深度学习(十) GoogleNet
GoogLeNet Incepetion V1
这是GoogLeNet的最早版本,出现在2014年的《Going deeper with convolutions》。之所以名为“GoogLeNet”而非“GoogleNet”,文章说是为了向早期的LeNet致敬。
介绍
深度学习以及神经网络快速发展,人们不再只关注更给力的硬件、更大的数据集、更大的模型,而是更在意新的idea、新的算法以及模型的改进。
一般来说,提升网络性能最直接的办法就是增加网络深度和宽度,这也就意味着巨量的参数。但是,巨量参数容易产生过拟合也会大大增加计算量。
文章认为解决上述两个缺点的根本方法是将全连接甚至一般的卷积都转化为稀疏连接。一方面现实生物神经系统的连接也是稀疏的,另一方面有文献1表明:对于大规模稀疏的神经网络,可以通过分析激活值的统计特性和对高度相关的输出进行聚类来逐层构建出一个最优网络。这点表明臃肿的稀疏网络可能被不失性能地简化。 虽然数学证明有着严格的条件限制,但Hebbian准则有力地支持了这一点:fire together,wire together。
早些的时候,为了打破网络对称性和提高学习能力,传统的网络都使用了随机稀疏连接。但是,计算机软硬件对非均匀稀疏数据的计算效率很差,所以在AlexNet中又重新启用了全连接层,目的是为了更好地优化并行运算。
所以,现在的问题是有没有一种方法,既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。大量的文献表明可以将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能,据此论文提出了名为Inception 的结构来实现此目的。
前言
Inception 结构的主要思路是怎样用密集成分来近似最优的局部稀疏结构(特征太分散)。
作者首先提出下图这样的基本结构:
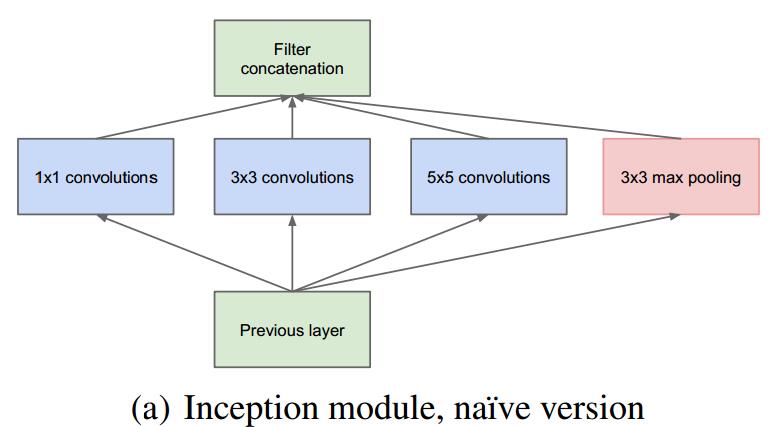
对上图做以下说明:
1 . 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
2 . 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
3 . 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了。
4 . 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。
但是,使用5x5的卷积核仍然会带来巨大的计算量。 为此,文章借鉴NIN2,采用1x1卷积核来进行降维。
例如:上一层的输出为100x100x128,经过具有256个输出的5x5卷积层之后(stride=1,pad=2),输出数据为100x100x256。其中,卷积层的参数为128x5x5x256。假如上一层输出先经过具有32个输出的1x1卷积层,再经过具有256个输出的5x5卷积层,那么最终的输出数据仍为为100x100x256,但卷积参数量已经减少为128x1x1x32 + 32x5x5x256,大约减少了4倍。
具体改进后的Inception Module如下图:

GoogLeNet
GoogLeNet的整体结构如下图:

对上图做如下说明:
1 . 显然GoogLeNet采用了模块化的结构,方便增添和修改;
2 . 网络最后采用了average pooling来代替全连接层,想法来自NIN,事实证明可以将TOP1 accuracy提高0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便以后大家finetune;
3 . 虽然移除了全连接,但是网络中依然使用了Dropout ;
4 . 为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度。文章中说这两个辅助的分类器的loss应该加一个衰减系数,但看caffe中的model也没有加任何衰减。此外,实际测试的时候,这两个额外的softmax会被去掉。
下图是一个比较清晰的结构图:
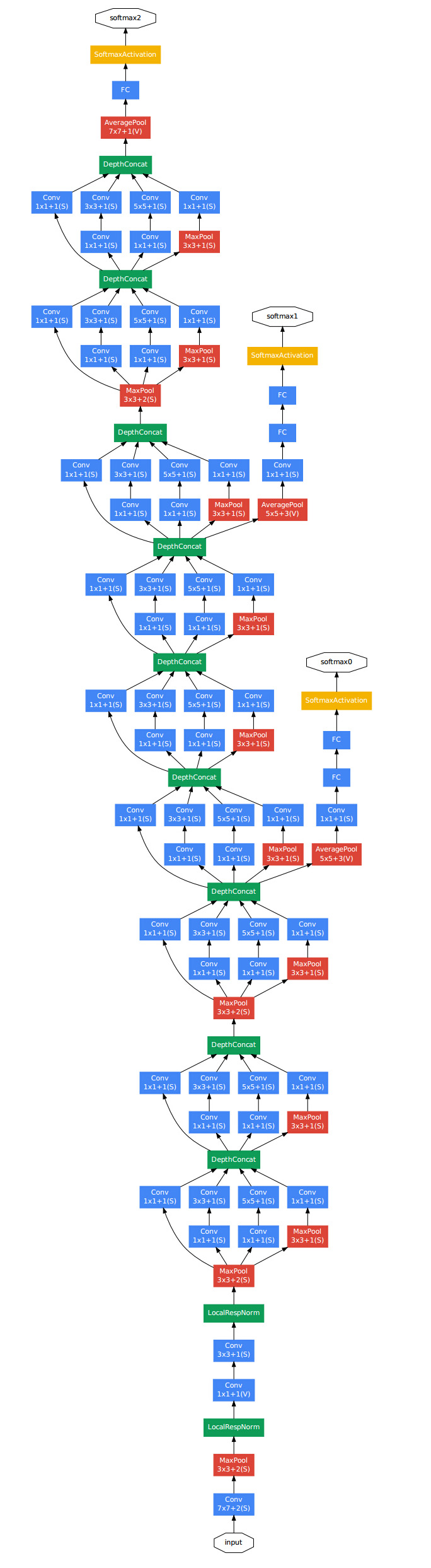
这里在网络中间添加softmax是为了在中间就输出中间的结果,提早进行梯度更新,减少计算量。
GoogLeNet Inception V2
前言
构建更深的网络逐渐成为主流,但是模型的变大也使计算效率越来越低。这里,文章试图找到一种方法在扩大网络的同时又尽可能地发挥计算性能。
首先,GoogLeNet V1出现的同期,性能与之接近的大概只有VGGNet了,并且二者在图像分类之外的很多领域都得到了成功的应用。但是相比之下,GoogLeNet的计算效率明显高于VGGNet,大约只有500万参数,只相当于Alexnet的1/12(GoogLeNet的caffemodel大约50M,VGGNet的caffemodel则要超过600M)。
GoogLeNet的表现很好,但是,如果想要通过简单地放大Inception结构来构建更大的网络,则会立即提高计算消耗。此外,在V1版本中,文章也没给出有关构建Inception结构注意事项的清晰描述。因此,在文章中作者首先给出了一些已经被证明有效的用于放大网络的通用准则和优化方法。这些准则和方法适用但不局限于Inception结构。
设计原则
1 . 避免表达瓶颈,特别是在网络靠前的地方。 信息流前向传播过程中显然不能经过高度压缩的层,即表达瓶颈。从input到output,feature map的宽和高基本都会逐渐变小,但是不能一下子就变得很小。比如你上来就来个kernel = 7, stride = 5 ,这样显然不合适。
另外输出的维度channel,一般来说会逐渐增多(每层的num_output),否则网络会很难训练。(特征维度并不代表信息的多少,只是作为一种估计的手段)
2 . 高维特征更易处理。 高维特征更易区分,会加快训练。
3. 可以在低维嵌入上进行空间汇聚而无需担心丢失很多信息。 比如在进行3x3卷积之前,可以对输入先进行降维(减少计算量)而不会产生严重的后果。假设信息可以被简单压缩,那么训练就会加快。
4 . 平衡网络的宽度与深度。
大卷积核分解为多个小的卷积核
大尺寸的卷积核可以带来更大的感受野,但也意味着更多的参数,比如5x5卷积核参数是3x3卷积核的25/9=2.78倍。为此,作者提出可以用2个连续的3x3卷积层(stride=1)组成的小网络来代替单个的5x5卷积层,(保持感受野范围的同时又减少了参数量)如下图:
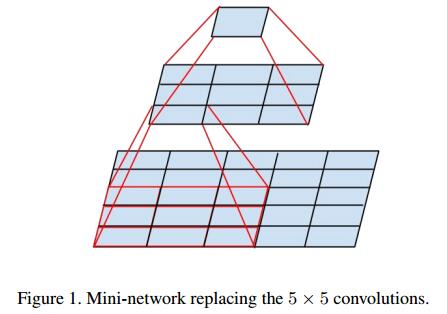
然后就会有2个疑问:
1 . 这种替代会造成表达能力的下降吗?
后面有大量实验可以表明不会造成表达缺失;
2 . 3x3卷积之后还要再加激活吗?
作者也做了对比试验,表明添加非线性激活会提高性能
从上面来看,大卷积核完全可以由一系列的3x3卷积核来替代,那能不能分解的更小一点呢。文章考虑了 nx1 卷积核。
如下图所示的取代3x3卷积:
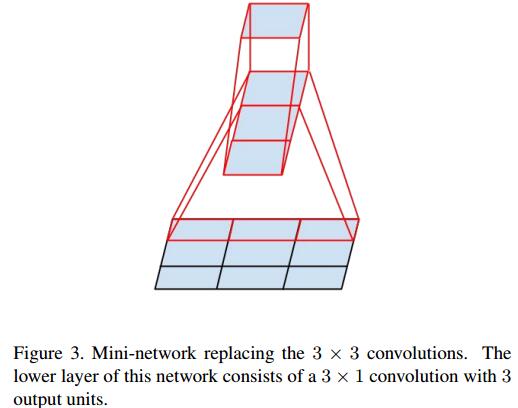
于是,任意nxn的卷积都可以通过1xn卷积后接nx1卷积来替代。实际上,作者发现在网络的前期使用这种分解效果并不好,还有在中度大小的feature map上使用效果才会更好。(对于mxm大小的feature map,建议m在12到20之间)。
总结如下图:
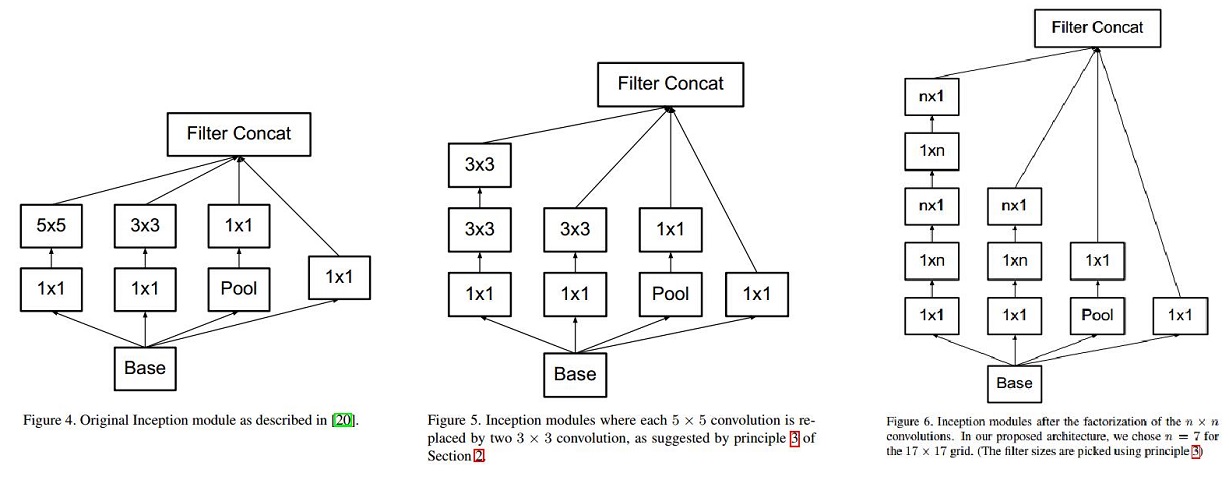
(1) 图4是GoogLeNet V1中使用的Inception结构;
(2) 图5是用3x3卷积序列来代替大卷积核;
(3) 图6是用nx1卷积来代替大卷积核,这里设定n=7来应对17x17大小的feature map。该结构被正式用在GoogLeNet V2中。
深度学习(十) GoogleNet的更多相关文章
- 对比深度学习十大框架:TensorFlow 并非最好?
http://www.oschina.net/news/80593/deep-learning-frameworks-a-review-before-finishing-2016 TensorFlow ...
- 推荐系统遇上深度学习(十)--GBDT+LR融合方案实战
推荐系统遇上深度学习(十)--GBDT+LR融合方案实战 0.8012018.05.19 16:17:18字数 2068阅读 22568 推荐系统遇上深度学习系列:推荐系统遇上深度学习(一)--FM模 ...
- Tensorflow2 深度学习十必知
博主根据自身多年的深度学习算法研发经验,整理分享以下十条必知. 含参考资料链接,部分附上相关代码实现. 独乐乐不如众乐乐,希望对各位看客有所帮助. 待回头有时间再展开细节说一说深度学习里的那些道道. ...
- ApacheCN 深度学习译文集 20210112 更新
新增了六个教程: TensorFlow 2 和 Keras 高级深度学习 零.前言 一.使用 Keras 入门高级深度学习 二.深度神经网络 三.自编码器 四.生成对抗网络(GAN) 五.改进的 GA ...
- 【深度学习系列】用PaddlePaddle和Tensorflow实现GoogLeNet InceptionV2/V3/V4
上一篇文章我们引出了GoogLeNet InceptionV1的网络结构,这篇文章中我们会详细讲到Inception V2/V3/V4的发展历程以及它们的网络结构和亮点. GoogLeNet Ince ...
- 深度学习——卷积神经网络 的经典网络(LeNet-5、AlexNet、ZFNet、VGG-16、GoogLeNet、ResNet)
一.CNN卷积神经网络的经典网络综述 下面图片参照博客:http://blog.csdn.net/cyh_24/article/details/51440344 二.LeNet-5网络 输入尺寸:32 ...
- 强化学习(十六) 深度确定性策略梯度(DDPG)
在强化学习(十五) A3C中,我们讨论了使用多线程的方法来解决Actor-Critic难收敛的问题,今天我们不使用多线程,而是使用和DDQN类似的方法:即经验回放和双网络的方法来改进Actor-Cri ...
- Deep learning深度学习的十大开源框架
Google开源了TensorFlow(GitHub),此举在深度学习领域影响巨大,因为Google在人工智能领域的研发成绩斐然,有着雄厚的人才储备,而且Google自己的Gmail和搜索引擎都在使用 ...
- 深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE
深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE 201 ...
随机推荐
- tomcat mac
在mac上安装tomcat,教程很不错:http://blog.csdn.net/j2ee_me/article/details/7928493 注意 1.要下载二进制文件,core, 2.解压后移动 ...
- 从极速飞艇源码 VantComponent 谈 小程序维护
在开发极速飞艇源码详情咨询Q166848365小程序的时候,我们总是期望用以往的技术规范和语法特点来书写当前的小程序,所以才会有各色的小程序框架,例如 mpvue.taro 等这些编译型框架.当然这些 ...
- 疑难杂症--在Windows Server 2008 R2上运行SQL Server 2008情况下,CPU过多导致的问题
64位的Windows7和Windows Server 2008 R2为了能够在一台机器上,支持超过64个逻辑CPU, 引入了Processor Group这个概念.Processor Group会把 ...
- JAVA 字符串编码转换
/** * 字符串编码转换的实现方法 * @param str 待转换编码的字符串 * @param newCharset 目标编码 * @return * @throws UnsupportedEn ...
- gitlab中修改项目名称客户端修改方法
如果gitlab项目名称已经修改,对于本地已经克隆下来的仓库,可以使用如下命令进行修改: git remote set-url origin 新的项目路径
- JavaScript一个页面中有多个audio标签,其中一个播放结束后自动播放下一个,audio连续播放
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- [bzoj4009] [HNOI2015]接水果 整体二分+扫描线+dfs序+树状数组
Description 风见幽香非常喜欢玩一个叫做 osu!的游戏,其中她最喜欢玩的模式就是接水果. 由于她已经DT FC 了The big black, 她觉得这个游戏太简单了,于是发明了一个更 加 ...
- 记一次优化ansible inventory的小例子
起因: 阿里云新扩容一批机器,要对上面的flume配置做修改 之前的inventory是这样子的 [user@vip10-ali-tj-console host_vars]$ sdiff vip10- ...
- collections 模块常用方法学习
前情提要: 1:模块介绍 个人认为就是 python自带的骚操作模块.如果基础能力够给力的话,完全用不到 个人认为解析式才是装逼神奇,用模块的都是伪娘 2:deque 双向列表 from coll ...
- 关于Mysql数据库查询数据大小写的问题汇总
前天在问答区看到一个童鞋对于mysql中大小写问题不熟悉,在回复他后再次汇总梳理如下: mysql中大小写问题主要有以下两种: A.表名区分大小写 ower_case_table_names 是表名区 ...