2023-11-08:用go语言,字符串哈希原理和实现 比如p = 233, 也就是课上说的选择的质数进制 “ 3 1 2 5 6 ...“ 0 1 2 3 4 hash[0] = 3 * p的0
2023-11-08:用go语言,字符串哈希原理和实现
比如p = 233, 也就是课上说的选择的质数进制
" 3 1 2 5 6 ..."
0 1 2 3 4
hash[0] = 3 * p的0次方
hash[1] = 3 * p的1次方 + 1 * p的0次方
hash[2] = 3 * p的2次方 + 1 * p的1次方 + 2 * p的0次方
hash[3] = 3 * p的3次方 + 1 * p的2次方 + 2 * p的1次方 + 5 * p的0次方
hash[4] = 3 * p的4次方 + 1 * p的3次方 + 2 * p的2次方 + 5 * p的1次方 + 6 * p的0次方
次方是倒过来的,课上讲错了
所以hash[i] = hash[i-1] * p + arr[i],这个方式就可以得到上面说的意思
于是,你想得到子串"56"的哈希值
子串"56"的哈希值 = hash[4] - hash[2]*p的2次方(就是子串"56"的长度次方)
hash[4] = 3 * p的4次方 + 1 * p的3次方 + 2 * p的2次方 + 5 * p的1次方 + 6 * p的0次方
hash[2] = 3 * p的2次方 + 1 * p的1次方 + 2 * p的0次方
hash[2] * p的2次方 = 3 * p的4次方 + 1 * p的3次方 + 2 * p的2次方
所以hash[4] - hash[2] * p的2次方 = 5 * p的1次方 + 6 * p的0次方
这样就得到子串"56"的哈希值了
抱歉,课上讲错了。应该是上面的方式。
所以,子串s[l...r]的哈希值 = hash[r] - hash[l-1] * p的(r-l+1)次方
也就是说,hash[l-1] * p的(r-l+1)次方,正好和hash[r]所代表的信息,前面对齐了
减完之后,正好就是子串s[l...r]的哈希值。
来自左程云。
答案2023-11-08:
go和c++代码用灵捷3.5编写,不需要修改。
大体过程如下:
rightCheck函数的过程:
1.检查l1和l2是否超出字符串边界,如果超出则返回false。
2.如果l1和l2相等,则直接返回true。
3.判断从l1开始长度为length的子串和从l2开始长度为length的子串是否相等,如果相等则返回true,否则返回false。
hashCheck函数的过程:
1.计算l1到r1和l2到r2两个子串的哈希值。
2.检查r1和r2是否超出字符串边界,如果超出则返回false。
3.根据哈希值判断两个子串是否相等,如果相等则返回true,否则返回false。
rightCheck函数的时间复杂度:O(length)
hashCheck函数的时间复杂度:O(1)
rightCheck函数的额外空间复杂度:O(1)
hashCheck函数的额外空间复杂度:O(1)
go完整代码如下:
package main
import (
"fmt"
"math/rand"
)
const MAXN = 100005
var pow [MAXN]int64
var hash [MAXN]int64
var base = 499
func rightCheck(str string, l1 int, l2 int, length int) bool {
if l1+length > len(str) || l2+length > len(str) {
return false
}
if l1 == l2 {
return true
}
return str[l1:l1+length] == str[l2:l2+length]
}
func build(str string, n int) {
pow[0] = 1
for j := 1; j < n; j++ {
pow[j] = pow[j-1] * int64(base)
}
hash[0] = int64(str[0]-'a') + 1
for j := 1; j < n; j++ {
hash[j] = hash[j-1]*int64(base) + int64(str[j]-'a') + 1
}
}
func hashCheck(n, l1, l2, length int) bool {
r1 := l1 + length - 1
r2 := l2 + length - 1
if r1 >= n || r2 >= n {
return false
}
return hashf(l1, r1) == hashf(l2, r2)
}
func hashf(l, r int) int64 {
var ans int64
ans = hash[r]
if l == 0 {
ans -= 0
} else {
ans -= hash[l-1] * pow[r-l+1]
}
return ans
}
func randomString(length, v int) string {
str := make([]byte, length)
for i := 0; i < length; i++ {
str[i] = byte('a' + (int64(v)*int64(i))%26)
}
return string(str)
}
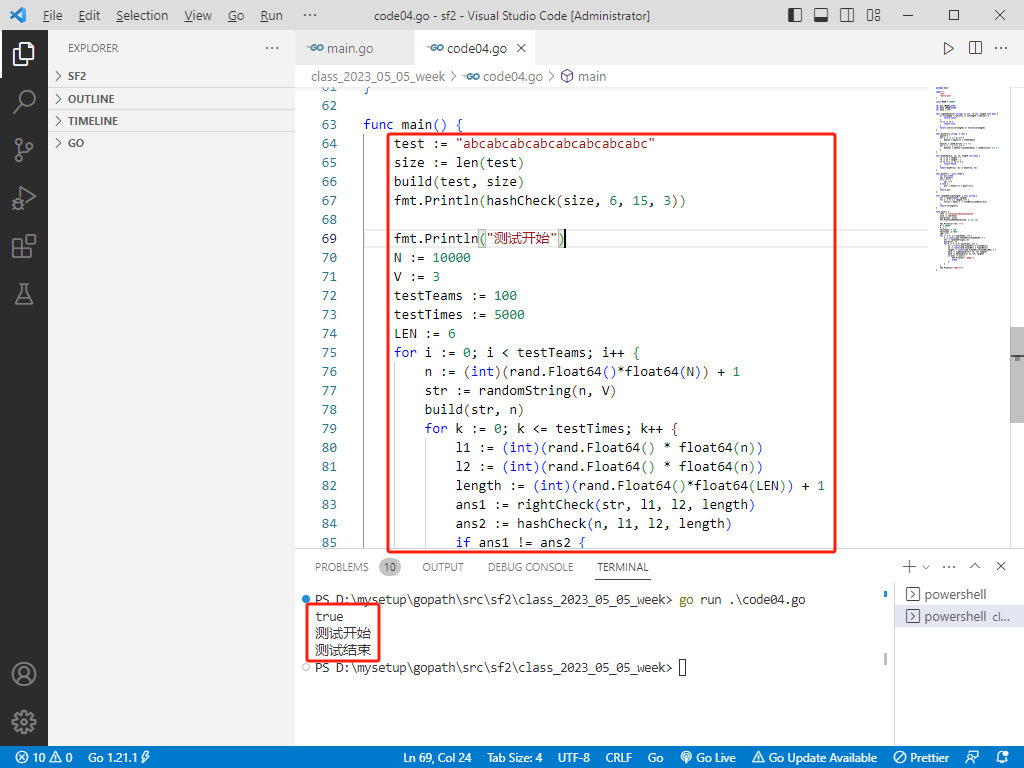
func main() {
test := "abcabcabcabcabcabcabcabc"
size := len(test)
build(test, size)
fmt.Println(hashCheck(size, 6, 15, 3))
fmt.Println("测试开始")
N := 10000
V := 3
testTeams := 100
testTimes := 5000
LEN := 6
for i := 0; i < testTeams; i++ {
n := (int)(rand.Float64()*float64(N)) + 1
str := randomString(n, V)
build(str, n)
for k := 0; k <= testTimes; k++ {
l1 := (int)(rand.Float64() * float64(n))
l2 := (int)(rand.Float64() * float64(n))
length := (int)(rand.Float64()*float64(LEN)) + 1
ans1 := rightCheck(str, l1, l2, length)
ans2 := hashCheck(n, l1, l2, length)
if ans1 != ans2 {
fmt.Println("出错了!")
break
}
}
}
fmt.Println("测试结束")
}
c++完整代码如下:
#include <iostream>
#include <string>
#include <cstdlib>
using namespace std;
const int MAXN = 100005;
long long pow0[MAXN];
long long hashArr[MAXN];
int base = 499;
bool rightCheck(string str, int l1, int l2, int len) {
if (l1 + len > str.length() || l2 + len > str.length()) {
return false;
}
if (l1 == l2) {
return true;
}
return str.substr(l1, len) == str.substr(l2, len);
}
void build(string str, int n) {
pow0[0] = 1;
for (int j = 1; j < n; j++) {
pow0[j] = pow0[j - 1] * base;
}
hashArr[0] = str[0] - 'a' + 1;
for (int j = 1; j < n; j++) {
hashArr[j] = hashArr[j - 1] * base + str[j] - 'a' + 1;
}
}
bool hashCheck(int n, int l1, int l2, int len) {
int r1 = l1 + len - 1;
int r2 = l2 + len - 1;
if (r1 >= n || r2 >= n) {
return false;
}
return hashArr[l1 + len - 1] - (l1 == 0 ? 0 : hashArr[l1 - 1] * pow0[len]) == hashArr[l2 + len - 1] - (l2 == 0 ? 0 : hashArr[l2 - 1] * pow0[len]);
}
string randomString(int len, int v) {
string str;
for (int i = 0; i < len; i++) {
str += char('a' + rand() % v);
}
return str;
}
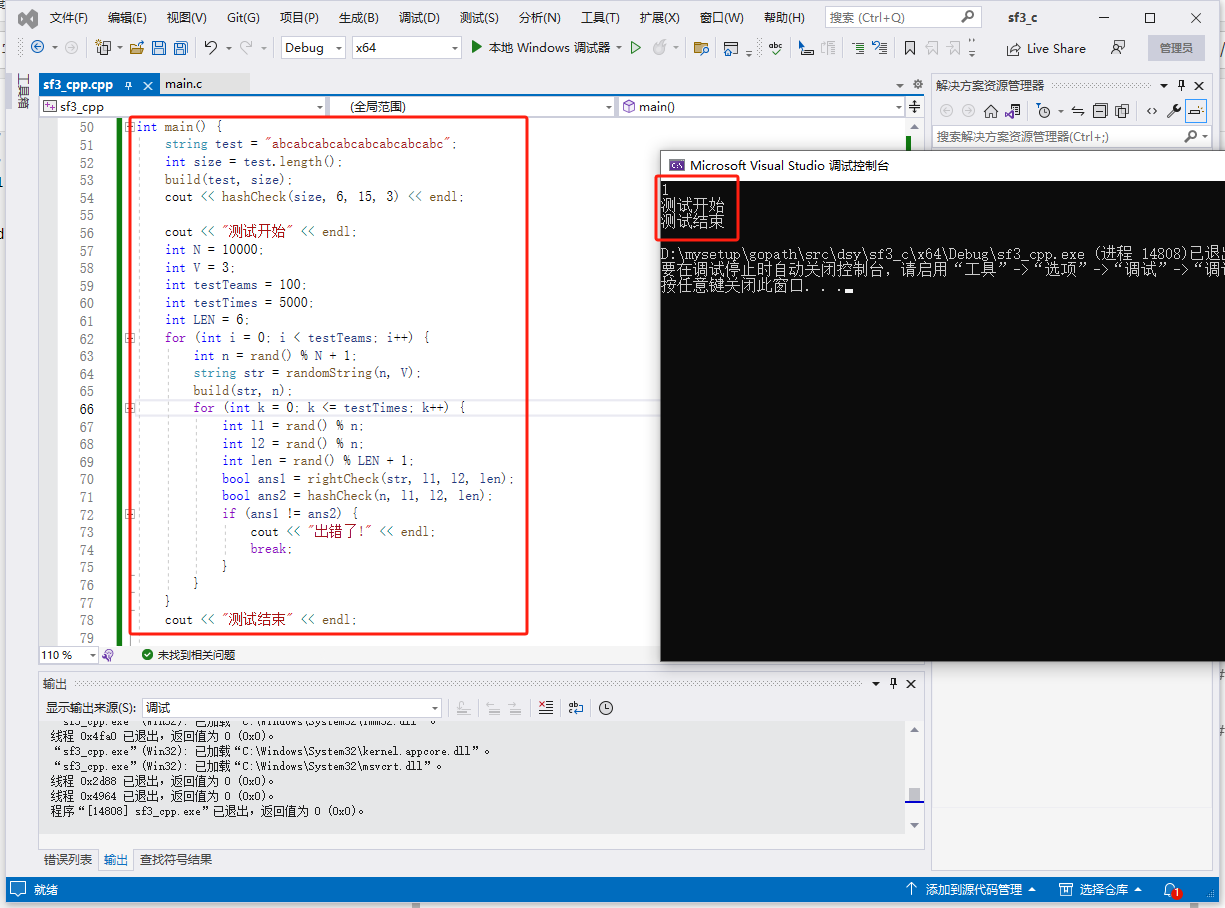
int main() {
string test = "abcabcabcabcabcabcabcabc";
int size = test.length();
build(test, size);
cout << hashCheck(size, 6, 15, 3) << endl;
cout << "测试开始" << endl;
int N = 10000;
int V = 3;
int testTeams = 100;
int testTimes = 5000;
int LEN = 6;
for (int i = 0; i < testTeams; i++) {
int n = rand() % N + 1;
string str = randomString(n, V);
build(str, n);
for (int k = 0; k <= testTimes; k++) {
int l1 = rand() % n;
int l2 = rand() % n;
int len = rand() % LEN + 1;
bool ans1 = rightCheck(str, l1, l2, len);
bool ans2 = hashCheck(n, l1, l2, len);
if (ans1 != ans2) {
cout << "出错了!" << endl;
break;
}
}
}
cout << "测试结束" << endl;
return 0;
}
2023-11-08:用go语言,字符串哈希原理和实现 比如p = 233, 也就是课上说的选择的质数进制 “ 3 1 2 5 6 ...“ 0 1 2 3 4 hash[0] = 3 * p的0的更多相关文章
- C语言字符串操作总结大全
1)字符串操作 strcpy(p, p1) 复制字符串 函数原型strncpy(p, p1, n) 复制指定长度字符串 函数原型strcat(p, p1) 附加字符串 函数原型strn ...
- C语言字符串操作总结大全(超详细)
本篇文章是对C语言字符串操作进行了详细的总结分析,需要的朋友参考下 1)字符串操作 strcpy(p, p1) 复制字符串 strncpy(p, p1, n) 复制指定长度字符串 strcat( ...
- C语言字符串操作函数集
1)字符串操作 strcpy(p, p1) 复制字符串 strncpy(p, p1, n) 复制指定长度字符串 strcat(p, p1) 附加字符串 strncat(p, p1, n) 附加指定长度 ...
- C语言字符串操作详细总结
1)字符串操作 strcpy(p, p1) 复制字符串 strncpy(p, p1, n) 复制指定长度字符串 strcat(p, p1) 附加字符串 strncat(p, p1, n) 附加指定长度 ...
- 面试之C语言字符串操作总结大全(转载)
趁着十一就好好补补数据结构吧,通信这个不软不硬的专业,现在还是得好好学学补习补习,,你这个非211的本科生!虽然拿到了一个offer,但是觉得时间还有,得继续拼一拼,希望不辜负! 1)字符串操作 st ...
- C语言学习笔记 (008) - C语言字符串操作总结大全(超详细)(转)
1)字符串操作 strcpy(p, p1) 复制字符串 strncpy(p, p1, n) 复制指定长度字符串 strcat(p, p1) 附加字符串 strncat(p, p1, n) 附加指定长度 ...
- C语言字符串操作总结大全(超具体)
1)字符串操作 strcpy(p, p1) 复制字符串 strncpy(p, p1, n) 复制指定长度字符串 strcat(p, p1) 附加字符串 strncat(p, p1, n) 附加指定长度 ...
- C语言字符串操作
1)字符串操作 strcpy(p, p1) 复制字符串 strncpy(p, p1, n) 复制指定长度字符串 strcat(p, p1) 附加字符串 strncat(p, p1, n) 附加指定长度 ...
- [转]C语言字符串操作总结大全(超详细)
1)字符串操作 strcpy(p, p1) 复制字符串 strncpy(p, p1, n) 复制指定长度字符串 strcat(p, p1) 附加字符串 strncat(p, p1, n) 附加指定长度 ...
- 07 --C语言字符串函数
1)字符串操作 复制 strcpy(p, p1) 复制字符串 strncpy(p, p1, n) 复制指定长度字符串 strdup(char *str) 将串拷贝到新建的位置处 ...
随机推荐
- (数据科学学习手札153)基于martin的高性能矢量切片地图服务构建
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 大家好我是费老师,在日常研发地图类应用的场景中, ...
- linux top中 VSS,RSS,PSS,USS 4个字段的解读
参考文章:linux中top命令 VSS,RSS,PSS,USS 四个内存字段的解读
- HTML超文本标记语言2
二.基本标签 1.文件标签(结构) <html> 根标签 <head> <title>页面标题(标签)</title> </head> &l ...
- 深入Scikit-learn:掌握Python最强大的机器学习库
本篇博客详细介绍了Python机器学习库Scikit-learn的使用方法和主要特性.内容涵盖了如何安装和配置Scikit-learn,Scikit-learn的主要特性,如何进行数据预处理,如何使用 ...
- RAT蓝队自动化测试框架
RAT蓝队自动化测试框架 介绍 RAT 是根据 MITRE ATT&CK 战术矩阵测试蓝队检测能力的脚本框架,由 python2.7 编写,共有 50 多种不同 ATT&CK 技术点和 ...
- [python]格式化字符串的几种方式
目录 方式一:C风格%操作符 方式二:内置的format函数与str类的format方法 方式三:插值格式字符串 python中有以下几种方法可以格式化字符串 方式一:C风格%操作符 这种方法偏C语言 ...
- 定义一个类,在实例化的时候,抛出NameError异常
代码1:class cla: def __init__(self): #raise NameError # 抛出异常 print(r) cla() 运行截图:
- QTreeView自绘实现酷炫样式
本篇文章结合笔者的经历,介绍一种通过重写QTreeView绘制事件,使用QPainter来实现好看的列表的方式. 导语 Hi,各位读者朋友,大家好.相信大家在日常的工作中,经常会接触到QTreeVie ...
- Avalonia 实现聊天消息渲染、图文混排(支持Windows、Linux、信创国产OS)
在实现即时通讯软件或聊天软件时,渲染文字表情.图文混排是一项非常繁琐的工作,再加上还要支持GIF动图.引用消息.撤回消息.名片等不同样式的消息渲染时,就更加麻烦了. 好在我们可以使用 ESFra ...
- 原神盲盒风格:AI绘画Stable Diffusion原神人物公仔实操:核心tag+lora模型汇总
本教程收集于:AIGC从入门到精通教程汇总 在这篇文章中,我们将深入探讨原神盲盒的艺术风格,以及如何运用AI绘画技术(Stable Diffusion)--来创造原神角色公仔.我们将通过实践操作让读者 ...