了.如果 ...
- skiplist 跳表(2)-----细心学习
快速了解skiplist请看:skiplist 跳表(1) http://blog.sina.com.cn/s/blog_693f08470101n2lv.html 本周我要介绍的数据结构,是我非常非 ...
随机推荐
- Indent----- IndentationError: unexpected indent
Unexpected indent 错误 注意,Python 中实现对代码的缩进,可以使用空格或者 Tab 键实现.但无论是手动敲空格,还是使用 Tab 键,通常情况下都是采用 4 个空格长度作为一个 ...
- B/S结构系统的会话机制(session)
B/S结构系统的会话机制(session) 目录 B/S结构系统的会话机制(session) 每博一文案 1. session 会话机制的概述 2. 什么是 session 的会话 3. sessio ...
- JUC并发编程原理精讲(源码分析)
1. JUC前言知识 JUC即 java.util.concurrent 涉及三个包: java.util.concurrent java.util.concurrent.atomic java.ut ...
- Prism Sample 12-UsingCompositeCommands
本例中,主页是一个按钮,绑定了一个复合命令,然后下面一个TabControl <Grid> <Grid.RowDefinitions> <RowDefinition He ...
- dos命令、变量、字符编码、注释、用户输入
一.dos命令 1.dos命令 c: 切换盘符 cd c:\pthon 切换路径 dir 查看目录下的文件 cd .. 返回到上一层目录 cd ../.. 返回到上一层的上一层目录 二.环境变量的配置 ...
- 2021-05-08:给定两个非负数组x和hp,长度都是N,再给定一个正数range。x有序,x[i]表示i号怪兽在x轴上的位置;hp[i]表示i号怪兽的血量 。range表示法师如果站在x位置,用A
2021-05-08:给定两个非负数组x和hp,长度都是N,再给定一个正数range.x有序,x[i]表示i号怪兽在x轴上的位置:hp[i]表示i号怪兽的血量 .range表示法师如果站在x位置,用A ...
- 2021-10-01:矩阵置零。给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。进阶:一个直观的解决方案是使用 O(mn) 的额外空间
2021-10-01:矩阵置零.给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 .请使用 原地 算法.进阶:一个直观的解决方案是使用 O(mn) 的额外空间, ...
- 【设计模式】使用 go 语言实现简单工厂模式
最近在看<大话设计模式>,这本书通过对话形式讲解设计模式的使用场景,有兴趣的可以去看一下. 第一篇讲的是简单工厂模式,要求输入两个数和运算符号,得到运行结果. 这个需求不难,难就难在类要怎 ...
- 【rabbitMQ】-延迟队列-模拟控制智能家居的操作指令
这个需求为控制智能家居工作,把控制智能家居的操作指令发到队列中,比如:扫地机.洗衣机到指定时间工作 一.什么是延迟队列? 延迟队列存储的对象是对应的延迟消息,所谓"延迟消息" ...
- 代码随想录算法训练营Day48 动态规划
代码随想录算法训练营 代码随想录算法训练营Day48 动态规划|198.打家劫舍 213.打家劫舍II 337.打家劫舍III 198.打家劫舍 题目链接:198.打家劫舍 你是一个专业的小偷,计划偷 ...