selenium webdriver API详解(三)
本系列主要讲解webdriver常用的API使用方法(注意:使用前请确认环境是否安装成功,浏览器驱动是否与谷歌浏览器版本对应)
一:获取页面元素的文本内容:text
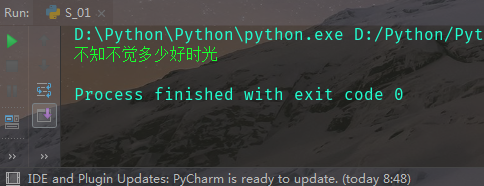
例:获取我的博客名字文本内容

代码:
from selenium import webdriver # 导入webdriverimport timedriver = webdriver.Chrome() # 实例化driver.get('https://www.cnblogs.com/kevin-liutianping/') # 打开我的博客time.sleep(1) # 等待2sa = driver.find_element_by_id('Header1_HeaderTitle') # 定位元素print(a.text) # 获取元素文本driver.quit() # 关闭浏览器进程
结果:
二:获取元素的属性值:get_attribute()
例:获取href的属性值
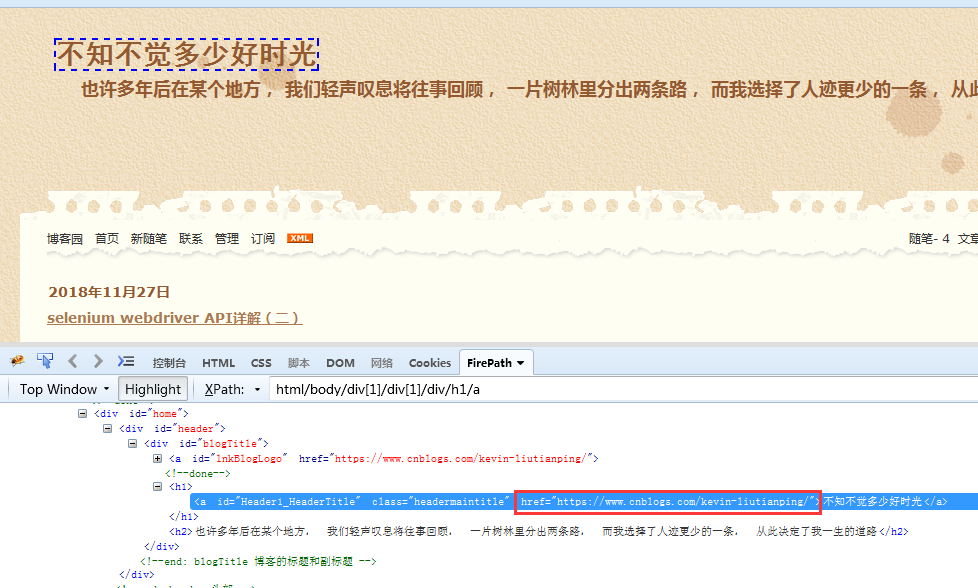
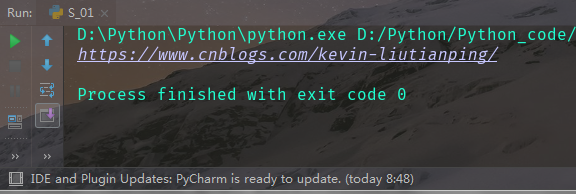
代码:
from selenium import webdriver # 导入webdriverimport timedriver = webdriver.Chrome() # 实例化driver.get('https://www.cnblogs.com/kevin-liutianping/') # 打开我的博客time.sleep(1) # 等待2sa = driver.find_element_by_id('Header1_HeaderTitle') # 定位元素print(a.get_attribute('href')) # 获取元素的href属性值driver.quit() # 关闭浏览器进程
结果:
三:判断页面元素是否可见:is_displayed()(注意:就算元素不可见,但是还是可以定位到的,只是这个元素不能操作)
例:判断标红元素是否可见
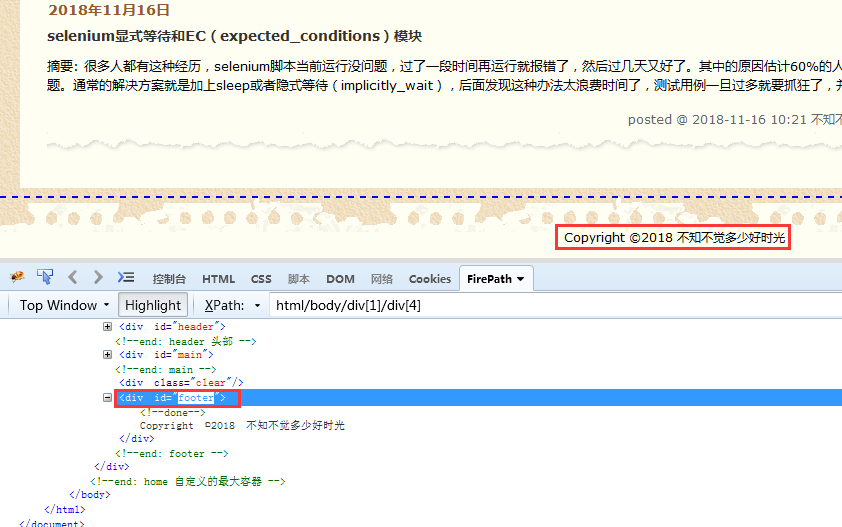
代码:
from selenium import webdriver # 导入webdriverimport timedriver = webdriver.Chrome() # 实例化driver.get('https://www.cnblogs.com/kevin-liutianping/') # 打开我的博客time.sleep(1) # 等待2sa = driver.find_element_by_id('footer') # 定位元素print(a.is_displayed()) # 判断页面元素是否可见driver.quit() # 关闭浏览器进程
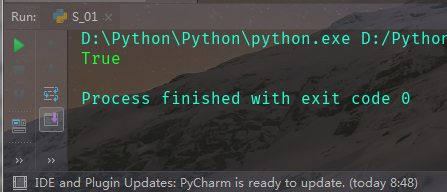
结果:可见返回true,不可见返回flase
四:判断页面元素是否可以操作:is_enabled()
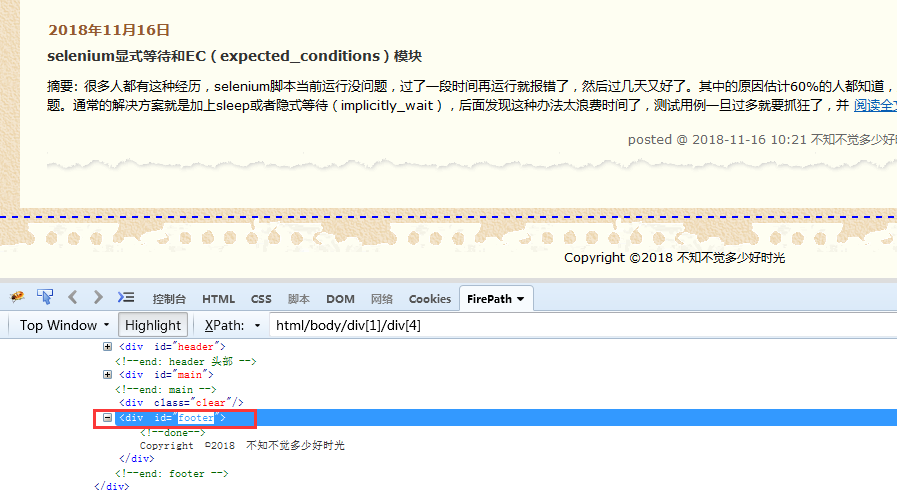
例:判断标红元素是否可以操作
代码:
from selenium import webdriver # 导入webdriverimport timedriver = webdriver.Chrome() # 实例化driver.get('https://www.cnblogs.com/kevin-liutianping/') # 打开我的博客time.sleep(1) # 等待2sa = driver.find_element_by_id('footer') # 定位元素print(a.is_enabled()) # 判断页面元素是否可操作driver.quit() # 关闭浏览器进程
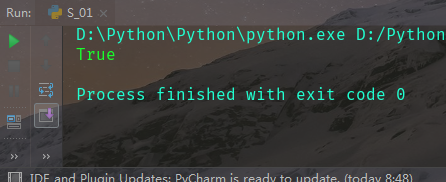
结果:
五:在输入框输入指定的内容:send_keys()
from selenium import webdriver # 导入webdriverimport timedriver = webdriver.Chrome()driver.get('https://www.baidu.com/')driver.find_element_by_id('kw').send_keys('博客园') # 在百度输入框中输入博客园driver.find_element_by_id('su').click() # 点击百度一下time.sleep(1)driver.quit()
六:单击按钮:click()
from selenium import webdriver # 导入webdriverimport timedriver = webdriver.Chrome()driver.get('https://www.baidu.com/')driver.find_element_by_id('kw').send_keys('博客园') # 在百度输入框中输入博客园driver.find_element_by_id('su').click() # 点击百度一下time.sleep(1)driver.quit()
七:清空输入框的内容:clear()
from selenium import webdriver # 导入webdriverimport timedriver = webdriver.Chrome()driver.get('https://www.baidu.com/')driver.find_element_by_id('kw').send_keys('博客园') # 在百度输入框中输入博客园time.sleep(1)driver.find_element_by_id('kw').clear() # 清空输入框driver.quit()
八:获取元素的css属性值:value_of_css_property()
from selenium import webdriver # 导入webdriverimport timedriver = webdriver.Chrome()driver.get('https://www.baidu.com/')a = driver.find_element_by_id('kw')print(a.value_of_css_property('font')) # 获取a元素的css font值driver.quit()结果:
selenium webdriver API详解(三)的更多相关文章
- selenium webdriver API详解(二)
本系列主要讲解webdriver常用的API使用方法(注意:使用前请确认环境是否安装成功,浏览器驱动是否与谷歌浏览器版本对应) 一:获取当前页面的title(一般获取title用于断言) from s ...
- selenium webdriver API详解(一)
本系列主要讲解webdriver常用的API使用方法(注意:使用前请确认环境是否安装成功,浏览器驱动是否与谷歌浏览器版本对应) 一:打开某个网址:get() from selenium import ...
- Selenium常用API详解介绍
转至元数据结尾 由 黄从建创建, 最后修改于一月 21, 2019 转至元数据起始 一.selenium元素定位 1.selenium定位方法 2.定位方法的用法 二.控制浏览器操作 1.控制 ...
- Webdriver之API详解(1)
说明 Webdriver API详解,基于python3,unittest框架,driver版本和浏览器自行选择. 本内容需要对python3的unittest框架有一个简单的了解,这里不再赘述,不了 ...
- Webdriver之API详解(2)
前言:今天继续上一篇文章https://www.cnblogs.com/linuxchao/p/linuxchao-selenium-apione.html分享selenium' webdriver ...
- Python爬虫之selenium库使用详解
Python爬虫之selenium库使用详解 本章内容如下: 什么是Selenium selenium基本使用 声明浏览器对象 访问页面 查找元素 多个元素查找 元素交互操作 交互动作 执行JavaS ...
- Java 8 Stream API详解--转
原文地址:http://blog.csdn.net/chszs/article/details/47038607 Java 8 Stream API详解 一.Stream API介绍 Java8引入了 ...
- jqGrid APi 详解
jqGrid APi 详解 jqGrid皮肤 从3.5版本开始,jqGrid完全支持jquery UI的theme.我们可以从http://jqueryui.com/themeroller/下载我们所 ...
- 网络编程socket基本API详解(转)
网络编程socket基本API详解 socket socket是在应用层和传输层之间的一个抽象层,它把TCP/IP层复杂的操作抽象为几个简单的接口供应用层调用已实现进程在网络中通信. socket ...
随机推荐
- mavenWeb工程建立步骤
1.File >> New >>other...,在New窗口中打开Maven,选中Maven Project,Next. 2.在New Maven Project弹出窗口中去 ...
- Centos7 KDE 桌面Konsole 光标错位解决方法
在使用linux 系统,桌面为KDE 时,在使用Konsole 时,光标的位置是错位的. 如下图效果 解决办法 用命令进入/home/cfox/.kde/share/apps/konsole 修改S ...
- ApiCloud模块链接
城市选择器 页面左右滑动 识别信用卡 图像coverFlow 输入框 图片浏览器 百度地图 ...
- JNI由浅入深_3_Hello World
1.需要准备的工具,eclipse,cdt(c++)插件,cygwin(unix)和 android ndk. 在cygwin的etc目录下将ndk的路径引入到profile文件中,可以在cygwin ...
- Notes 20180509 : Java基本数据类型
计算机就是个机器,这个机器由CPU.内存.硬盘和输入输出设备组成.计算机上运行着操作系统,操作系统提供对外的接口供各厂商和开发语言,开发运行在其上的驱动和应用程序. 操作系统将时间分成细小的时间碎片, ...
- oracle自动冷备份脚本
根据自己网上的资料和自己的需求,写的oracle冷备份脚本. 整体思路: 1.停止服务 2.文件拷贝 3.启动服务 保存以为文件为BAT格式,点击可以用下. rem ----------------- ...
- iOS 百度地图判断用户是否拖动地图的检测方法
前言:百度地图API并没有提供移动地图时的回调接口 实现:通过判断当前地图的中心位置是否为用户位置来判断,代码如下 -(void)mapView:(BMKMapView *)mapView regio ...
- Unbnutu下安装Apache,Mysql,php,phpmyadmin
先写一键部署脚本,肯定是先要知道如何手动安装Apache,Mysql,php,phpmyadmin 一 Apache2的安装 apt install apache2 安装好之后,手动看一下apach ...
- Mysql-常用数据的基本操作和基本形式
一 .介绍 二 .插入数据INSERT 三 .更新数据UPDATE 四 .删除数据DELETE 五 .查询数据SELECT 六 .权限管理 一. 介绍 MySQL数据操作: DML ========= ...
- Discuptor入门(二)-实例
前言:最近在项目中看到有人使用的discuptor框架,因为没有接触过所以网上找了些资料.但最终发现开荒者太少,好像没什么人用那.最后感觉还是官方入门文档靠谱点.所以自己翻译了下(翻译器~),希望能帮 ...