Redis系列之——主从复制原理与优化、缓存的使用和优化
@
一 什么是主从复制
机器故障;容量瓶颈;QPS瓶颈
一主一从,一主多从
做读写分离
做数据副本
扩展数据性能
一个maskter可以有多个slave
一个slave只能有一个master
数据流向是单向的,从master到slave
1.1 原理
1. 副本库通过slaveof 127.0.0.1 6379命令,连接主库,并发送SYNC给主库
2. 主库收到SYNC,会立即触发BGSAVE,后台保存RDB,发送给副本库
3. 副本库接收后会应用RDB快照
4. 主库会陆续将中间产生的新的操作,保存并发送给副本库
5. 到此,我们主复制集就正常工作了
6. 再此以后,主库只要发生新的操作,都会以命令传播的形式自动发送给副本库.
7. 所有复制相关信息,从info信息中都可以查到.即使重启任何节点,他的主从关系依然都在.
8. 如果发生主从关系断开时,从库数据没有任何损坏,在下次重连之后,从库发送PSYNC给主库
9. 主库只会将从库缺失部分的数据同步给从库应用,达到快速恢复主从的目的
1.2 主库是否要开启持久化
如果不开有可能,主库重启操作,造成所有主从数据丢失!
1.3 辅助配置(主从数据一致性配置)
min-slaves-to-write 1
min-slaves-max-lag 3
#那么在从服务器的数量少于1个,或者三个从服务器的延迟(lag)值都大于或等于3秒时,主服务器将拒绝执行写命令
二 复制的 配置
2.1 slave 命令
6380是从,6379是主
在6380上执行(去从库配置,配置主库)
slaveof 127.0.0.1 6379 #异步
slaveof no one #取消复制,不会把之前的数据清除
2.2 配置文件
slaveof ip port #配置从节点ip和端口
slave-read-only yes #从节点只读,因为可读可写,数据会乱
'''
mkdir -p redis1/conf redis1/data redis2/conf redis2/data redis3/conf redis3/data
vim redis.conf
daemonize no
pidfile redis.pid
bind 0.0.0.0
protected-mode no
port 6379
timeout 0
logfile redis.log
dbfilename dump.rdb
dir /data
slaveof 10.0.0.101 6379
slave-read-only yes
cp redis.conf /home/redis2/conf/
docker run -p 6379:6379 --name redis_6379 -v /home/redis1/conf/redis.conf:/etc/redis/redis.conf -v /home/redis1/data:/data -d redis redis-server /etc/redis/redis.conf
docker run -p 6378:6379 --name redis_6378 -v /home/redis2/conf/redis.conf:/etc/redis/redis.conf -v /home/redis2/data:/data -d redis redis-server /etc/redis/redis.conf
docker run -p 6377:6379 --name redis_6377 -v /home/redis3/conf/redis.conf:/etc/redis/redis.conf -v /home/redis3/data:/data -d redis redis-server /etc/redis/redis.conf
info replication
'''
四 故障处理
slave故障
master故障
五 复制常见问题
1 读写分离
读流量分摊到从节点
可能遇到问题:复制数据延迟,读到过期数据,从节点故障
2 主从配置不一致
maxmemory不一致:丢失数据
数据结构优化参数:主节点做了优化,从节点没有设置优化,会出现一些问题
3 规避全量复制
第一次全量复制,不可避免:小主节点,低峰(夜间)
节点运行id不匹配:主节点重启(运行id变化)
复制挤压缓冲区不足:增大复制缓冲区大小,rel_backlog_size
4 规避复制风暴
单主节点复制风暴,主节点重启,所有从节点复制
缓存的使用和优化
一 缓存的收益与成本
1.1 受益
1 加速读写
2 降低后端负载:后端服务器通过前端缓存降低负载,业务端使用redis降低后端mysql负载
1.2 成本
1 数据不一致:缓存层和数据层有时间窗口不一致,和更新策略有关
2 代码维护成本:多了一层缓存逻辑
3 运维成本:比如使用了Redis Cluster
1.3 使用场景
1 降低后端负载:对高消耗的sql,join结果集/分组统计的结果做缓存
2 加速请求响应:利用redis优化io响应时间
3 大量写合并为批量写:如计数器先redis累加再批量写入db
二 缓存更新策略
1 LRU/LFU/FIFO算法剔除:例如maxmemory-policy(到了最大内存,对应的应对策略)
LRU -Least Recently Used,没有被使用时间最长的
LFU -Least Frequenty User,一定时间段内使用次数最少的
FIFO -First In First Out
LIRS (Low Inter-reference Recency Set)是一个页替换算法,相比于LRU(Least Recently Used)和很多其他的替换算法,LIRS具有较高的性能。这是通过使用两次访问同一页之间的距离(本距离指中间被访问了多少非重复块)作为一种尺度去动态地将访问页排序,从而去做一个替换的选择
配置文件中设置:
># LRU配置
>maxmemory-policy:volatile-lru
>(1)noeviction: 如果内存使用达到了maxmemory,client还要继续写入数据,那么就直接报错给客户端
>(2)allkeys-lru: 就是我们常说的LRU算法,移除掉最近最少使用的那些keys对应的数据,ps最长用的策略
>(3)volatile-lru: 也是采取LRU算法,但是仅仅针对那些设置了指定存活时间(TTL)的key才会清理掉
>(4)allkeys-random: 随机选择一些key来删除掉
>(5)volatile-random: 随机选择一些设置了TTL的key来删除掉
>(6)volatile-ttl: 移除掉部分keys,选择那些TTL时间比较短的keys
># LFU配置 Redis4.0之后为maxmemory_policy淘汰策略添加了两个LFU模式:
>volatile-lfu:对有过期时间的key采用LFU淘汰算法
>allkeys-lfu:对全部key采用LFU淘汰算法
># 还有2个配置可以调整LFU算法:
>lfu-log-factor 10
>lfu-decay-time 1
># lfu-log-factor可以调整计数器counter的增长速度,lfu-log-factor越大,counter增长的越慢。
># lfu-decay-time是一个以分钟为单位的数值,可以调整counter的减少速度
2 超时剔除:例如expire,设置过期时间
3 主动更新:开发控制生命周期
策略
一致性
维护成本
LRU/LIRS算法剔除
最差
低
超时剔除
较差
低
主动更新
强
高
1 低一致性:最大内存和淘汰策略
2 高一致性:超时剔除和主动更新结合,最大内存和淘汰策略兜底
三 缓存粒度控制
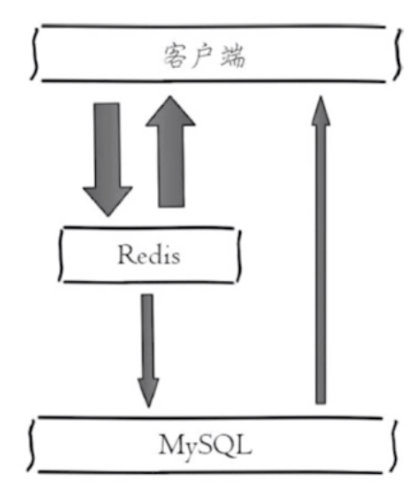
1 从mysql获取用户信息:select * from user where id=100
2 设置用户信息缓存:set user:100 select * from user where id=100
3 缓存粒度:
缓存全部属性
缓存部分重要属性
1 通用性:全量属性更好
2 占用空间:部分属性更好
3 代码维护:表面上全量属性更好
四 缓存穿透,缓存击穿,缓存雪崩
### 缓存穿透
#描述:
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
#解决方案:
1 接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
2 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
3 通过布隆过滤器实现
### 缓存击穿
#描述:
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
#解决方案:
设置热点数据永远不过期。
### 缓存雪崩
#描述:
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是, 缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
# 解决方案:
1 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
2 如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
3 设置热点数据永远不过期。
Redis系列之——主从复制原理与优化、缓存的使用和优化的更多相关文章
- Redis系列(四):Redis持久化和主从复制原理
一.持久化 所谓的持久化就是把内存中的数据写到磁盘中去,防止服务宕机后内存数据丢失.Redis4.0之前提供了两种持久化方式:RDB(默认) 和AOF,Redis4.x之后新增了一种混合持久化(本文所 ...
- redis系列:主从复制
1 简介 这篇文章主要讲述Redis的主从复制功能.会依次从环境搭建.功能测试和原理分析几个方面进行介绍. 2 准备工作 服务器架构图如下 启动主服务器101,使用info replication命令 ...
- Redis系列七 主从复制(Master/Slave)
主从复制(Master/Slave) 1.是什么 也就是我们所说的主从复制,主机数据更新后根据配置和策略,自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主. 2 ...
- redis系列之------主从复制
什么是主从复制 Redis的主从复制机制是指可以让从服务器(slave)能精确复制主服务器(master)的数据,如下图所示: 或者 主从复制的方式和工作原理 工作方式: Redis主从复制主要 ...
- 四、redis系列之主从复制与哨兵机制
1. 绪言 在现实应用环境中,出于数据容量.容灾.性能等因素的考虑,往往不会只使用一台服务器,而是使用集群的方式.Redis 中也有类似的维持一主多从的方式提高 Redis 集群的高可用性的方案,而其 ...
- Redis系列(五)--主从复制
单机环境存在的问题: 1.机器故障,直接凉凉 2.容量瓶颈 3.QPS瓶颈 主从复制 对于可拓展平台来说,复制(replication)是必不可少的.replication可以让其他服务器slave拥 ...
- Redis系列目录
第一章 Redis系列之-redis初识 第二章 Redis系列之-常用命令及API的使用 第三章 Redis系列之-高级用法 第四章 Redis系列之-持久化 第五章 Redis系列之-使用常见问题 ...
- Redis系列(二):Redis高可用集群
一.集群模式 Redis集群是一个由多个主从节点组成的高可用集群,它具有复制.高可用和分片等特性 二.集群部署 1.环境 3台主机分别是: 192.168.160.146 192.168.160.15 ...
- 分布式缓存技术redis系列(四)——redis高级应用(集群搭建、集群分区原理、集群操作)
本文是redis学习系列的第四篇,前面我们学习了redis的数据结构和一些高级特性,点击下面链接可回看 <详细讲解redis数据结构(内存模型)以及常用命令> <redis高级应用( ...
- Redis主从复制原理总结
和Mysql主从复制的原因一样,Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况.为了分担读压力,Redis支持主从复制,Redis的主从结构可以采用一主多从或者级联结构,Redi ...
随机推荐
- Nginx SSL 双向认证,key 生成和配置
一.安装Nginx和OpenSSL yum install nginx openssl -y 二.SSL 服务器 / 客户端双向验证证书的生成 创建一个新的 CA 根证书,在 nginx 安装目录下新 ...
- 逍遥自在学C语言 | 多级指针探秘
前言 多级指针在C语言中是一种特殊的指针类型,它可以指向其他指针的指针. 通过多级指针,我们可以间接地访问或修改存储在内存中的数据. 在本文中,我们将讨论多级指针的概念.使用方法.使用场景以及常见错误 ...
- 信创优选,国产开源,Solon v2.3.6 发布
Solon 是什么开源项目? 一个,Java 新的生态型应用开发框架.它从零开始构建,有自己的标准规范与开放生态(历时五年,已有全球第二级别的生态).与其他框架相比,它解决了两个重要的痛点:启动慢,费 ...
- 《最新出炉》系列初窥篇-Python+Playwright自动化测试-4-playwright等待浅析
1.简介 在介绍selenium的时候,宏哥也介绍过等待,是因为在某些元素出现后,才可以进行操作.有时候我们自己忘记添加等待时间后,查了半天代码确定就是没有问题,奇怪的就是获取不到元素.然后搞了好久, ...
- 面试官:讲讲MySql索引失效的几种情况
索引失效 准备数据: CREATE TABLE `dept` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `deptName` VARCHAR(30) DEFAUL ...
- PlayWright(十二)- PO模式
1.PO模式是什么? PO,即Page Object,直译为页面对象,代表 Web 应用程序的一部分 具体什么意思呢,通俗来讲,一个页面有输入.点击.搜索功能,而且有很多页面,这时候我们就采用每个 ...
- 4.6 x64dbg 内存扫描与查壳实现
LyScript 插件中默认提供了多种内存特征扫描函数,每一种扫描函数用法各不相同,在使用扫描函数时应首先搞清楚不同函数之间的差异,本章内容将分别详细介绍每一种内存扫描函数是如何灵活运用,并实现一种内 ...
- 十分钟学会angular
首先笔者有一定的vue基础,但是遇到了含有angular的应用,因此需要学习angular的应用,在学习过程中将自己的学习步骤给一一记录下来,因此假设读者也是具有html及js的基础,在此基础上可以跟 ...
- 【转载】Linux虚拟化KVM-Qemu分析(二)之ARMv8虚拟化
原文链接: 作者:LoyenWang 出处:https://www.cnblogs.com/LoyenWang/ 公众号:LoyenWang 版权:本文版权归作者和博客园共有 转载:欢迎转载,但未经作 ...
- SEO相关配置 HTML meta标签总结与属性使用介绍
HTML meta标签总结与属性使用介绍 <!-- 声明文档使用的字符编码 --> <meta charset='utf-8'> <!-- 优先使用 IE 最新版本和 C ...