Python爬取微信小程序实战(通用)
背景介绍
最近遇到一个需求,大致就是要获取某个小程序上的数据。心想小程序本质上就是移动端加壳的浏览器,所以想到用Python去获取数据。在网上学习了一下如何实现后,记录一下我的实现过程以及所踩过的小坑。本文关键词:Python,小程序,Charles抓包
目标小程序:
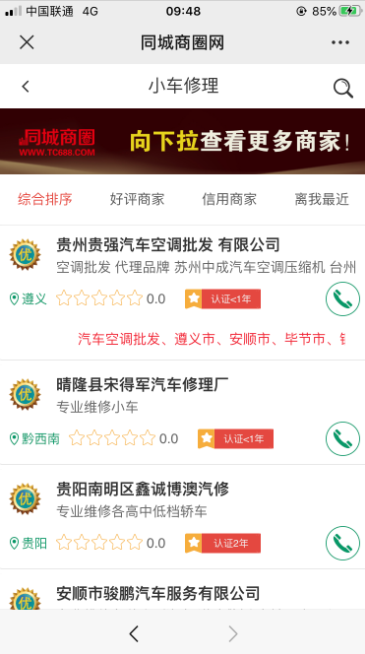
公众号“同城商圈网”左下角“找商家”->汽车维修->小车维修->所有的商家信息,如下图所示:
环境
PC端:Windows 10
移动端:iPhone
软件:Charles
Charles抓包
虽说网上大佬的教程很好很详细,但我想加入几个坑点解释,因此又重新写了个博客,请点此查看Charles配置教程
Charles清空当前获取到的连接,防止干扰(学会使用这个黄色扫把!很有用)
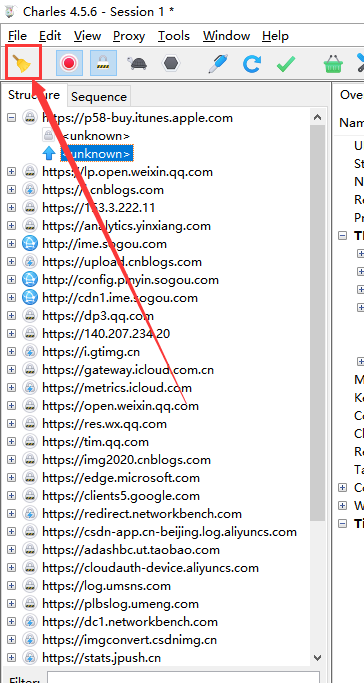
打开微信小程序进入到指定界面,Charles中显示如下
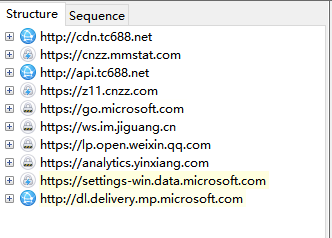
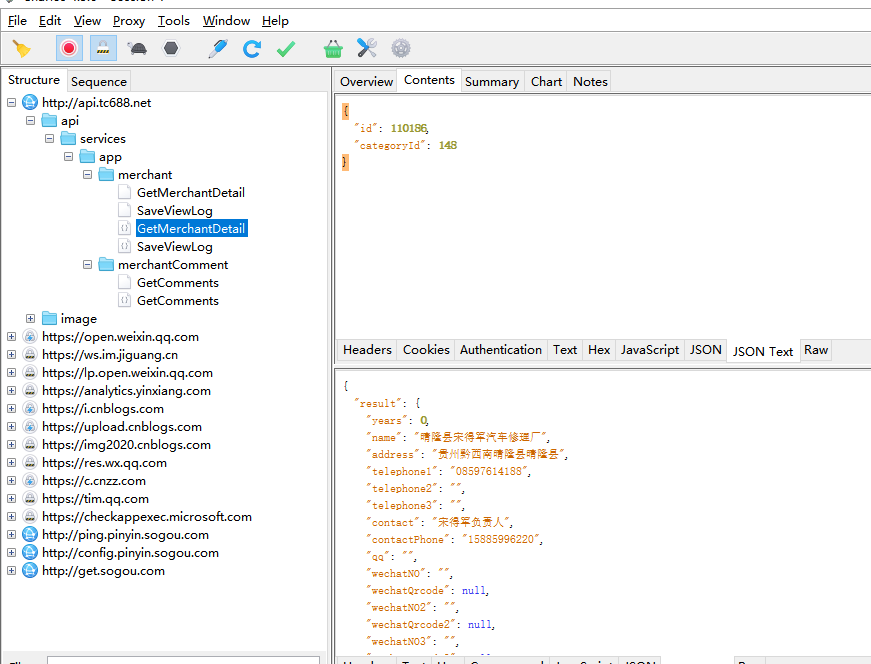
进入到某个具体商家后,最先请求的是这个
于是我们猜测,这个可能就是小程序相关的http请求,点进去我们看一下
此时手机的界面是这样的
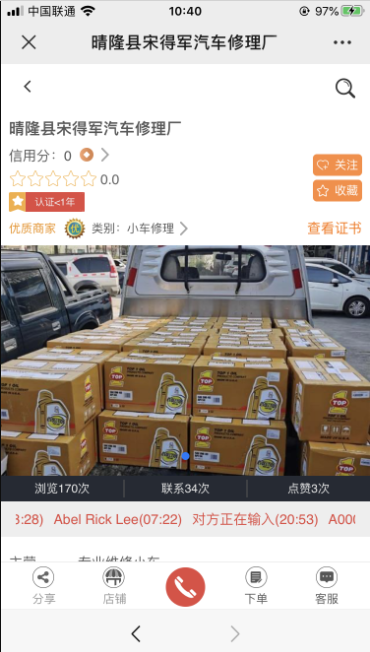
诶,好像就是这个!(其实我也是一个一个试了好久,多试试就会找到啦,当然如果你懂点英文,能看懂左侧的英文就更好了!merchant就是商家的意思~),
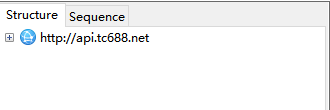
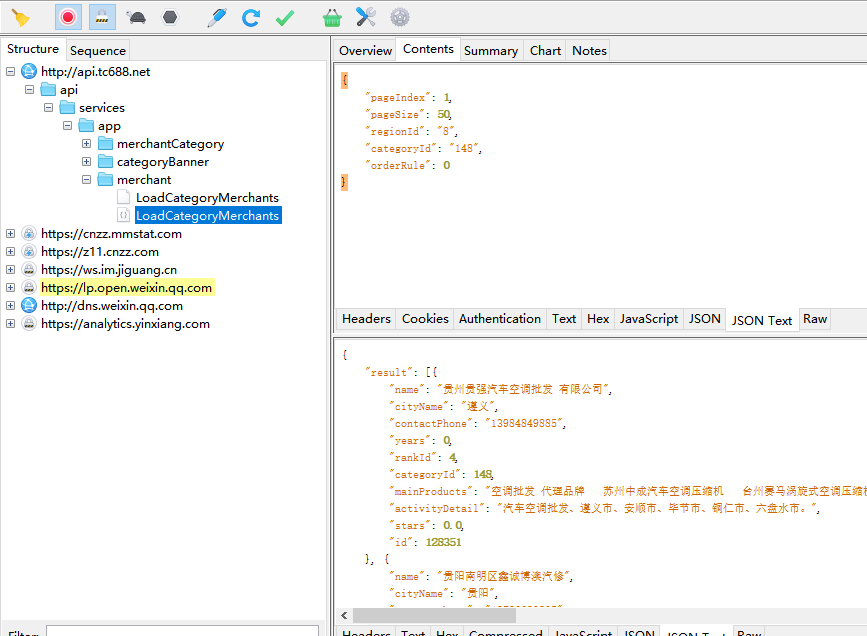
但是我们想要获取所有的商家信息怎么办呢?那就先点击Charles上的黄色小扫把~,再返回到商家列表看看
手机界面如下:
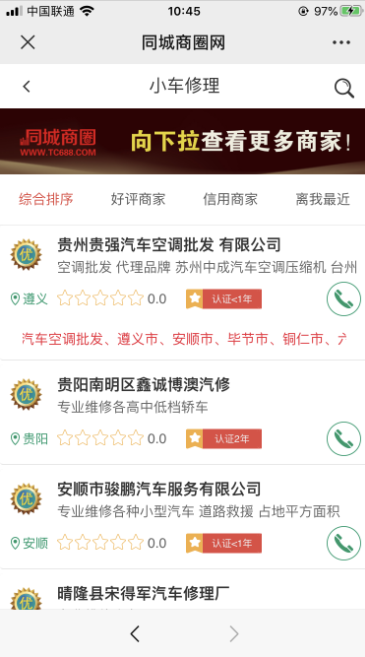
没错就是这个请求了!
分析请求
选中左边发送的请求,右边点击Overview选项卡,查看请求信息,我们不难发现这是个POST请求
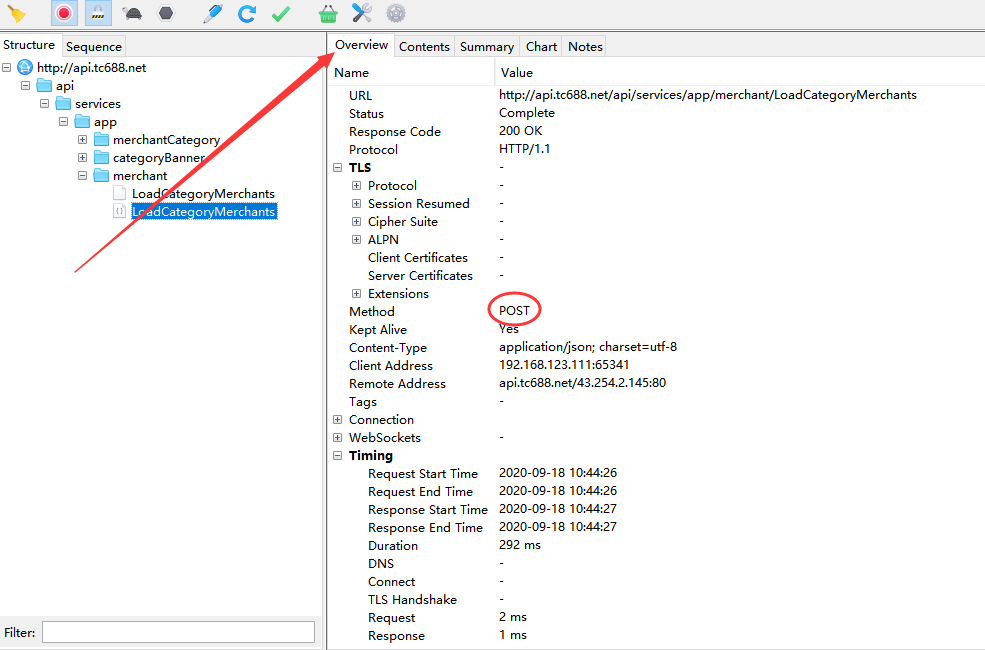
我们知道POST请求提交的是表单,那么表单数据在哪里呢?我们可以在右边界面,鼠标右击,点击Copy Request就能获取表单数据了!
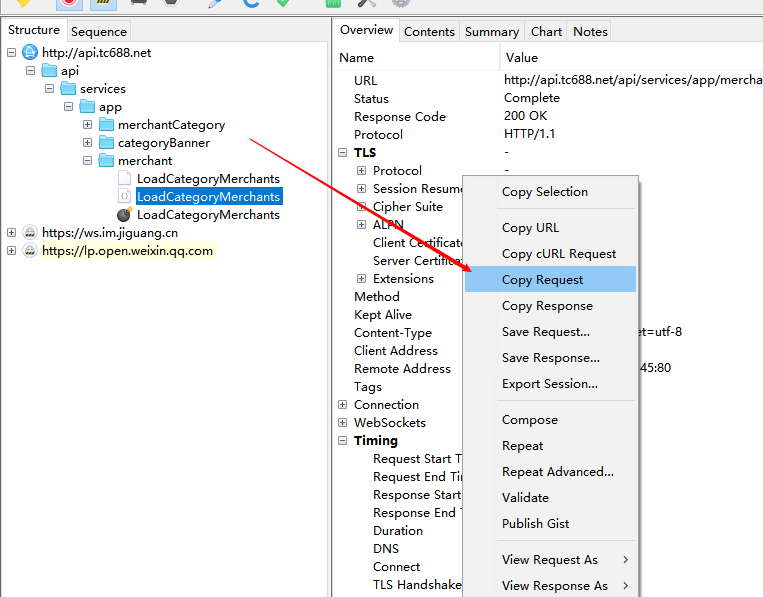
复制到这里看看:
{"pageIndex":1,"pageSize":50,"regionId":"8","categoryId":"148","orderRule":0}
看到这里,我们就能猜出个大概了,pageIndex是页码,pageSize是每页显示数量,regionId是地区编号,categoryId是货品编号,orderRule是排序规则,至此抓包结束,我们成功抓到了目标包!
本节抓包方法理论上适合所有小程序,其他的你们可以自行尝试哦~
编写python代码
这里我们就简单的写个demo
import requests
url = "http://api.tc688.net/api/services/app/merchant/LoadCategoryMerchants"
header = {
'Origin':'http://zazhi.tc688.net',
'Host':'api.tc688.net',
'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_6_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148 MicroMessenger/7.0.14(0x17000e2e) NetType/WIFI Language/zh_CN',
'Referer':'http://zazhi.tc688.net/companylist?id=148',
}
data = {"pageIndex":1,"pageSize":50,"regionId":"8","categoryId":"148","orderRule":0}
r = requests.post(url=url,data=data,headers=header)
print(r.text)
运行结果:

完整项目
有关数据处理以及更换地区的详细代码,请访问我的GitHub:GitHub
Python爬取微信小程序实战(通用)的更多相关文章
- python爬取微信小程序(实战篇)
python爬取微信小程序(实战篇) 本文链接:https://blog.csdn.net/HeyShHeyou/article/details/90452656 展开 一.背景介绍 近期有需求需要抓 ...
- Python爬取微信小程序(Charles)
Python爬取微信小程序(Charles) 本文链接:https://blog.csdn.net/HeyShHeyou/article/details/90045204 一.前言 最近需要获取微信小 ...
- scrapy爬取微信小程序社区教程(crawlspider)
爬取的目标网站是: http://www.wxapp-union.com/portal.php?mod=list&catid=2&page=1 目的是爬取每一个教程的标题,作者,时间和 ...
- scarpy crawl 爬取微信小程序文章(将数据通过异步的方式保存的数据库中)
import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider ...
- scarpy crawl 爬取微信小程序文章
import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider ...
- [转]微信小程序之加载更多(分页加载)实例 —— 微信小程序实战系列(2)
本文转自;http://blog.csdn.net/michael_ouyang/article/details/56846185 loadmore 加载更多(分页加载) 当用户打开一个页面时,假设后 ...
- Python flask构建微信小程序订餐系统
第1章 <Python Flask构建微信小程序订餐系统>课程简介 本章内容会带领大家通览整体架构,功能模块,及学习建议.让大家在一个清晰的开发思路下,进行后续的学习.同时领着大家登陆ht ...
- Python flask构建微信小程序订餐系统✍✍✍
Python flask构建微信小程序订餐系统 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题, ...
- [转]微信小程序之购物车 —— 微信小程序实战商城系列(5)
本文转自:http://blog.csdn.net/michael_ouyang/article/details/70755892 续上一篇的文章:微信小程序之商品属性分类 —— 微信小程序实战商城 ...
- [转]微信小程序之购物数量加减 —— 微信小程序实战商城系列(3)
本文转自:http://blog.csdn.net/michael_ouyang/article/details/70194144 我们在购买宝贝的时候,购物的数量,经常是我们需要使用的,如下所示: ...
随机推荐
- JAVA数据类型以及什么是字节
强类型语言:要求变量的使用要严格符合规定,所有变量都必须先定义才能使用(安全性高) java的数据类型分为两大类 基本类型(primitive type) 引用类型(reference type) / ...
- 使用golang+antlr4构建一个自己的语言解析器(一)
Antlr4 简介 ANTLR(全名:ANother Tool for Language Recognition)是基于LL(*)算法实现的语法解析器生成器(parser generator),用Ja ...
- put、delete、post、get四种传参方式
PUT: this.$http.put('url', { modifyTime:this.sizeForm.modifyTime, mqttRes:this.sizeForm.mqttRes, udp ...
- Nmap基本使用【速查版】
列举远程机器开放的端口 nmap [域名] 列举远程机器开放的端口和服务 nmap --dns-servers 8.8.8.8 [域名] nmap进行探测之前要把域名通过DNS服务器解析为IP地址,我 ...
- CentOS 9 开局配置
CentOS 9 开局配置 CentOS 9 发布有几年了,一直没有尝试使用,CentOS 9 有一些变动. 查看系统基础信息 # 查看系统基础信息 [root@chenby ~]# neofetch ...
- [Java SE]Java SE异常合集
1 概述 2 问题集 Q1 : JAVA应用程序启动时报"A fatal error has been detected by the Java Runtime Environment: E ...
- [Java EE]辨析: POJO(PO / DTO / VO) | BO/DO | DAO
概念不清,会很影响开发中的逻辑性和条理性,进而影响接口设计,代码编写的质量. 网络上大家对这些个概念的探究很多,但终究没有一个统一的说法. 不论哪家解释,我觉得最重要的是: 1)词汇之间的解释统一: ...
- Java设计模式 —— 单例模式
6 单例模式 6.1 单例模式概述 Singleton Patter:确保一个类只有一个实例,并提供一个全局访问点来访问这个唯一实例. 单例模式有3个要点: 该类只能有一个实例 该类必须自行创建这个实 ...
- Spring源码系列:初探底层,手写Spring
前言 在学习Spring框架源码时,记住一句话:源码并不难,只需要给你各种业务场景或者项目经理,你也能实现自己的Spring.虽然你的实现可能无法与开源团队相媲美,但是你肯定可以实现一个0.0.1版本 ...
- 【Vue项目】商品汇前台(二)进度条插件+Vuex模块化仓库+函数的防抖与节流+路由传参
前言 1 nprogress进度条的使用 当请求发出进度条出现并向前走,请求成功后进度条消失.nprogress是一种进度条插件 1.1 nprogress进度条插件安装 npm i --save n ...