浅谈一致性Hash原理及应用
在讲一致性Hash之前我们先来讨论一个问题。
问题:现在有亿级用户,每日产生千万级订单,如何将订单进行分片分表?
小A:我们可以按照手机号的尾数进行分片,同一个尾数的手机号写入同一片/同一表中。
大佬:我希望通过会员ID来查询这个会员的所有订单信息,按照手机号分片/分表的话,前提是需要该用户的手机号保持不变,并且在查询订单列表时需要提前查询该用户的手机号,利用手机号尾数不太合理。
小B:按照大佬的思路,我们需要找出一个唯一不变的属性来进行分片/分表。
大佬:迷之微笑~
小B:(信心十足)会员在我们这边保持不变的就是会员ID(int),我们可以通过会员ID的尾数进行分片/分表
小C:尽然我们可以用会员ID尾数进行分片/分表,那就用取模的方式来进行分片/分表,通过取模的方式可以达到很好的平衡性。示意图如下:
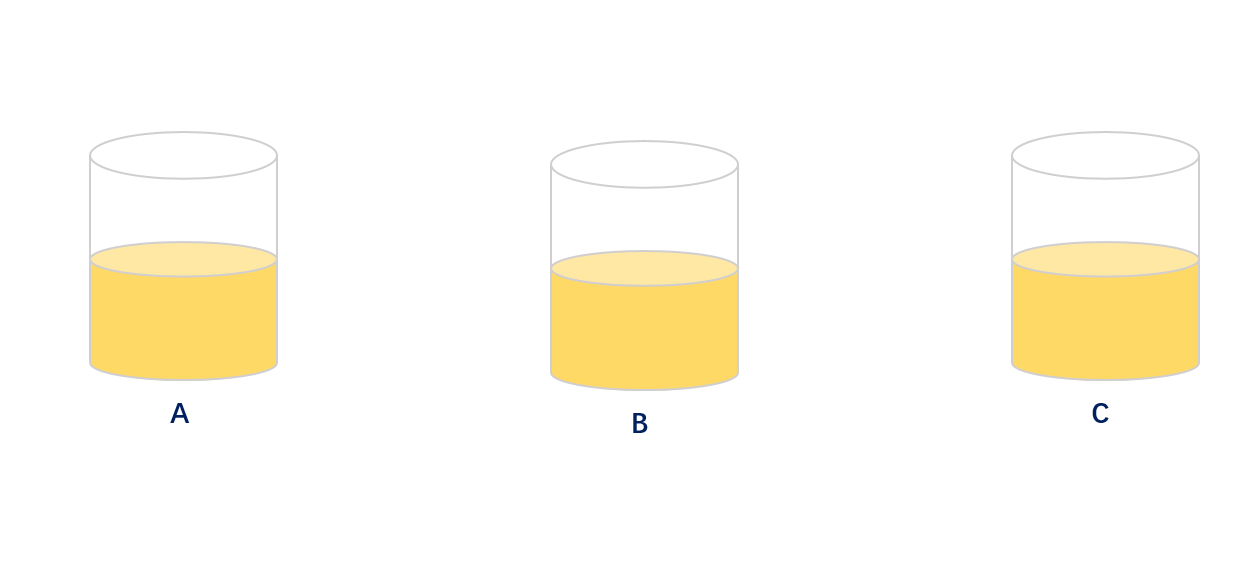
大佬:嗯嗯嗯,在不考虑会员冷热度的情况下小B和小C说的方案绝佳;但是往往我们的会员有冷热度和僵尸会员,通过取模的方式往往会出现某个分片数据异常高,部分分片数据异常低,导致平衡倾斜。示意图如下:
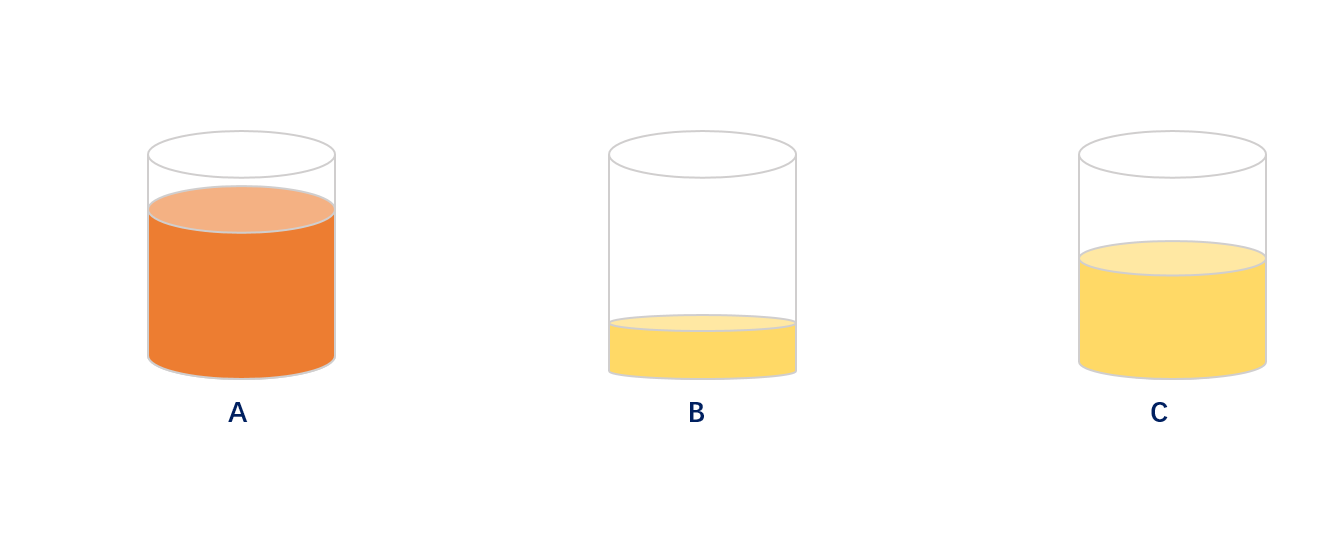
大佬:当出现某个分片/分表达到极限时我们需要添加片/表,此时发现我们无法正常添加片/表。因为一旦添加片/或表的时候会导致绝大部分数据错乱,按照原先的取模方式是无法正常获取数据的。示意图如下

添加分片/分表前4,5,6会员的订单分别存储在A,B,C上,当添加了片/表的时候在按照(会员ID%N)方式取模去取数据4,5,6会员的订单数据时发现无法取到订单数据,因为此时4,5,6这三位会员数据分布存在了D,E,A上,具体示意图如下:

大佬:所以通过取模的方式也会存在缺陷;好了接下来我们来利用一致hash原理的方式来解决分片/分表的问题。
首先什么是一致性哈希算法?一致性哈希算法(Consistent Hashing Algorithm)是一种分布式算法,常用于负载均衡。Memcached client也选择这种算法,解决将key-value均匀分配到众多Memcached server上的问题。它可以取代传统的取模操作,解决了取模操作无法应对增删Memcached Server的问题(增删server会导致同一个key,在get操作时分配不到数据真正存储的server,命中率会急剧下降)。
还以上述问题为例,假如我们有10片,我们利用Hash算法将每一片算出一个Hash值,而这些Hash点将被虚拟分布在Hash圆环上,理论视图如下:
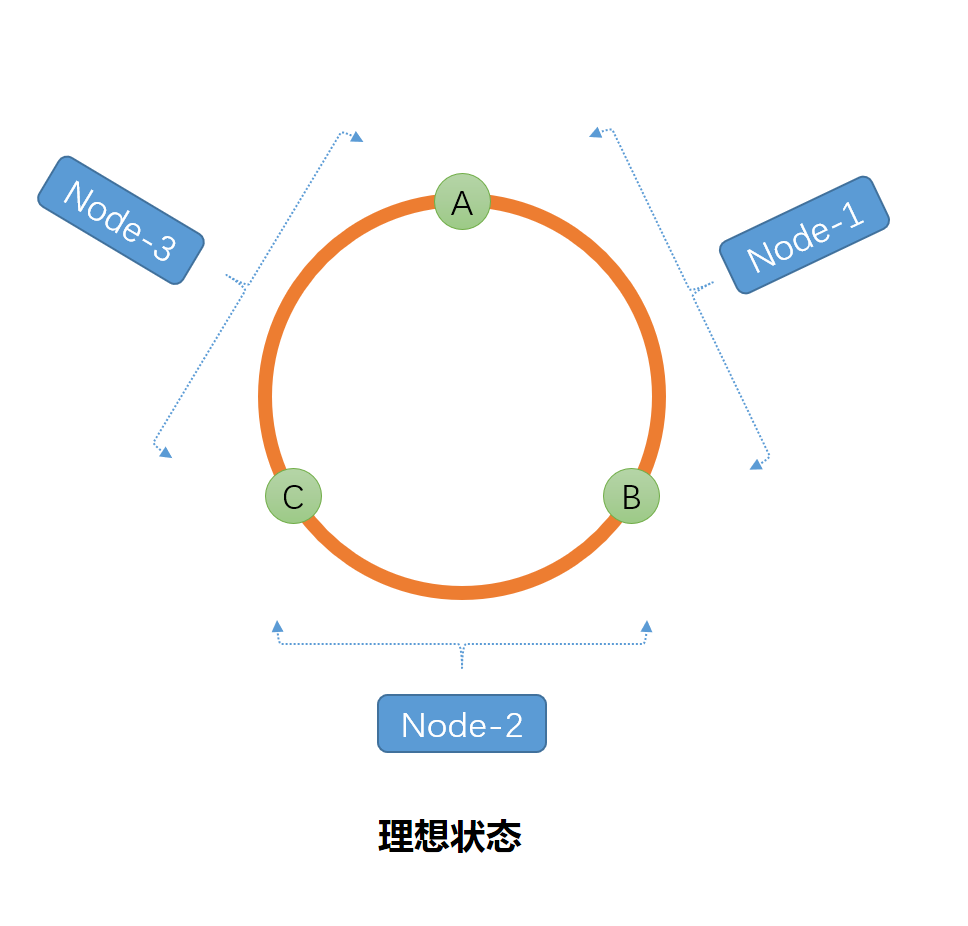
按照顺时针的方向,每个点与点之间的弧形属于每个起点片的容量,然后按照同样的Hash计算方法对每个会员ID进行Hash计算得出每个Hash值然后按照区间进行落片/表,以保证数据均匀分布。
如果此时需要在B和C之间新增一片/表(B1)的话,就不会出现按照取模形式导致数据几乎全部错乱的情况,仅仅是影响了(B1,C)之间的数据,这样我们清洗出来也就比较方便,也不会出现数据大批量
瘫痪。
但是如果我们仅仅是将片/表进行计算出Hash值之后,这些点分布并不是那么的均匀,比如就会下面的这种情况,导致区间倾斜。如图
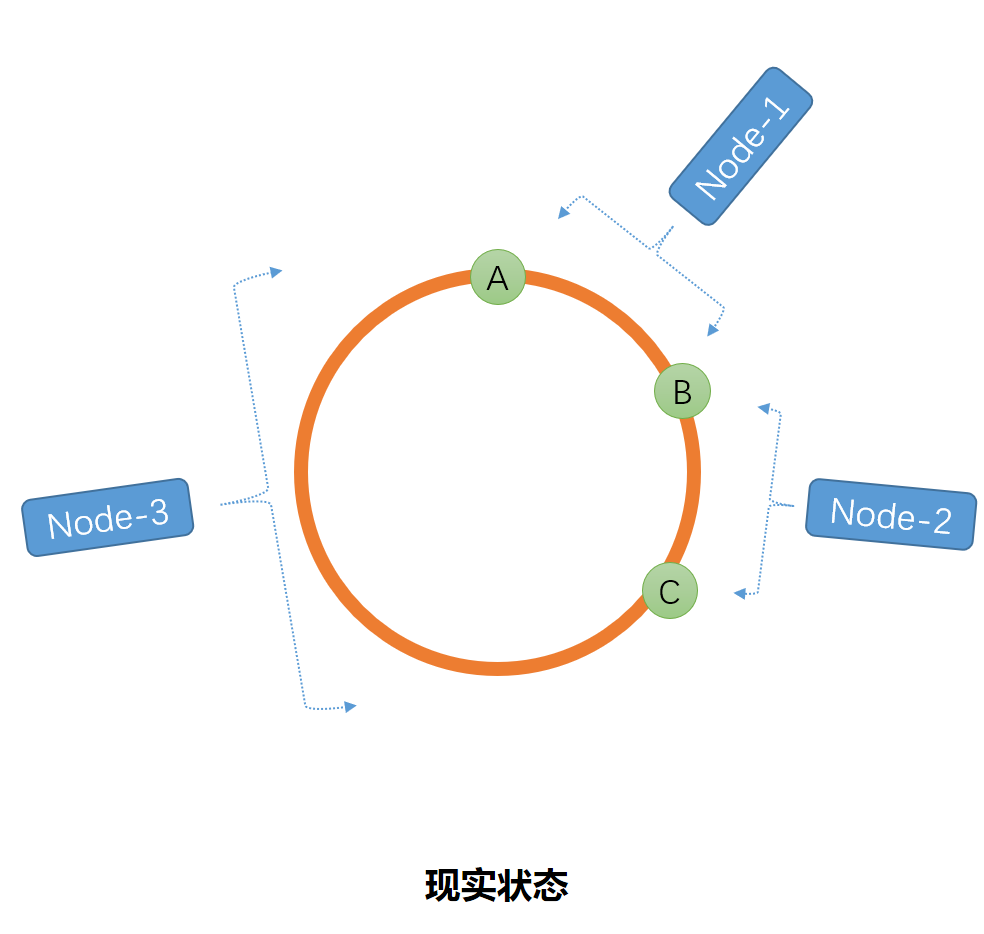
这个时候虚拟节点就此诞生,下面让我们来看一下虚拟节点在一致性Hash中的作用。当我们在Hash环上新增若干个点,那么每个点之间的距离就会接近相等。按照这个思路我们可以新增若干个
片/表,但是成本有限,我们通过复制多个A、B、C的副本({A1-An},{B1-Bn},{C1-Cn})一起参与计算,按照顺时针的方向进行数据分布,按照下图示意:
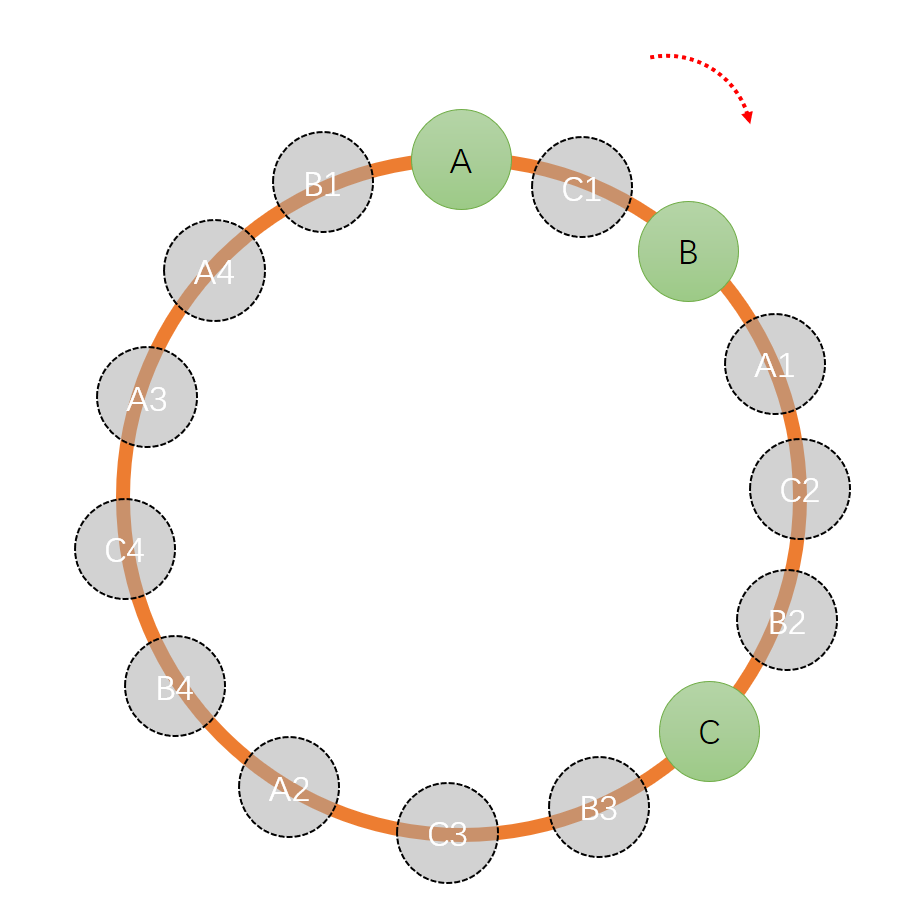
此时A=[A,C1)&[A1,C2)&[A2,B4)&[A3,A4)&[A4,B1);B=[B,A1)&[B2,C)&[B3,C3)&[B4,C4)&[B1,A);C=[C1,B)&[C2,B2)&[C,B3)&[B3,C3)&[C4,A3);由图可以看出分布点越密集,平衡性约好。
我写了一个测试用例,10台服务器,1000个虚拟节点,根据算法对50000数据精细计算得出每台机器上具体数据的分布
192.168.1.0:5011
192.168.1.1:5058
192.168.1.2:5187
192.168.1.3:4949
192.168.1.4:5097
192.168.1.5:4939
192.168.1.6:5129
192.168.1.7:4824
192.168.1.8:4957
192.168.1.9:4849
我从计算结果中打印出了20数据分布的机器情况具体如下:
ConsistentHashTest1202:192.168.1.8
ConsistentHashTest1203:192.168.1.4
ConsistentHashTest1204:192.168.1.9
ConsistentHashTest1205:192.168.1.9
ConsistentHashTest1206:192.168.1.4
ConsistentHashTest1207:192.168.1.3
ConsistentHashTest1208:192.168.1.8
ConsistentHashTest1209:192.168.1.2
ConsistentHashTest1210:192.168.1.0
ConsistentHashTest1211:192.168.1.0
ConsistentHashTest1212:192.168.1.6
ConsistentHashTest1213:192.168.1.2
ConsistentHashTest1214:192.168.1.7
ConsistentHashTest1215:192.168.1.1
ConsistentHashTest1216:192.168.1.9
ConsistentHashTest1217:192.168.1.0
ConsistentHashTest1218:192.168.1.4
ConsistentHashTest1219:192.168.1.4
然后我剔除其中一台服务器“192.168.1.8”,在根据算法进行计算并且同事打印出和上述一直的20条数据的分布情况
192.168.1.0:5011
192.168.1.1:5058
192.168.1.2:5187
192.168.1.3:4949
192.168.1.4:5097
192.168.1.5:4939
192.168.1.6:5129
192.168.1.7:4824
192.168.1.8:4957
192.168.1.9:4849
ConsistentHashTest1202:192.168.1.8
ConsistentHashTest1203:192.168.1.4
ConsistentHashTest1204:192.168.1.9
ConsistentHashTest1205:192.168.1.9
ConsistentHashTest1206:192.168.1.4
ConsistentHashTest1207:192.168.1.3
ConsistentHashTest1208:192.168.1.8
ConsistentHashTest1209:192.168.1.2
ConsistentHashTest1210:192.168.1.0
ConsistentHashTest1211:192.168.1.0
ConsistentHashTest1212:192.168.1.6
ConsistentHashTest1213:192.168.1.2
ConsistentHashTest1214:192.168.1.7
ConsistentHashTest1215:192.168.1.1
ConsistentHashTest1216:192.168.1.9
ConsistentHashTest1217:192.168.1.0
ConsistentHashTest1218:192.168.1.4
ConsistentHashTest1219:192.168.1.4
根据两次的计算结果对比我们发现减少机器后,每台机器上的数据量增加了,但是原先分布在具体机器上的数据,并没有变化。
但是一致性Hash的分布还会和数据源有关,可能会出现数据倾斜的情况。
具体C#测试代码如下:
https://github.com/tcued/LearningDemo
using System;
using System.Collections.Generic;
using System.Data.HashFunction;
using System.Data.HashFunction.xxHash;
using System.Linq; namespace HashTest
{
public class ConsistentHash1
{
/// <summary>
/// 虚拟节点数
/// </summary>
private static readonly int VirturalNodeNum = ; /// <summary>
/// 服务器IP
/// </summary>
private static readonly string[] Nodes =
{
"192.168.1.0",
"192.168.1.1",
"192.168.1.2",
"192.168.1.3",
"192.168.1.4",
"192.168.1.5",
"192.168.1.6",
"192.168.1.7",
"192.168.1.8",
"192.168.1.9"
}; /// <summary>
/// 按照一致性Hash进行分组
/// </summary>
private static readonly IDictionary<uint, string> ConsistentHashNodes = new SortedDictionary<uint, string>(); private static uint[] _nodeKeys = null;
static void Main(string[] args)
{
ComputeNode();
Print();
Console.ReadLine();
} private static void Print()
{
IDictionary<string, int> result = new SortedDictionary<string, int>();
for (int i = ; i < ; i++)
{
var node = Get("ConsistentHashTest" + i);
if (result.TryGetValue(node, out var count))
{
result[node] = count + ;
}
else
{
result[node] = ;
}
if (i > && i < )
{
Console.WriteLine($"ConsistentHashTest{i}:{node}");
}
} foreach (var node in result)
{
Console.WriteLine($"{node.Key}:{node.Value}");
}
} private static void ComputeNode()
{
foreach (var node in Nodes)
{
AddNode(node);
} _nodeKeys = ConsistentHashNodes.Keys.ToArray();
} private static void AddNode(string node)
{
for (int i = ; i < VirturalNodeNum; i++)
{
var key = node + ":" + i;
var hashValue = ComputeHash(key);
if (!ConsistentHashNodes.ContainsKey(hashValue))
{
ConsistentHashNodes.Add(hashValue, node);
}
}
} private static uint ComputeHash(string virturalNode)
{
var hashFunction = xxHashFactory.Instance.Create();
var hashValue = hashFunction.ComputeHash(virturalNode);
return BitConverter.ToUInt32(hashValue.Hash, );
} private static string Get(string item)
{
var hashValue = ComputeHash(item);
var index = GetClockwiseNearestNode(hashValue);
return ConsistentHashNodes[_nodeKeys[index]];
} private static int GetClockwiseNearestNode(uint hash)
{
int begin = ;
int end = _nodeKeys.Length - ; if (_nodeKeys[end] < hash || _nodeKeys[] > hash)
{
return ;
} while ((end - begin) > )
{
var mid = (end + begin) / ;
if (_nodeKeys[mid] >= hash) end = mid;
else begin = mid;
} return end;
}
}
}
浅谈一致性Hash原理及应用的更多相关文章
- 浅尝一致性Hash原理
写在前面 在解决分布式系统中负载均衡的问题时候可以使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡的作用.但是普通的余数ha ...
- 浅谈一致性hash
相信做过互联网应用的都知道,如何很好的做到横向扩展,其实是个蛮难的话题,缓存可横向扩展,如果采用简单的取模,余数方式的部署,基本是无法做到后期的扩展的,数据迁移及分布都是问题,举个例子: 假设采用取模 ...
- 浅谈字符串Hash
浅谈字符串Hash 本篇随笔讲解Hash(散列表)的一个重要应用:字符串Hash. 关于Hash Hash是一种数据结构,叫做Hash表(哈希表),也叫散列表.关于Hash的实现,其实与离散化颇为类似 ...
- 百度资深架构师带你深入浅出一致性Hash原理
一.前言 在解决分布式系统中负载均衡的问题时候可以使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡的作用. 但是普通的余数h ...
- [py]一致性hash原理
1,可变,不可变 python中值得是引用地址是否变化. 2.可hash 生命周期里不可变得值都可hash 3.python中内置数据结构特点 有序不可变 有序可变 无序可变 无序不可变 5.一致性h ...
- 浅谈html运行原理
浅谈HTML运行原理,所谓的HTML简单的来说就是一个网页,虽然第一节就讲html原理可能大家会听不懂,就当是给一个初步印象把,至少大概知道一个网页的运行流程是怎样的,下面上一张图: 大致的一个htm ...
- 深入浅出一致性Hash原理
转自:https://www.jianshu.com/p/e968c081f563 一.前言 在解决分布式系统中负载均衡的问题时候可以使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务 ...
- 浅谈React工作原理
浅谈React工作原理:https://www.cnblogs.com/yikuu/p/9660932.html 转自:https://cloud.tencent.com/info/63f656e0b ...
- [白话解析] 深入浅出一致性Hash原理
[白话解析] 深入浅出一致性Hash原理 0x00 摘要 一致性哈希算法是分布式系统中常用的算法.但相信很多朋友都是知其然而不知其所以然.本文将尽量使用易懂的方式介绍一致性哈希原理,并且通过具体应用场 ...
随机推荐
- Docker(二)
Docker Compose 多主机网络 容器集群管理 Docker结合Jenkins构建持续集成环境 Docker结合Consul实现服务发现 Docker API 日志管理
- 散列表Java实现
package 散列表; import java.util.Scanner; public class HashSearch { public static int data[] = {69,65,9 ...
- Java之Integer源码
1.为什么Java中1000==1000为false而100==100为true? 这是一个挺有意思的讨论话题. 如果你运行下面的代码 Integer a = 1000, b = 1000; Syst ...
- Ruby 安装和gem配置
在linux或mac等*unix系统下可以使用rvm来进行ruby的配置和管理. 安装方法 (需要curl) curl -L get.rvm.io | bash -s stable rvm官方网站: ...
- kylin与superset整合
前提: kylin安装以及配置可以参考 https://www.cnblogs.com/654wangzai321/p/9676204.html 我这边用的Linux自带的python2.7,为了保证 ...
- SQL学习笔记二之MySQL的数据库操作
阅读目录 一 系统数据库 二 创建数据库 三 数据库相关操作 一 系统数据库 information_schema: 虚拟库,不占用磁盘空间,存储的是数据库启动后的一些参数,如用户表信息.列信息.权限 ...
- 20145105 《Java程序设计》第1周学习总结
20145105 <Java程序设计>第1周学习总结 教材学习内容总结 学习了教材的第一章后,我初步了解了Java的发展历程,以及什么是JCP,JSR,JVM.JCP是一个开放性国际组织, ...
- Linux内核分析 05
扒开系统调用的三层皮(下) 一,给MenuOS增加time和time-asm命令 把time和time-asm添加到MenuOS里面去 作为命令.扩展MenuOS的功能.本周把上周增加的系统调用添加进 ...
- POJ 1006 Biorhythnms(中国剩余定理)
http://poj.org/problem?id=1006 题意: (n+d) % 23 = p ;(n+d) % 28 = e ;(n+d) % 33 = i ; 求最小的n. 思路: 这道题就是 ...
- 2016湘潭邀请赛—Heartstone
http://202.197.224.59/OnlineJudge2/index.php/Problem/read/id/1246 题意: 有n只怪,每只怪有指定的HP.现在1和2两种攻击方式,前者扣 ...