Linux下的GPT分区
GPT分区
这是另外一种分区,针对MBR分区,它有很多优点:
(1)几乎突破了分区个数的限制。
在GPT分区表中最多可以支持128个主分区。
(2)单个分区容量几乎没有限制。
单个分区最大支持1EB容量。
因此GPT分区中,主分区和扩展分区,逻辑分区的概念已经很模糊了。甚至没必要这么叫。其实我们知道
扩展分区之所以存在,意义就是为了解决MBR中分区个数的限制问题。既然在GPT中,分区个数几乎没有了
限制,那么这些概念当然就模糊起来了。
好了,废话不多说,讲解GPT分区的步骤吧。
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
依然是新加入了一块硬盘,我们要为它分区。使用的工具是”parted”,这个工具既可以做MBR分区,又可以做
GPT分区。当然了,还是主要用它来做GPT分区,下面开始分区吧。
在命令行键入命令“parted”,如下:

老规矩,还是先来看看parted这个工具的帮助信息吧,键入help,如下:

帮助信息好多,截图无法完全展现,总之仔细阅读帮助信息,可以帮助我们分区了。
下面选择新加入的那块硬盘,在这里,它的名字是/dev/sdb。选择这个设备进入分区即可:
接着要选择分区表的格式,应该选为gpt格式。表示我们是GPT分区,键入”mklabel gpt”,如下:
好了,关键的时刻到了,在parted中,既可以选择交互式的分区(即有问有答的方式),也可以选择
命令的方式,一句话搞定。我们就先用交互式的方式分区吧。
键入命令mkpart,如下:

这里是让我们给分区起一个名字。因为GPT分区中模糊了主分区,扩展分区的概念,就没有了那些规定,
因此分区的名称可以随意来起来。随便起一个名字”fuly“,如下:

又让你来选择文件系统的类型了,这里先不管,默认即可。直接按下enter键,如下:
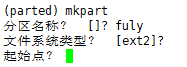
这里是让输入文件大小的起始点。注意,这里不同于MBR分区中的起始点。在这里输入的是实际文件的大小起始点。
,键入0,如下:

即可。如下:

开始了。
开始即可。如下:

这样子再一步如图中操作,就完成了这个分区了。那么我们来看看这个分区存在了否,键入print即可,如下:
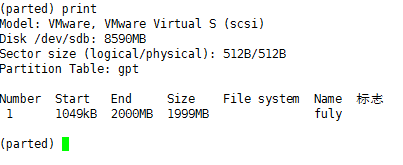
从上图中看到我们刚刚创建的分区fuly。也可以看到它的大小实际上是1999MB。
上面是用交互式的方法来分区的,简单吧。下面我们再来一个分区,使用命令行的方式分区。如下:

(
嘛),终点自然就是3000了。
那么分区成功了吗?再用print看一下,如下:

分区kun存在了。
好了,假设我们就需要两个分区,那么分区已经完成了。怎么保存退出呢?
只要键入quit即可。如下:

好了,不同于MBR还有用w来写入分区表,GPT使用quit退出时就直接生效了。
这样子我们的整个分区工作就完成了。
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
我们曾经用”fdisk -l”命令查看硬盘分区情况,现在再来试试,如下:

我们发现此时并不能查看到我们刚才的分区信息。因为使用fdisk工具无法查看gpt分区类型的详细信息。
只能查看msdos类型的分区信息(即MBR分区)。那么怎么查看呢?还是要使用parted工具。先选中gpt这样子分区
的硬盘,然后print即可。你可以直接键入命令“print all".如下:
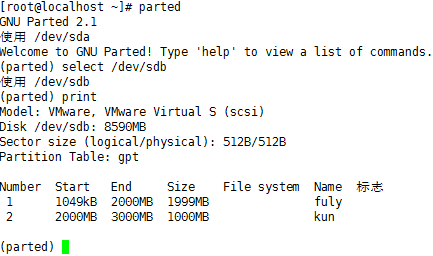
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
Linux下的GPT分区的更多相关文章
- Linux下的GPT分区,使用parted命令
Linux下的GPT分区,这是另外一种分区,针对MBR分区,它有很多优点: (1)几乎突破了分区个数的限制. 在GPT分区表中最多可以支持128个主分区. (2)单个分区容量几乎没有限制. 单个分区最 ...
- linux下硬盘的分区:
提到硬盘的分区,以前就是很乱,有什么主分区/扩展分区/逻辑分区等;它们有什么区别呢?现在简单的了解一下: 由于在MBR的主引导记录中的分区表里面最多只能记录4个分区记录,这个不够用啊,为了解决这个问题 ...
- Linux下的磁盘分区和逻辑卷
一.硬盘接口类型 硬盘的接口主要有IDE.SATA.SCSI .SAS和光纤通道等五种类型.其中IDE和SATA接口硬盘多用于家用产品中,也有部分应用于服务器,SATA是一种新生的硬盘接口类型,已经取 ...
- linux下的硬盘分区、格式化、挂载
linux下的MBR(msdos)分区.格式化.挂载 在linux下,需要使用一块硬盘. 需要进行以下四步: 识别硬盘-----分区规划-----格式化-----挂载 步骤一:分区规划 MBR模式分区 ...
- Linux下swap(交换分区)的增删改
swap介绍 Linux 的交换分区(swap),或者叫内存置换空间(swap space),是磁盘上的一块区域,可以是一个分区,也可以是一个文件,或者是他们的组合.交换分区的作用是,当系统物理内存吃 ...
- linux下挂载NTFS分区错误修复
今天在linux下打开win的NTFS硬盘总是提示出错了,而且是全部的NTFS盘都出错,其中sda1错误显示如下: Error mounting /dev/sda1 at /media/wangbo/ ...
- (转)Linux下增加交换分区的大小
场景:最近在Linux环境安装ELK相关软件时候发现机器特别的卡,所以就查看了Linux机器的内存使用情况,发现是内存和交换分区空间太小了. 对于虚拟机中的内存问题,可以直接通过更改虚拟机的硬件进行解 ...
- Linux下修改Swap分区大小
据了解Linux下可以有两种方法创建交换空间,一种是创建交换分区,另一种是创建交换文件.本文记录的是创建交换文件的方法,因为我用的是这种方法.. 添加交换文件步骤: 1.找个地方创建一个.swap的文 ...
- linux下添加逻辑分区并挂载(手动和自动方式)
一.查看新磁盘[root@desktop61 Desktop]# fdisk -cul /dev/sdc Disk /dev/sdc: 21.5 GB, 21474836480 bytes255 he ...
随机推荐
- nodejs搭建简易的rpc服务
这里主要使用的是jayson包,使用jayson实现rpc server端十分简单,如下: var jayson = require('jayson') // create a server var ...
- 引入第三方js文件,报错
错误:Mixed Content: The page at 'https://localhost:44336/MENU' was loaded over HTTPS, but requested an ...
- vim 编辑器常规操作
所看视频教程:兄弟连Linux云计算视频教程5.1文本编辑器Vim-5.2 插入命令 a:在光标所在字符后插入; A:在光标所在行尾插入; i:在光标所在字符前插入; I:在光标所在字符行行首插入; ...
- BZOJ2229: [Zjoi2011]最小割(最小割树)
传送门 最小割树 算法 初始时把所有点放在一个集合 从中任选两个点出来跑原图中的最小割 然后按照 \(s\) 集合与 \(t\) 集合的归属把当前集合划分成两个集合,递归处理 这样一共跑了 \(n − ...
- 洛谷 P2469 [SDOI2010]星际竞速 解题报告
题目描述 10年一度的银河系赛车大赛又要开始了.作为全银河最盛大的活动之一,夺得这个项目的冠军无疑是很多人的梦想,来自杰森座α星的悠悠也是其中之一. 赛车大赛的赛场由N颗行星和M条双向星际航路构成,其 ...
- Drupal7配置简洁URL(Clear URL)
参考:Apache Rewrite url重定向功能的简单配置 这两天折腾死了 首先说一下我的环境: Aache2.4.25-x64-vc14-r1;php-7.0.19-Win32-VC14-x64 ...
- JQuery漂浮广告代码
<!doctype html><html><head><meta charset="utf-8"><title>jque ...
- 数组实例 find和filter差异
const list01 = [{'name':'No1',age:20},{'name':'No2',age:21},{'name':'No3',age:20}]; let list02 = lis ...
- 怎样修复grub开机引导(grub rescue)
很多时候,特别是在linux调整分区后,开机重启时会出现 error : unknow filesystem grub rescue> 的字样,系 ...
- 131.005 Unsupervised Learning - Cluster | 非监督学习 - 聚类
@(131 - Machine Learning | 机器学习) 零. Goal How Unsupervised Learning fills in that model gap from the ...