UpSetR:多数据集绘图可视化处理利器
说到集合数据可视化,我们第一时间想到的就是韦恩图。在 NGS 相关的研究中,韦恩图用来直观表征不同的集合之间元素重叠关系,是经常在文献中出现的图。
在集合数少的时候韦恩图是很好用的,但是当集合数多比如 5 个以上的时候那就会看的眼花缭乱了。比如下面这张发表在 Nature 上,显示了香蕉基因组与其他五种物种的基因组之间关系的 6 个集合韦恩图。
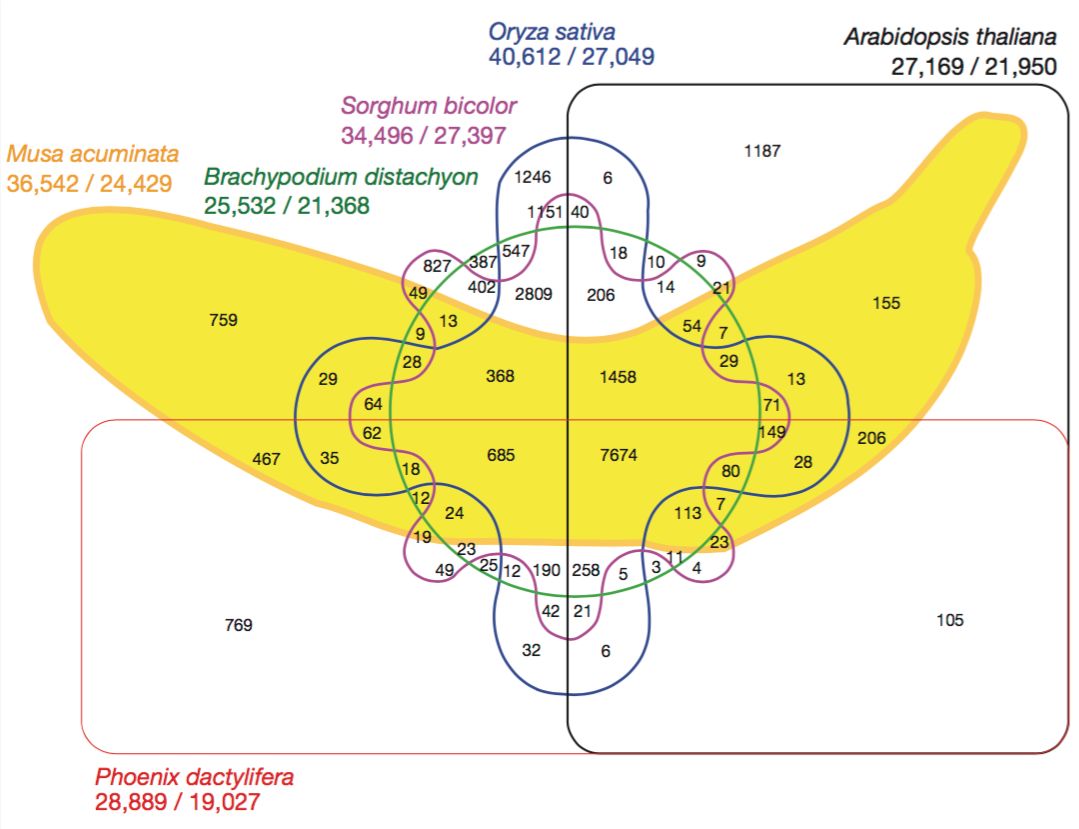
虽然这个图看起来很酷很有趣,但却也让人眼花:我们很难尝试从中提取任何信息;很难去跟踪哪个交叉点涉及哪些集合;也不清楚哪个是可视化中最大的交叉点——要获取这些信息我们必须逐一阅读图中的标签。
为了解决上面的问题,今天介绍一个专门用来做集合可视化,并且不受输入的集合个数限制的 R 包 UpSetR ,该包来源于 UpSet(一种新的用于数据集,以及它们的交集、组合定量分析的可视化技术)。Python 里面也有一个相似的包 py-upset 。此外还有个基于网页版本的 UpSetR shiny app 以及基于 github 的源代码库。
一
图形解读
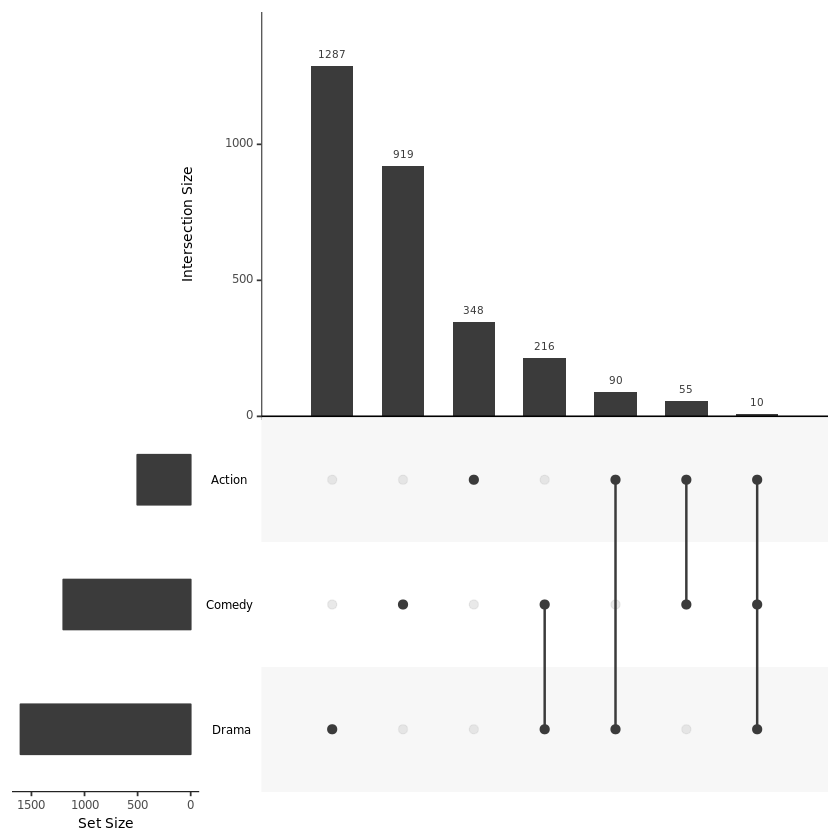
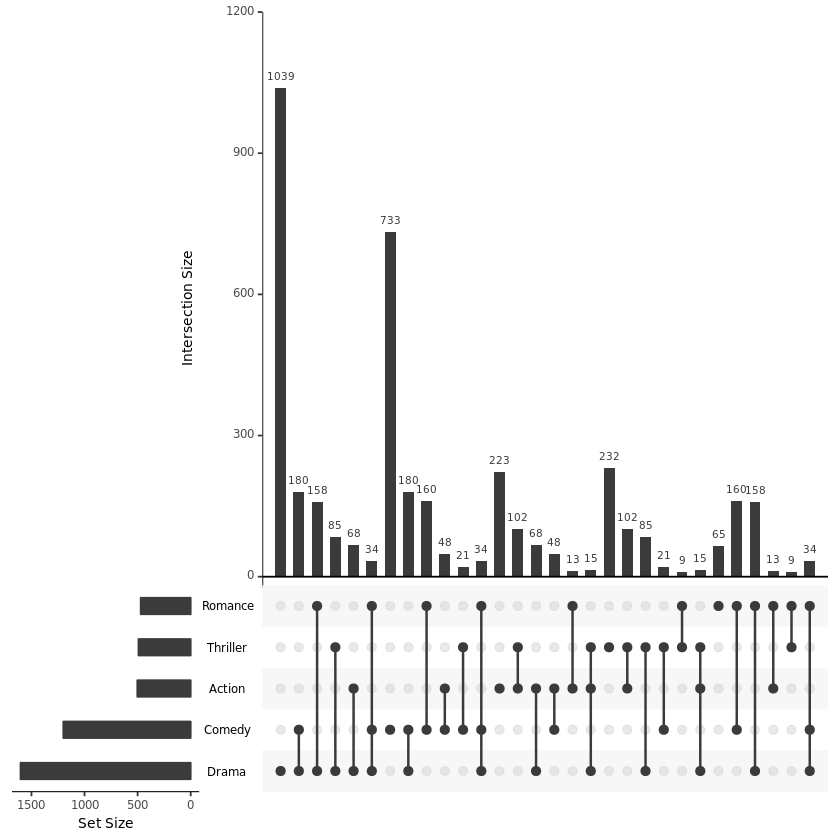
UpSetR 可视化的结果图的基本上长得像下图这个样子:
与之相对应的韦恩图:
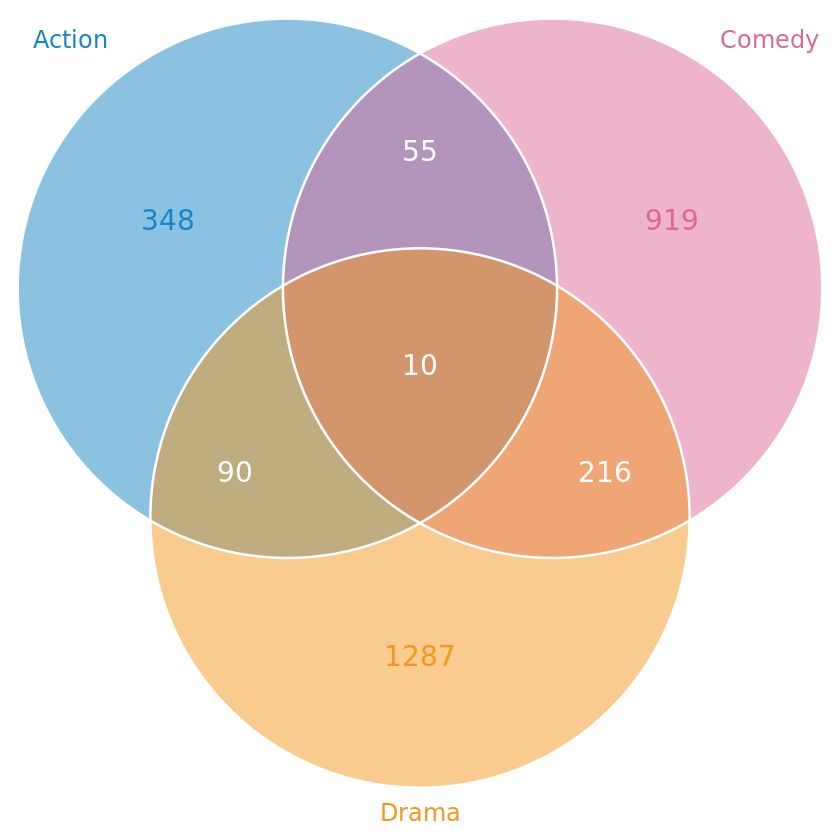
上述两个图是从 UpSetR 内置的分析了不同电影所属类型的 movies 数据集中选取了 Name、Action Comedy、Drama 4 列数据进行画图得到的结果:
黑色点表示该区域是有数据的且上方的 Intersection Size 条形图是该区域的数值大小;灰色的点表示该区域没有数据;
不同点连线表示存在交集,具体交集的个数可以看上方的条形图;
不同类型的数据的总量可以看左边的 Set Size 条形图。
二
安装
UpSetR 有两种方式安装:
# 从 CRAN 安装
install.packages("UpSetR")
# 从 Github 上安装
devtools::install_github("hms-dbmi/UpSetR")【左右滑动查看完整信息】
三
数据导入
UpsetR 接受三种类型的数据输入:
表格形式,在 R 语言里就是数据框了。行表示元素,列表示数据集分配和额外信息。
元素名的集合( fromList )。
venneuler 包引入的用于描述集合交集的向量 ( fromExpression)。
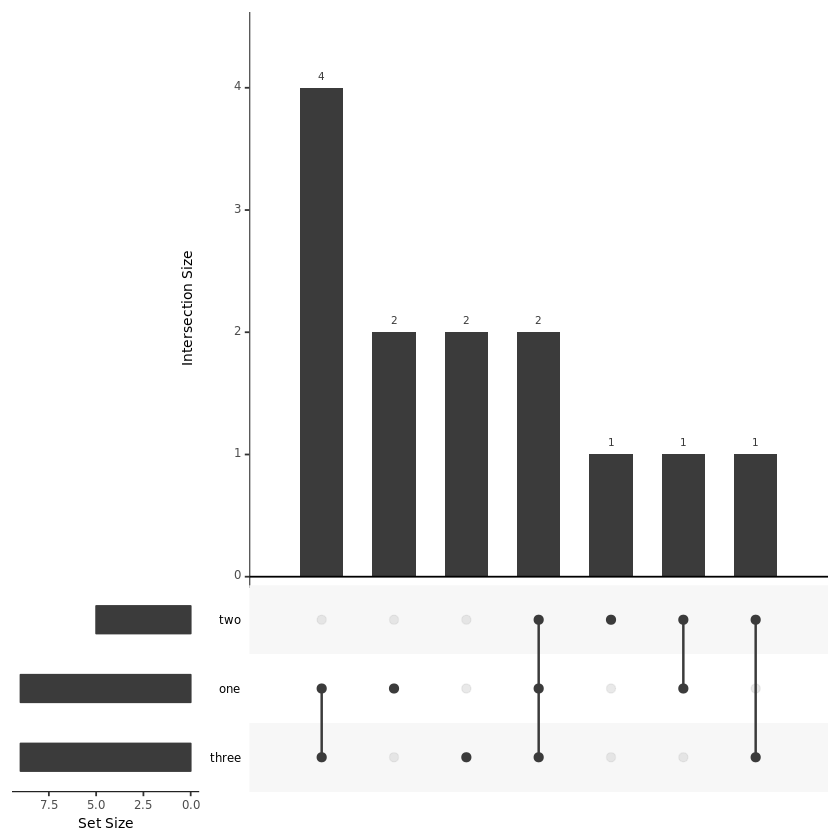
#fromList
listinput <- list(one = c(1, 2, 3, 5, 7, 8, 11, 12, 13), two = c(1, 2, 4, 5, 10), three = c(1, 5, 6, 7, 8, 9, 10, 12, 13))
#fromExpression
expressionInput <- c(one = 2, two = 1, three = 2, `one&two` = 1, `one&three` = 4, `two&three` = 1, `one&two&three` = 2)【左右滑动查看完整信息】
接下来就可以绘制绘制图形了:
library(UpSetR)
upset(fromList(listinput), order.by = "freq")
#下面绘制的图形等同于上图
upset(fromExpression(expressionInput), order.by = "freq")
【左右滑动查看完整信息】
四
参数详解
下面所有的例子都将使用 UpSetR 内置的数据集 movies 来绘制。
#导入数据
movies <- read.csv(system.file("extdata", "movies.csv", package = "UpSetR"), header = TRUE, sep = ";")
#先大致浏览一下该数据集,数据集太长,就只看前几列
knitr::kable(head(movies[,1:10]))【左右滑动查看完整信息】
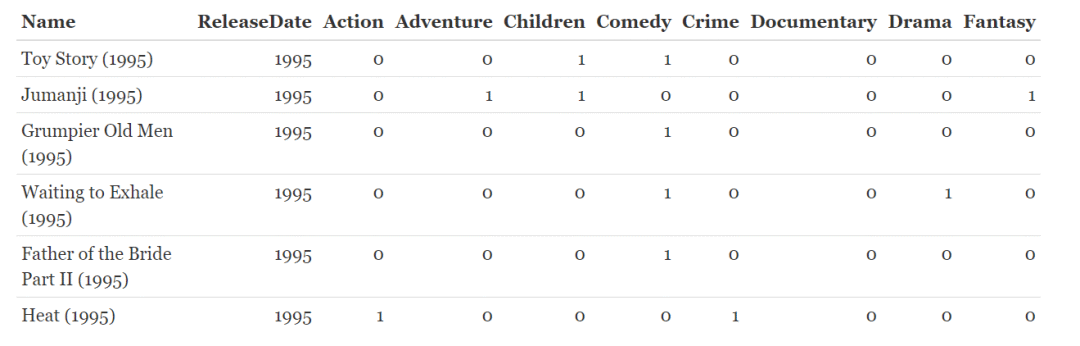
该数据集展示的是电影名(name)、发行时间(ReleaseDate)以及电影类型,数据的详细信息自己可以看去。
UpsetR 绘制集合可视化图形使用函数 upset()。
upset(movies, nsets = 6, number.angles = 30, point.size = 2, line.size = 1, mainbar.y.label = "Genre Intersections", sets.x.label = "Movies Per Genre", text.scale = c(1.3, 1.3, 1, 1, 1.5, 1))【左右滑动查看完整信息】
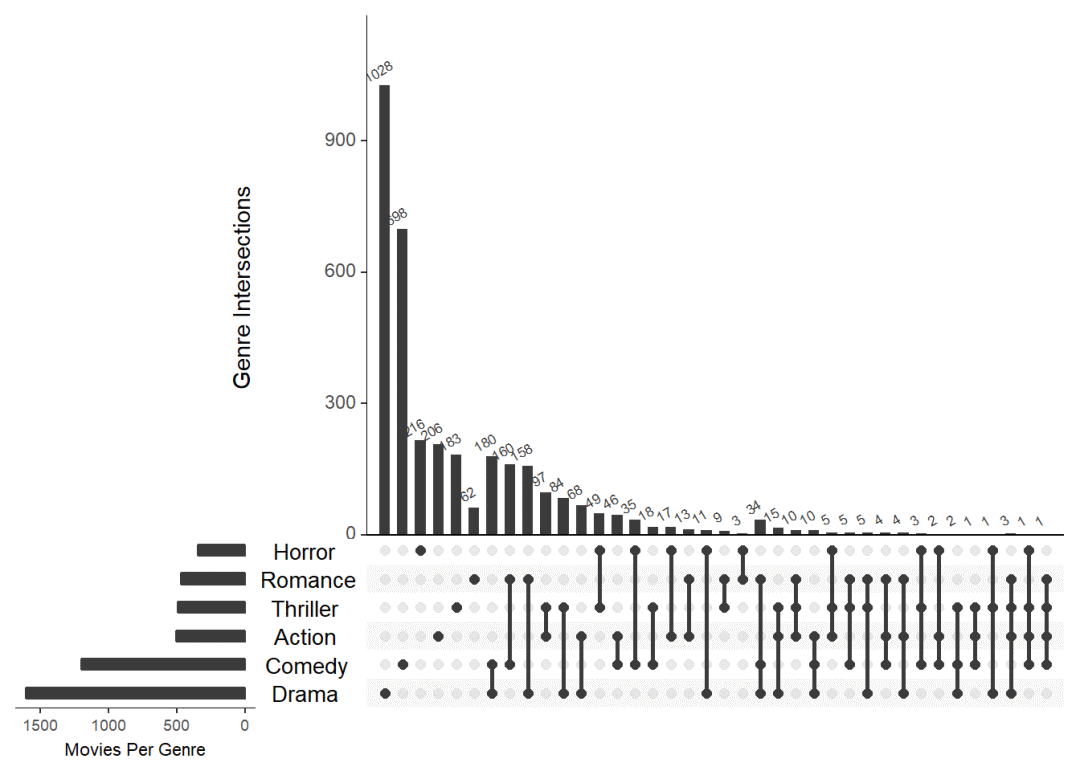
解释一下上面部分参数:
nsets:顾名思义,就是展示几个集合,movies 数据集有 20 几个集合,这里只展示其中的6个,另外从图中可以看出,这 6 个集合应该不是按顺序选择的。
numble.angle:这个参数就是调整柱子上数字的角度的。
mainbar.y.label/sets.x.label:坐标轴名称。
text.scale():有六个数字,分别控制 c(intersection size title, intersection size tick labels, set size title, set size tick labels, set names, numbers above bars) 这 6 个字体的大小。
很多时候我们想要看特定的几个集合:
upset(movies, sets = c("Action", "Adventure", "Comedy", "Drama", "Mystery", "Thriller", "Romance", "War", "Western"), mb.ratio = c(0.55, 0.45), order.by = "freq")【左右滑动查看完整信息】
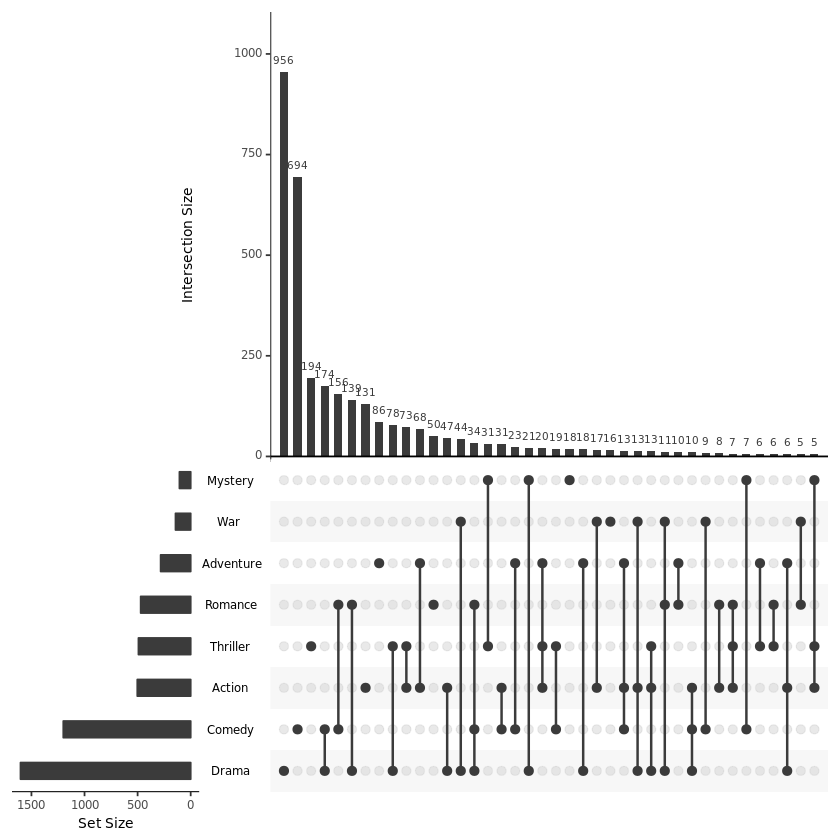
参数解释:
mb.ratio:控制上方条形图以及下方点图的比例。
order.by:如何排序,这里 freq 表示从大到小排序展示,其他选项有 degree 以及先按 freq 再按 degree 排序。
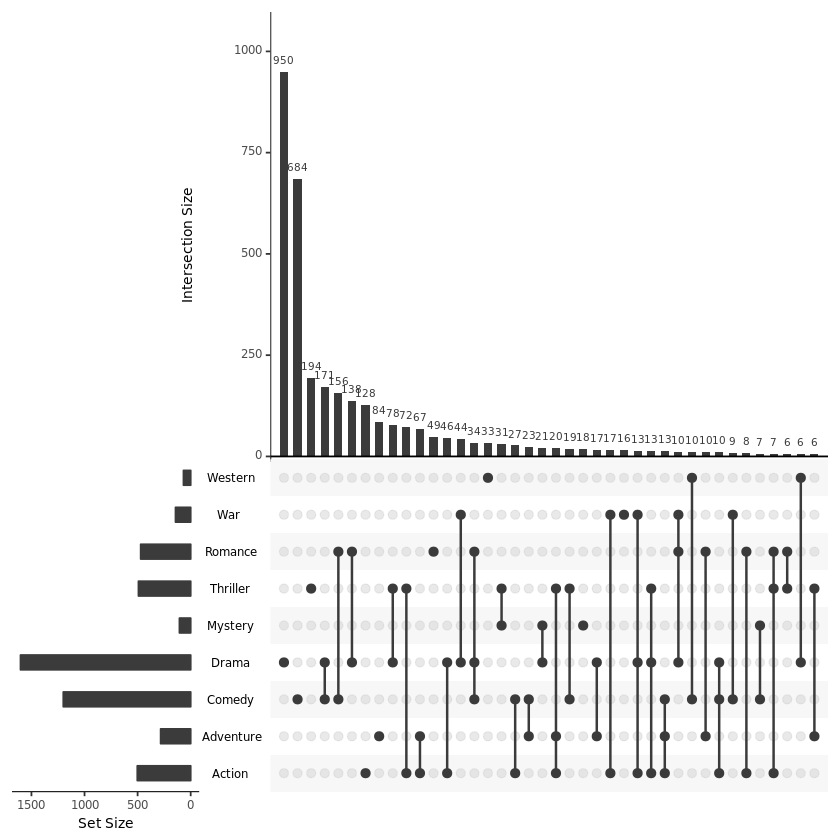
通过 keep.order 参数来对各个变量进行排序:
upset(movies, sets = c("Action", "Adventure", "Comedy", "Drama", "Mystery", "Thriller", "Romance", "War", "Western"), mb.ratio = c(0.55, 0.45), order.by = "freq", keep.order = TRUE)【左右滑动查看完整信息】
也可以按 group 进行展示,下图展示的就是按各个变量自身、两个交集、三个交集......依次展示。参数 cutoff 控制每个 group 显示几个交集。参数 intersects 控制总共显示几个交集。
upset(movies, nintersects = 60, group.by = "sets", cutoff = 6)【左右滑动查看完整信息】
还有很多参数比如控制颜色的参数,点、线大小等,具体可通过 ?upset 或者 help(upset) 查看帮助信息。
下一篇文章,我们将会介绍一下 UpSetR 其他一些高级参数的用法。
本文分享自微信公众号 - 生信科技爱好者(bioitee)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
UpSetR:多数据集绘图可视化处理利器的更多相关文章
- 给Clouderamanager集群里安装可视化分析利器工具Hue步骤(图文详解)
扩展博客 以下,是我在手动的CDH版本,安装Hue. CDH版本大数据集群下搭建Hue(hadoop-2.6.0-cdh5.5.4.gz + hue-3.9.0-cdh5.5.4.tar.gz)(博主 ...
- 给Ambari集群里安装可视化分析利器工具Hue步骤(图文详解)
扩展博客 以下,是我在手动的CDH版本平台下,安装Hue. CDH版本大数据集群下搭建Hue(hadoop-2.6.0-cdh5.5.4.gz + hue-3.9.0-cdh5.5.4.tar.gz) ...
- Seaborn(二)之数据集分布可视化
Seaborn(二)之数据集分布可视化 当处理一个数据集的时候,我们经常会想要先看看特征变量是如何分布的.这会让我们对数据特征有个很好的初始认识,同时也会影响后续数据分析以及特征工程的方法.本篇将会介 ...
- python中利用matplotlib绘图可视化知识归纳
python中利用matplotlib绘图可视化知识归纳: (1)matplotlib图标正常显示中文 import matplotlib.pyplot as plt plt.rcParams['fo ...
- Python--matplotlib 绘图可视化练手--折线图/条形图
最近学习matplotlib绘图可视化,感觉知识点比较多,边学习边记录. 对于数据可视化,个人建议Jupyter Notebook. 1.首先导包,设置环境 import pandas as pd i ...
- Python--matplotlib绘图可视化知识点整理
from:https://segmentfault.com/a/1190000005104723 本文作为学习过程中对matplotlib一些常用知识点的整理,方便查找. 强烈推荐ipython无论你 ...
- python实现cifar10数据集的可视化
在学习tensorflow的mnist和cifar实例的时候,官方文档给出的讲解都是一张张图片,直观清晰,当我们看到程序下载下来的数据的时候,宝宝都惊呆了,都是二进制文件,这些二进制文件还不小,用文本 ...
- Python基础——matplotlib库的使用与绘图可视化
1.matplotlib库简介: Matplotlib 是一个 Python 的 2D绘图库,开发者可以便捷地生成绘图,直方图,功率谱,条形图,散点图等. 2.Matplotlib 库使用: 注:由于 ...
- 四、绘图可视化之Seaborn
Seaborn-Powerful Matplotlib Extension seaborn实现直方图和密度图 import numpy as np import pandas as pd import ...
- cifar-10数据集的可视化
import numpy as np from PIL import Image import pickle import os CHANNEL = 3 WIDTH = 32 HEIGHT = 32 ...
随机推荐
- 一次spark任务提交参数的优化
起因 新接触一个spark集群,明明集群资源(core,内存)还有剩余,但是提交的任务却申请不到资源. 分析 环境 spark 2.2.0 基于yarn集群 参数 spark任务提交参数中最重要的几个 ...
- IDEA2022中部署Tomcat Web项目
使用工具: IDEA2022 Tomcat9.0.4 1.下载Tomcat: 官网:https://tomcat.apache.org/ 找到需要的版本下载即可,下载完成解压即可用: Tomcat目录 ...
- 字符串常见API(charCodeAt\fromCharCode)
1.myStr.charCodeAt(num) 返回指定位置的字符的Unicode(是字符编码的一种模式)编码. 2.String.fromCharCode() String的意思就是不能用自己定义的 ...
- Spring(Ioc和Bean的作用域)
Spring Spring为简化开发而生,让程序员只关心核心业务的实现,尽可能的不在关注非业务逻辑代码(事务控制,安全日志等). 1,Spring八大模块 这八大模块组成了Spring 1.1 Spr ...
- python-爬虫-css提取-写入csv-爬取猫眼电影榜单
猫眼有一个电影榜单top100,我们将他的榜单电影数据(电影名.主演.上映时间.豆瓣评分)抓下来保存到本地的excle中 本案例使用css方式提取页面数据,所以会用到以下库 import time i ...
- [Java EE]Spring Boot 与 Spring Cloud的关系/过去-现在-未来
1 微服务架构 定义 微服务 (Microservices) 是一种软件架构风格, 它是以专注于单一责任与功能的小型功能区块 (Small Building Blocks) 为基础, 利用模块化的方式 ...
- mapper接口中常见的增删改查
前言 相信大家在使用mybatis写mapper接口的时候,最常用且简单的方法就是增删改查了.我也是刚开始做项目,在本篇文章中,我将根据自己在vhr微人力项目中的mapper接口方法为实例,记录一下接 ...
- 四月十号java知识点
1.数组:若干个相同数据类型元素按照一定顺序排列的集合2.JAVA语言内存分为栈内存和堆内存3.方法中的一些基本类型变量和对象的引用变量都在方法中的栈内存中分配4.堆内存用来存放new运算符创建的数组 ...
- 高可用(keepalived)部署方案
前言:为了减少三维数据中心可视化管理系统的停工时间,保持其服务的高度可用性.同时部署多套同样的三维可视化系统,让三维数据中心可视化系统同时部署并运行到多个服务器上.同时提供一个虚拟IP,然后外面通过这 ...
- TS(一)环境搭建与基本类型
1 TypeScript 环境搭建 1 准备NodeJs环境 2 npm全局安装typeScript npm i -g typescript 3 编写一个ts文件 4 使用tsc命令编译ts文件为js ...