【赵渝强老师】Flink的Watermark机制(基于Flink 1.11.0实现)

在使用eventTime的时候如何处理乱序数据?我们知道,流处理从事件产生,到流经source,再到operator,中间是有一个过程和时间的。虽然大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络延迟等原因,导致乱序的产生,特别是使用kafka的话,多个分区的数据无法保证有序。所以在进行window计算的时候,我们又不能无限期的等下去,必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了。这个特别的机制,就是watermark。Watermark是用于处理乱序事件的,用于衡量Event Time进展的机制。watermark可以翻译为水位线。
一、Watermark的核心原理
Watermark的核心本质可以理解成一个延迟触发机制。
在 Flink 的窗口处理过程中,如果确定全部数据到达,就可以对 Window 的所有数据做 窗口计算操作(如汇总、分组等),如果数据没有全部到达,则继续等待该窗口中的数据全 部到达才开始处理。这种情况下就需要用到水位线(WaterMarks)机制,它能够衡量数据处 理进度(表达数据到达的完整性),保证事件数据(全部)到达 Flink 系统,或者在乱序及 延迟到达时,也能够像预期一样计算出正确并且连续的结果。当任何 Event 进入到 Flink 系统时,会根据当前最大事件时间产生 Watermarks 时间戳。
那么 Flink 是怎么计算 Watermak 的值呢?
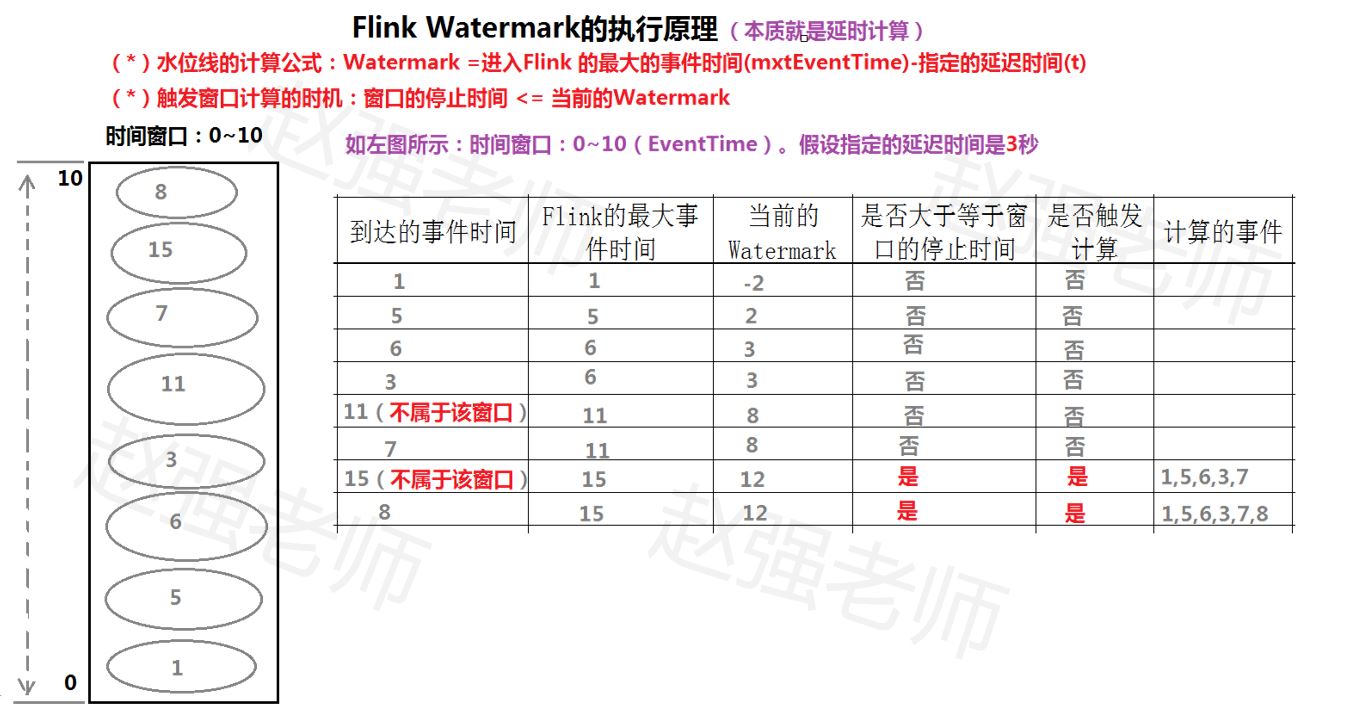
Watermark =进入Flink 的最大的事件时间(mxtEventTime)-指定的延迟时间(t)
那么有 Watermark 的 Window 是怎么触发窗口函数的呢?
如果有窗口的停止时间等于或者小于 maxEventTime - t(当时的warkmark),那么这个窗口被触发执行。
其核心处理流程如下图所示。
二、Watermark的三种使用情况
1、本来有序的Stream中的 Watermark
如果数据元素的事件时间是有序的,Watermark 时间戳会随着数据元素的事件时间按顺 序生成,此时水位线的变化和事件时间保持一直(因为既然是有序的时间,就不需要设置延迟了,那么t就是 0。所以 watermark=maxtime-0 = maxtime),也就是理想状态下的水位 线。当 Watermark 时间大于 Windows 结束时间就会触发对 Windows 的数据计算,以此类推, 下一个 Window 也是一样。这种情况其实是乱序数据的一种特殊情况。
2、乱序事件中的Watermark
现实情况下数据元素往往并不是按照其产生顺序接入到 Flink 系统中进行处理,而频繁 出现乱序或迟到的情况,这种情况就需要使用 Watermarks 来应对。比如下图,设置延迟时间t为2。
3、并行数据流中的Watermark
在多并行度的情况下,Watermark 会有一个对齐机制,这个对齐机制会取所有 Channel 中最小的 Watermark。
三、设置Watermark的核心代码
1、首先,正确设置事件处理的时间语义,一般都是采用Event Time。
sEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
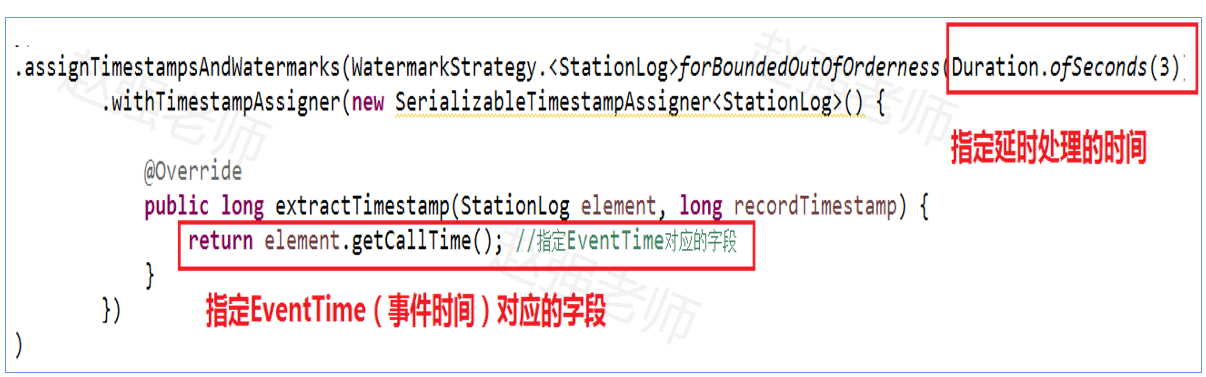
2、其次,指定生成Watermark的机制,包括:延时处理的时间和EventTime对应的字段。如下:
注意:不管是数据是否有序,都可以使用上面的代码。有序的数据只是无序数据的一种特殊情况。
四、Watermark编程案例
测试数据:基站的手机通话数据,如下:

需求:按基站,每5秒统计通话时间最长的记录。
- StationLog用于封装基站数据
package watermark; //station1,18688822219,18684812319,10,1595158485855
public class StationLog {
private String stationID; //基站ID
private String from; //呼叫放
private String to; //被叫方
private long duration; //通话的持续时间
private long callTime; //通话的呼叫时间
public StationLog(String stationID, String from,
String to, long duration,
long callTime) {
this.stationID = stationID;
this.from = from;
this.to = to;
this.duration = duration;
this.callTime = callTime;
}
public String getStationID() {
return stationID;
}
public void setStationID(String stationID) {
this.stationID = stationID;
}
public long getCallTime() {
return callTime;
}
public void setCallTime(long callTime) {
this.callTime = callTime;
}
public String getFrom() {
return from;
}
public void setFrom(String from) {
this.from = from;
} public String getTo() {
return to;
}
public void setTo(String to) {
this.to = to;
}
public long getDuration() {
return duration;
}
public void setDuration(long duration) {
this.duration = duration;
}
}
- 代码实现:WaterMarkDemo用于完成计算(注意:为了方便咱们测试设置任务的并行度为1)
package watermark; import java.time.Duration;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector; //每隔五秒,将过去是10秒内,通话时间最长的通话日志输出。
public class WaterMarkDemo {
public static void main(String[] args) throws Exception {
//得到Flink流式处理的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.setParallelism(1);
//设置周期性的产生水位线的时间间隔。当数据流很大的时候,如果每个事件都产生水位线,会影响性能。
env.getConfig().setAutoWatermarkInterval(100);//默认100毫秒 //得到输入流
DataStreamSource<String> stream = env.socketTextStream("bigdata111", 1234);
stream.flatMap(new FlatMapFunction<String, StationLog>() { public void flatMap(String data, Collector<StationLog> output) throws Exception {
String[] words = data.split(",");
// 基站ID from to 通话时长 callTime
output.collect(new StationLog(words[0], words[1],words[2], Long.parseLong(words[3]), Long.parseLong(words[4])));
}
}).filter(new FilterFunction<StationLog>() { @Override
public boolean filter(StationLog value) throws Exception {
return value.getDuration() > 0?true:false;
}
}).assignTimestampsAndWatermarks(WatermarkStrategy.<StationLog>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner(new SerializableTimestampAssigner<StationLog>() {
@Override
public long extractTimestamp(StationLog element, long recordTimestamp) {
return element.getCallTime(); //指定EventTime对应的字段
}
})
).keyBy(new KeySelector<StationLog, String>(){
@Override
public String getKey(StationLog value) throws Exception {
return value.getStationID(); //按照基站分组
}}
).timeWindow(Time.seconds(5)) //设置时间窗口
.reduce(new MyReduceFunction(),new MyProcessWindows()).print(); env.execute();
}
}
//用于如何处理窗口中的数据,即:找到窗口内通话时间最长的记录。
class MyReduceFunction implements ReduceFunction<StationLog> {
@Override
public StationLog reduce(StationLog value1, StationLog value2) throws Exception {
// 找到通话时间最长的通话记录
return value1.getDuration() >= value2.getDuration() ? value1 : value2;
}
}
//窗口处理完成后,输出的结果是什么
class MyProcessWindows extends ProcessWindowFunction<StationLog, String, String, TimeWindow> {
@Override
public void process(String key, ProcessWindowFunction<StationLog, String, String, TimeWindow>.Context context,
Iterable<StationLog> elements, Collector<String> out) throws Exception {
StationLog maxLog = elements.iterator().next(); StringBuffer sb = new StringBuffer();
sb.append("窗口范围是:").append(context.window().getStart()).append("----").append(context.window().getEnd()).append("\n");;
sb.append("基站ID:").append(maxLog.getStationID()).append("\t")
.append("呼叫时间:").append(maxLog.getCallTime()).append("\t")
.append("主叫号码:").append(maxLog.getFrom()).append("\t")
.append("被叫号码:") .append(maxLog.getTo()).append("\t")
.append("通话时长:").append(maxLog.getDuration()).append("\n");
out.collect(sb.toString());
}
}
【赵渝强老师】Flink的Watermark机制(基于Flink 1.11.0实现)的更多相关文章
- [白话解析] Flink的Watermark机制
[白话解析] Flink的Watermark机制 0x00 摘要 对于Flink来说,Watermark是个很难绕过去的概念.本文将从整体的思路上来说,运用感性直觉的思考来帮大家梳理Watermark ...
- flink的watermark机制你学会了吗?
大家好,今天我们来聊一聊flink的Watermark机制. 这也是flink系列的的第一篇文章,如果对flink.大数据感兴趣的小伙伴,记得点个关注呀. 背景 flink作为先进的流水计算引擎, ...
- Flink的时间类型和watermark机制
一FlinkTime类型 有3类时间,分别是数据本身的产生时间.进入Flink系统的时间和被处理的时间,在Flink系统中的数据可以有三种时间属性: Event Time 是每条数据在其生产设备上发生 ...
- 201871010136—赵艳强《面向对象程序设计(java)》第十三周学习总结
201871010136—赵艳强<面向对象程序设计(java)>第十三周学习总结 博文正文开头格式:(2分) 项目 内容 <面向对象程序设计(java)> https:// ...
- [源码解析] 从TimeoutException看Flink的心跳机制
[源码解析] 从TimeoutException看Flink的心跳机制 目录 [源码解析] 从TimeoutException看Flink的心跳机制 0x00 摘要 0x01 缘由 0x02 背景概念 ...
- Flink(八)【Flink的窗口机制】
目录 Flink的窗口机制 1.窗口概述 2.窗口分类 基于时间的窗口 滚动窗口(Tumbling Windows) 滑动窗口(Sliding Windows) 会话窗口(Session Window ...
- 腾讯新闻基于 Flink PipeLine 模式的实践
摘要 :随着社会消费模式以及经济形态的发展变化,将催生新的商业模式.腾讯新闻作为一款集游戏.教育.电商等一体的新闻资讯平台.服务亿万用户,业务应用多.数据量大.加之业务增长.场景更加复杂,业务对实时 ...
- Flink资料(1)-- Flink基础概念(Basic Concept)
Flink基础概念 本文描述Flink的基础概念,翻译自https://ci.apache.org/projects/flink/flink-docs-release-1.0/concepts/con ...
- Flink学习(二)Flink中的时间
摘自Apache Flink官网 最早的streaming 架构是storm的lambda架构 分为三个layer batch layer serving layer speed layer 一.在s ...
- kafka传数据到Flink存储到mysql之Flink使用SQL语句聚合数据流(设置时间窗口,EventTime)
网上没什么资料,就分享下:) 简单模式:kafka传数据到Flink存储到mysql 可以参考网站: 利用Flink stream从kafka中写数据到mysql maven依赖情况: <pro ...
随机推荐
- Java 线程池之Jetty 线程池学习总结
Java 线程池之Jetty 线程池学习总结 前提 Jetty 11.0.x 为什么是Jetty? Java提供4中创建线程池的快捷方式 Executors.newFixedThreadPool(); ...
- ThinkPHP一对一关联模型的运用(ORM)
一.序言 最近在写ThinkPHP关联模型的时候一些用法总忘,我就想通过写博客的方式复习和整理下一些用法. 具体版本: topthink/framework:6.1.4 topthink/think- ...
- mybatis源码配置文件解析之五:解析mappers标签(解析class属性)
在上篇文章中分析了mybatis解析mapper标签中的resource.url属性的过程,<mybatis源码配置文件解析之五:解析mappers标签(解析XML映射文件)>.通过分析可 ...
- 【Tycoon City New York】城市梦想家: 纽约 作弊键说明
这游戏是自带快捷键作弊功能的 [Ctrl] + [Alt] + A 加10,000人口 [Ctrl] + [Alt] + C 加$1,000,000资金 [Ctrl] + [Alt] + B 加100 ...
- 【Vue】代理服务配置
Springboot 后台接口地址 基础路径配置: server: port: 8080 servlet: context-path: /demo 完整路径: localhost:8080/demo ...
- Human-centric Computing and Information Sciences期刊基本信息
letpub 地址: https://www.letpub.com.cn/index.php?page=journalapp&view=detail&journalid=10450&a ...
- 进程的CPU绑定是否有意义 —— 进程的 CPU 亲和性
好多年前就学习过 进程的 CPU 亲和性这个概念,说直白些就是CPU的进程绑定,也就是指定某个进程绑定到某个CPU核心上,以此提高进程切换时缓存的命中率,加快进程的运算速度. 虽然在编程的时候中会遇到 ...
- OpenALMusicPlayer.cpp:164:22: error: invalid conversion from ‘char’ to ‘const char*’ [-fpermissive]
编译时报错: OpenALMusicPlayer.cpp:164:22: error: invalid conversion from 'char' to 'const char*' [-fpermi ...
- /usr/bin/ld cannot find -lGL
安装mujoco报错: /usr/bin/ld cannot find -lGL 解决方法: sudo apt install libgl1-mesa-dev
- DataOps 新趋势:联通数科如何利用 DolphinScheduler 实现数据一体化管理
引言 在DataOps(数据运营)的推动下,越来越多的企业开始关注数据研发和运营的一体化建设.DataOps通过自动化和流程优化,帮助企业实现数据的高效流转和管理. 当前,Apache Dolphin ...