Llama2-Chinese项目:4-量化模型
一.量化模型调用方式
下面是一个调用FlagAlpha/Llama2-Chinese-13b-Chat[1]的4bit压缩版本FlagAlpha/Llama2-Chinese-13b-Chat-4bit[2]的例子:
from transformers import AutoTokenizer
from auto_gptq import AutoGPTQForCausalLM
model = AutoGPTQForCausalLM.from_quantized('FlagAlpha/Llama2-Chinese-13b-Chat-4bit', device="cuda:0")
tokenizer = AutoTokenizer.from_pretrained('FlagAlpha/Llama2-Chinese-13b-Chat-4bit',use_fast=False)
input_ids = tokenizer(['<s>Human: 怎么登上火星\n</s><s>Assistant: '], return_tensors="pt",add_special_tokens=False).input_ids.to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
这里面有个问题就是由Llama2-Chinese-13b-Chat如何得到Llama2-Chinese-13b-Chat-4bit?这涉及另外一个AutoGPTQ库(一个基于GPTQ算法,简单易用且拥有用户友好型接口的大语言模型量化工具包)[3]。先梳理下思路,由于meta-llama/Llama-2-13b-chat-hf对中文支持较差,所以采用中文指令集在此基础上进行LoRA微调得到了FlagAlpha/Llama2-Chinese-13b-Chat-LoRA,而FlagAlpha/Llama2-Chinese-13b-Chat=FlagAlpha/Llama2-Chinese-13b-Chat-LoRA+meta-llama/Llama-2-13b-chat-hf,即将两者参数合并后的版本。FlagAlpha/Llama2-Chinese-13b-Chat-4bit就是对FlagAlpha/Llama2-Chinese-13b-Chat进行4bit量化后的版本。总结起来就是如何合并,如何量化这2个问题。官方提供的一些合并参数后的模型[4],如下所示:
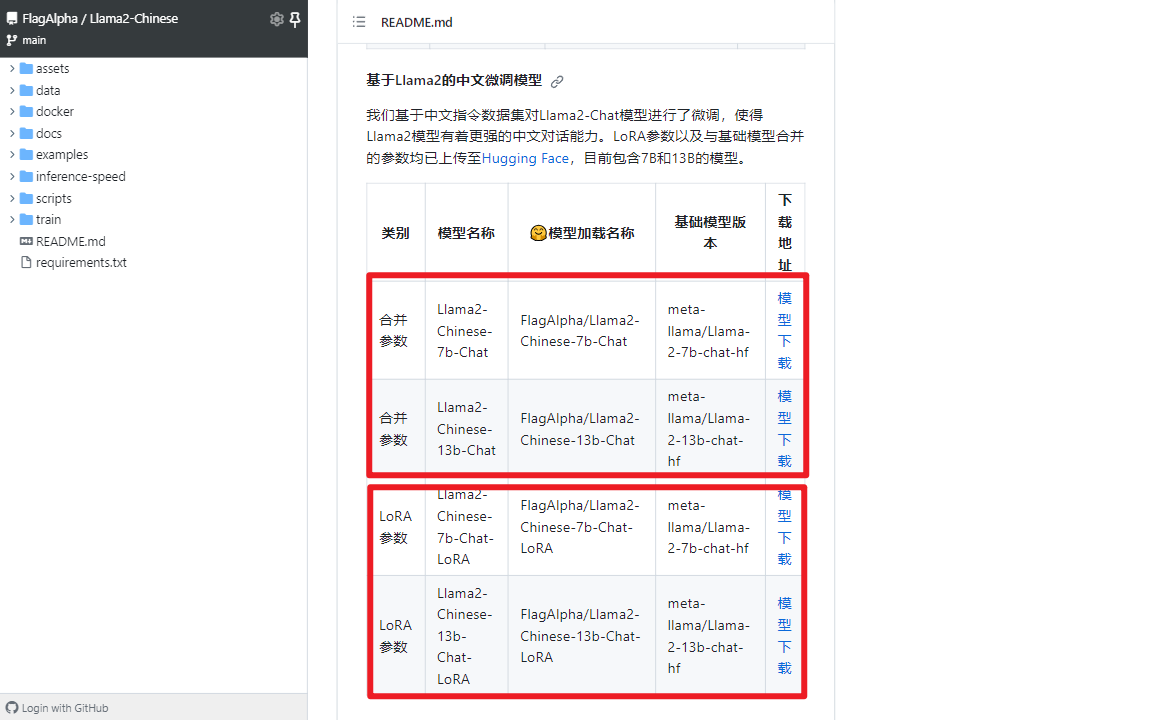
二.如何合并LoRA Model和Base Model
网上合并LoRA参数和原始模型的脚本很多,参考文献[6]亲测可用。合并后的模型格式包括pth和huggingface两种。如下所示:
1.LoRA Model文件列表
对于LLama2-7B-hf进行LoRA微调生成文件如下所示:
adapter_config.json
adapter_model.bin
optimizer.pt
README.md
rng_state.pth
scheduler.pt
special_tokens_map.json
tokenizer.json
tokenizer.model
tokenizer_config.json
trainer_state.json
training_args.bin
2.Base Model文件列表
LLama2-7B-hf文件列表,如下所示:
config.json
generation_config.json
gitattributes.txt
LICENSE.txt
model-00001-of-00002.safetensors
model-00002-of-00002.safetensors
model.safetensors.index.json
pytorch_model-00001-of-00002.bin
pytorch_model-00002-of-00002.bin
pytorch_model.bin.index.json
README.md
Responsible-Use-Guide.pdf
special_tokens_map.json
tokenizer.json
tokenizer.model
tokenizer_config.json
USE_POLICY.md
3.合并后huggingface文件列表
合并LoRA Model和Base Model后,生成huggingface格式文件列表,如下所示:
config.json
generation_config.json
pytorch_model-00001-of-00007.bin
pytorch_model-00002-of-00007.bin
pytorch_model-00003-of-00007.bin
pytorch_model-00004-of-00007.bin
pytorch_model-00005-of-00007.bin
pytorch_model-00006-of-00007.bin
pytorch_model-00007-of-00007.bin
pytorch_model.bin.index.json
special_tokens_map.json
tokenizer.model
tokenizer_config.json
4.合并后pth文件列表
合并LoRA Model和Base Model后,生成pth格式文件列表,如下所示:
consolidated.00.pth
params.json
special_tokens_map.json
tokenizer.model
tokenizer_config.json
5.合并脚本[6]思路
以合并后生成huggingface模型格式为例,介绍合并脚本的思路,如下所示:
# 步骤1:加载base model
base_model = LlamaForCausalLM.from_pretrained(
base_model_path, # 基础模型路径
load_in_8bit=False, # 加载8位
torch_dtype=torch.float16, # float16
device_map={"": "cpu"}, # cpu
)
# 步骤2:遍历LoRA模型
for lora_index, lora_model_path in enumerate(lora_model_paths):
# 步骤3:根据base model和lora model来初始化PEFT模型
lora_model = PeftModel.from_pretrained(
base_model, # 基础模型
lora_model_path, # LoRA模型路径
device_map={"": "cpu"}, # cpu
torch_dtype=torch.float16, # float16
)
# 步骤4:将lora model和base model合并为一个独立的model
base_model = lora_model.merge_and_unload()
......
# 步骤5:保存tokenizer
tokenizer.save_pretrained(output_dir)
# 步骤6:保存合并后的独立model
LlamaForCausalLM.save_pretrained(base_model, output_dir, save_function=torch.save, max_shard_size="2GB")
合并LoRA Model和Base Model过程中输出日志可参考huggingface[7]和pth[8]。
三.如何量化4bit模型
如果得到了一个训练好的模型,比如LLama2-7B,如何得到LLama2-7B-4bit呢?因为模型参数越来越多,多参数模型的量化还是会比少参数模型的非量化效果要好。量化的方案非常的多[9][12],比如AutoGPTQ、GPTQ-for-LLaMa、exllama、llama.cpp等。下面重点介绍下AutoGPTQ的基础实践过程[10],AutoGPTQ进阶教程参考文献[11]。
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig # 量化配置
from transformers import AutoTokenizer
# 第1部分:量化一个预训练模型
pretrained_model_name = r"L:/20230713_HuggingFaceModel/20230903_Llama2/Llama-2-7b-hf" # 预训练模型路径
quantize_config = BaseQuantizeConfig(bits=4, group_size=128) # 量化配置,bits表示量化后的位数,group_size表示分组大小
model = AutoGPTQForCausalLM.from_pretrained(pretrained_model_name, quantize_config) # 加载预训练模型
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name) # 加载tokenizer
examples = [ # 量化样本
tokenizer(
"auto-gptq is an easy-to-use model quantization library with user-friendly apis, based on GPTQ algorithm."
)
]
# 翻译:准备examples(一个只有两个键'input_ids'和'attention_mask'的字典列表)来指导量化。这里只使用一个文本来简化代码,但是应该注意,使用的examples越多,量化后的模型就越好(很可能)。
model.quantize(examples) # 执行量化操作,examples提供量化过程所需的示例数据
quantized_model_dir = "./llama2_quantize_AutoGPTQ" # 保存量化后的模型
model.save_quantized(quantized_model_dir) # 保存量化后的模型
# 第2部分:加载量化模型和推理
from transformers import TextGenerationPipeline # 生成文本
device = "cuda:0"
model = AutoGPTQForCausalLM.from_quantized(quantized_model_dir, device=device) # 加载量化模型
pipeline = TextGenerationPipeline(model=model, tokenizer=tokenizer, device=device) # 得到pipeline管道
print(pipeline("auto-gptq is")[0]["generated_text"]) # 生成文本
参考文献:
[1]https://huggingface.co/FlagAlpha/Llama2-Chinese-13b-Chat
[2]https://huggingface.co/FlagAlpha/Llama2-Chinese-13b-Chat-4bit
[3]https://github.com/PanQiWei/AutoGPTQ/blob/main/README_zh.md
[4]https://github.com/FlagAlpha/Llama2-Chinese#基于Llama2的中文微调模型
[5]CPU中合并权重(合并思路仅供参考):https://github.com/yangjianxin1/Firefly/blob/master/script/merge_lora.py
[6]https://github.com/ai408/nlp-engineering/blob/main/20230916_Llama2-Chinese/tools/merge_llama_with_lora.py
[7]https://github.com/ai408/nlp-engineering/blob/main/20230916_Llama2-Chinese/tools/merge_llama_with_lora_log/merge_llama_with_lora_hf_log
[8]https://github.com/ai408/nlp-engineering/blob/main/20230916_Llama2-Chinese/tools/merge_llama_with_lora_log/merge_llama_with_lora_pt_log
[9]LLaMa量化部署:https://zhuanlan.zhihu.com/p/641641929
[10]AutoGPTQ基础教程:https://github.com/PanQiWei/AutoGPTQ/blob/main/docs/tutorial/01-Quick-Start.md
[11]AutoGPTQ进阶教程:https://github.com/PanQiWei/AutoGPTQ/blob/main/docs/tutorial/02-Advanced-Model-Loading-and-Best-Practice.md
[12]Inference Experiments with LLaMA v2 7b:https://github.com/djliden/inference-experiments/blob/main/llama2/README.md
[13]llama2_quantize_AutoGPTQ:https://github.com/ai408/nlp-engineering/blob/main/20230916_Llama2-Chinese/tools/llama2_quantize_AutoGPTQ.py
Llama2-Chinese项目:4-量化模型的更多相关文章
- CNN结构演变总结(二)轻量化模型
CNN结构演变总结(一)经典模型 导言: 上一篇介绍了经典模型中的结构演变,介绍了设计原理,作用,效果等.在本文,将对轻量化模型进行总结分析. 轻量化模型主要围绕减少计算量,减少参数,降低实际运行时间 ...
- 使用F#开发量化模型都缺什么?
量化模型多数是基于统计的,因此,统计运算库应该是必备的.在Matlab.R中包含了大量的统计和概率运算,可以说拿来就用,非常方便,相比之下,F#的资源就很少了,这里给大家提供几个链接,可以解决一部分问 ...
- Atitit 项目管理 提升开发效率的项目流程方法模型 哑铃型 橄榄型 直板型
Atitit 项目管理 提升开发效率的项目流程方法模型 哑铃型 橄榄型 直板型 项目主体三个部分 ui界面,中间层,数据库 按照不同的比重可以分为一下三个模型 哑铃型 橄榄型 直板型 哑铃型 开 ...
- Atitit. 如何判断软件工程师 能力模型 程序员能力模型 项目经理能力模型
Atitit. 如何判断软件工程师 能力模型 程序员能力模型 项目经理能力模型 这里能力模型的标准化是对工具的使用为基本 工具(ide,语言,类库,框架,软件) 第一步 ::可使用api 类库 框架 ...
- 轻量化模型之MobileNet系列
自 2012 年 AlexNet 以来,卷积神经网络在图像分类.目标检测.语义分割等领域获得广泛应用.随着性能要求越来越高,AlexNet 已经无法满足大家的需求,于是乎各路大牛纷纷提出性能更优越的 ...
- 轻量化模型之SqueezeNet
自 2012 年 AlexNet 以来,卷积神经网络在图像分类.目标检测.语义分割等领域获得广泛应用.随着性能要求越来越高,AlexNet 已经无法满足大家的需求,于是乎各路大牛纷纷提出性能更优越的 ...
- 后盾网lavarel视频项目---lavarel使用模型进行增删改查操作
后盾网lavarel视频项目---lavarel使用模型进行增删改查操作 一.总结 一句话总结: 使用模型操作常用方法 查一条:$model=Tag::find($id); 删一条:Tag::dest ...
- 轻量化模型:MobileNet v2
MobileNet v2 论文链接:https://arxiv.org/abs/1801.04381 MobileNet v2是对MobileNet v1的改进,也是一个轻量化模型. 关于Mobile ...
- 轻量化模型训练加速的思考(Pytorch实现)
0. 引子 在训练轻量化模型时,经常发生的情况就是,明明 GPU 很闲,可速度就是上不去,用了多张卡并行也没有太大改善. 如果什么优化都不做,仅仅是使用nn.DataParallel这个模块,那么实测 ...
- 轻量化模型系列--GhostNet:廉价操作生成更多特征
前言 由于内存和计算资源有限,在嵌入式设备上部署卷积神经网络 (CNN) 很困难.特征图中的冗余是那些成功的 CNN 的一个重要特征,但在神经架构设计中很少被研究. 论文提出了一种新颖的 Gh ...
随机推荐
- 9. SpringMVC处理ajax请求
9.1.@RequestBody @RequestBody 可以获取请求体信息,使用@RequestBody 注解标识控制器方法的形参,当前请求的请求体就会为当前注解所标识的形参赋值 <!--此 ...
- Codeforces Round #877 (Div. 2) A-E
A 代码 #include <bits/stdc++.h> using namespace std; using ll = long long; bool solve() { int n; ...
- 基于java+springboot的视频点播网站-在线视频点播系统
该系统是基于java+springboot开发的视频点播系统.是给师妹开发的毕业设计. 演示地址 前台地址: http://video.gitapp.cn 后台地址: http://video.git ...
- 安装mysql5.7.20,和遇到的一些错误及解决方案
下载: mysql-5.7.20是解压版免安装的,mysql-5.7.20下载地址:http://dev.mysql.com/downloads/mysql/ 2.安装 解压在你喜欢的位置 3.配置 ...
- 你真正了解Spring的工作原理吗
Spring 1.1 什么是Spring IOC 和DI ? ① 控制反转(IOC):Spring容器使用了工厂模式为我们创建了所需要的对象,我们使用时不需要自己去创建,直接调用Spring ...
- 王道oj/problem10
地址:http://oj.lgwenda.com/problem/10 思路:首先创建字符串赋初值,其次用gets()输入字符串[fgets()相对于gets()会多识别"\n", ...
- SpringBoot3基础用法
目录 一.背景 二.环境搭建 1.工程结构 2.框架依赖 3.环境配置 三.入门案例 1.测试接口 2.全局异常 3.日志打印 3.1 日志配置 3.2 日志打印 四.打包运行 五.参考源码 技术和工 ...
- windows配置supervisor实现nginx自启
前言 有些老项目的nginx部署在windows server上,而且服务器比较老旧,经常异常重启.鉴于个人并不熟悉windows server,因此配置supervisor自启nginx,实现win ...
- 用 GPT-4 给开源项目 GoPool 重构测试代码 - 每天5分钟玩转 GPT 编程系列(8)
目录 1. 好险,差点被喷 2. 重构测试代码 2.1 引入 Ginkgo 测试框架 2.2 尝试改造旧的测试用例 2.3 重构功能测试代码 3. 总结 1. 好险,差点被喷 早几天发了一篇文章:&l ...
- Hybrid App 技术路径带动性能的提升
说到 Hybrid App(混合应用)大家都不陌生,因为这种开发模式大行其道发展的这些年取代了很多原生和 Web 应用,为什么大家对这种「Native + HTML5」的开发模式额外偏爱呢? 因为一方 ...