Linux buffer/cache异同
buffers与cached
1)、异同点
在Linux 操作系统中,当应用程序需要读取文件中的数据时,操作系统先分配一些内存,将数据从磁盘读入到这些内存中,然后再将数据分发给应用程序;当需要往文件中写 数据时,操作系统先分配内存接收用户数据,然后再将数据从内存写到磁盘上。然而,如果有大量数据需要从磁盘读取到内存或者由内存写入磁盘时,系统的读写性 能就变得非常低下,因为无论是从磁盘读数据,还是写数据到磁盘,都是一个很消耗时间和资源的过程,在这种情况下,Linux引入了buffers和 cached机制。
buffers与cached都是内存操作,用来保存系统曾经打开过的文件以及文件属性信息,这样当操作系统需要读取某些文件时,会首先在buffers 与cached内存区查找,如果找到,直接读出传送给应用程序,如果没有找到需要数据,才从磁盘读取,这就是操作系统的缓存机制,通过缓存,大大提高了操 作系统的性能。但buffers与cached缓冲的内容却是不同的。
buffers是用来缓冲块设备做的,它只记录文件系统的元数据(metadata)以及 tracking in-flight pages,而cached是用来给文件做缓冲。更通俗一点说:buffers主要用来存放目录里面有什么内容,文件的属性以及权限等等。而cached直接用来记忆我们打开过的文件和程序。buffer理解为find,ll,ls 时的缓存,cache理解为vi,vim的缓存
为了验证我们的结论是否正确,可以通过vi打开一个非常大的文件,看看cached的变化,然后再次vi这个文件,感觉一下两次打开的速度有何异同,是不 是第二次打开的速度明显快于第一次呢?这里提供一个小脚本打印首次及第二次打开一个大文件(catalina.logaa 约2G)耗时及cached/buffers的变化:

#!/bin/bash
sync
sync
echo 3 > /proc/sys/vm/drop_caches
echo -e "----------------------缓存释放后,内存使用情况(KB):----------------------"
free
cached1=`free |grep Mem:|awk '{print $7}'`
buffers1=`free |grep Mem:|awk '{print $6}'`
date1=`date +"%Y%m%d%H%M%S"`
cat catalina.logaa >1
date2=`date +"%Y%m%d%H%M%S"`
echo -e "----------------------首次读取大文件后,内存使用情况(KB):----------------------"
free
cached2=`free |grep Mem:|awk '{print $7}'`
buffers2=`free |grep Mem:|awk '{print $6}'`
#echo $date1
#echo $date2
interval_1=`expr ${date2} - ${date1}`
cached_increment1=`expr ${cached2} - ${cached1}`
buffers_increment1=`expr ${buffers2} - ${buffers1}` date3=`date +"%Y%m%d%H%M%S"`
cat catalina.logaa >1
date4=`date +"%Y%m%d%H%M%S"`
echo -e "----------------------再次读取大文件后,内存使用情况(KB):----------------------"
free
cached3=`free |grep Mem:|awk '{print $7}'`
buffers3=`free |grep Mem:|awk '{print $6}'`
#echo $date3
#echo $date4
interval_2=`expr ${date4} - ${date3}`
cached_increment2=`expr ${cached3} - ${cached2}`
buffers_increment2=`expr ${buffers3} - ${buffers2}`
echo -e "----------------------统计汇总数据如下:----------------------"
echo -e "首次读取大文件,cached增量:${cached_increment1},单位:KB"
echo -e "首次读取大文件,buffers增量:${buffers_increment1},单位:KB"
echo -e "首次读取大文件,耗时:${interval_1},单位:s \n"
echo -e "再次读取大文件,cached增量:${cached_increment2},单位:KB"
echo -e "再次读取大文件,buffers增量:${buffers_increment2},单位:KB"
echo -e "再次读取大文件,耗时:${interval_2},单位:s"
执行结果如下(由于打印出来的free结果跟参数赋值时用的free命令之间有时间间隔,计算起来可能会略有不同):
接着执行下面的命令:find /* -name *.conf ,看 看buffers的值是否变化,然后重复执行find命令,看看两次显示速度有何不同。如下脚本(需要注意使用bc计算浮点型数据时需要安装相应软件,我 的系统是centos7.0,内核4.3.3的版本,安装的是bc-1.06.95-13.el7.x86_64服务):
#!/bin/bash
sync
sync
echo 3 > /proc/sys/vm/drop_caches
echo -e "----------------------缓存释放后,内存使用情况(KB):----------------------"
free
cached1=`free |grep Mem:|awk '{print $7}'`
buffers1=`free |grep Mem:|awk '{print $6}'`
date1=`date +%s.%N`
find /* -name *.conf >2
date2=`date +%s.%N`
echo -e "----------------------首次查询后,内存使用情况(KB):----------------------"
free
cached2=`free |grep Mem:|awk '{print $7}'`
buffers2=`free |grep Mem:|awk '{print $6}'`
#echo $date1
#echo $date2
interval_1=`echo "scale=3; ${date2} - ${date1}" | bc`
cached_increment1=`expr ${cached2} - ${cached1}`
buffers_increment1=`expr ${buffers2} - ${buffers1}` date3=`date +%s.%N`
find /* -name *.conf >2
date4=`date +%s.%N`
echo -e "----------------------再次查询后,内存使用情况(KB):----------------------"
free
cached3=`free |grep Mem:|awk '{print $7}'`
buffers3=`free |grep Mem:|awk '{print $6}'`
#echo $date3
#echo $date4
interval_2=`echo "scale=3; ${date4} - ${date3}" | bc`
cached_increment2=`expr ${cached3} - ${cached2}`
buffers_increment2=`expr ${buffers3} - ${buffers2}`
echo -e "----------------------统计汇总数据如下:----------------------"
echo -e "首次查询,cached增量:${cached_increment1},单位:KB"
echo -e "首次查询,buffers增量:${buffers_increment1},单位:KB"
echo -e "首次查询,耗时:${interval_1},单位:s \n"
echo -e "再次查询,cached增量:${cached_increment2},单位:KB"
echo -e "再次查询,buffers增量:${buffers_increment2},单位:KB"
echo -e "再次查询,耗时:${interval_2},单位:s"
结果如下(最后那个应该是0.470702440,使用bc计算的时候那个0被去掉了):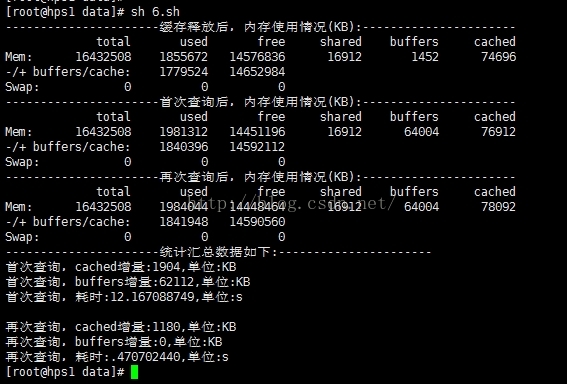
2、内存释放
linux系统中/proc是一个虚拟文件系统,我们可以通过对它的读写操作做为与kernel实体间进行通信的一种手段。也就是说可以通过修改 /proc中的文件,来对当前kernel的行为做出调整。那么我们可以通过调整/proc/sys/vm/drop_caches来释放内存。关于drop_caches,官方给出的说法是:
Writing to this will cause thekernel to drop clean caches, dentries and
inodes from memory, causing thatmemory to become free.
To free pagecache:
echo 1 > /proc/sys/vm/drop_caches
To free dentries and inodes:
echo 2 > /proc/sys/vm/drop_caches
To free pagecache, dentries andinodes:
echo 3 > /proc/sys/vm/drop_caches
As this is a non-destructiveoperation and dirty objects are not freeable, the
user should run `sync' first.
http://www.kernel.org/doc/Documentation/sysctl/vm.txt
# cat /proc/sys/vm/drop_caches
0
默认是0,1表示清空页缓存,2表示清空inode和目录树缓存,3清空所有的缓存
[root@hps103 ~]# sync
[root@hps103 ~]# free -m
total used free shared buffers cached
Mem: 499 323 175 0 52 188
-/+ buffers/cache: 82 416
Swap: 2047 0 2047 [root@hps103 ~]# echo 3 > /proc/sys/vm/drop_caches
[root@hps103 ~]# free -m //发现缓存明显减少了
total used free shared buffers cached
Mem: 499 83 415 0 1 17
-/+ buffers/cache: 64 434
Swap: 2047 0 2047
Linux buffer/cache异同的更多相关文章
- Linux-内存管理机制、内存监控、buffer/cache异同
在Linux中经常发现空闲内存很少,似乎所有的内存都被系统占用了,表面感觉是内存不够用了,其实不然.这是Linux内存管理的一个优秀特性,主要特点是,无论物理内存有多大,Linux 都将其充份利用,将 ...
- Linux Buffer/Cache 的区别
以前经常使用free -h命令来查看当前操作系统的内存使用情况,同时也注意过返回信息中有一列是buff/cache,来公司之前,面试官还问过我这两个的区别,当时没有回答出来,现在特意回顾记录下: ...
- 解决linux buffer/cache 消耗内存过高引发的问题
工作中接到DBA报障某台服务器 跑一些大的数据,服务器就无法远程连接,报错,抓过日志叫DELL工程师检测也没问题,系统也重装过, 现在些一些较大的数据就会报如 图错误,由于服务器远在异地城市IDC机房 ...
- Page Cache buffer Cache
https://www.thomas-krenn.com/en/wiki/Linux_Page_Cache_Basics References Jump up ↑ The Buffer Cache ( ...
- 【转】Linux 查看内存(free buffer cache)
转自:http://elf8848.iteye.com/blog/1995638 Linux下如何查内存信息,如内存总量.已使用量.可使用量.经常使用Windows操作系统的朋友,已经习惯了如果空闲的 ...
- linux page cache和buffer cache
主要区别是,buffer cache缓存元信息,page cache缓存文件数据 buffer 与 cache 是作为磁盘文件缓存(磁盘高速缓存disk cache)来使用,主要目的提高文件系统系性能 ...
- linux下的缓存机制及清理buffer/cache/swap的方法梳理 (转)
一.缓存机制介绍 在Linux系统中,为了提高文件系统性能,内核利用一部分物理内存分配出缓冲区,用于缓存系统操作和数据文件,当内核收到读写的请求时,内核先去缓存区找是否有请求的数据,有就直接返回,如果 ...
- Linux 物理内存 buffer cache
Linux下如何查内存信息,如内存总量.已使用量.可使用量.经常使用Windows操作系统的朋友,已经习惯了如果空闲的内存较多,心里比较踏实.当使用Linux时,可能觉的Linux物理内存很快被用光( ...
- [转帖] Linux buffer 和 cache相关内容
Linux中Buffer/Cache清理 Lentil2018年9月6日 Linux中的buff/cache可以被手动释放,释放缓存的代码如下: https://lentil1016.cn/linux ...
随机推荐
- Spark Streaming使用Kafka保证数据零丢失
来自: https://community.qingcloud.com/topic/344/spark-streaming使用kafka保证数据零丢失 spark streaming从1.2开始提供了 ...
- LeetCode: isSameTree1 解题报告
isSameTree1 Given two binary trees, write a function to check if they are equal or not. Two binary t ...
- iOS NSURLConnection使用详解
一.整体介绍 NSURLConnection是苹果提供的原生网络访问类,但是苹果很快会将其废弃,且由NSURLSession(iOS7以后)来替代.目前使用最广泛的第三方网络框架AFNetworkin ...
- Java中数据库连接池原理机制的详细讲解
连接池的基本工作原理 1.基本概念及原理 由上面的分析可以看出,问题的根源就在于对数据库连接资源的低效管理.我们知道,对于共享资源,有一个很著名的设计模式:资源池(Resource Pool).该模式 ...
- 一款基于jquery和css3的响应式二级导航菜单
今天给大家分享一款基于jquery和css3的响应式二级导航菜单,这款导航是传统的基于顶部,鼠标经过的时候显示二级导航,还采用了当前流行的响应式设计.效果图如下: 在线预览 源码下载 实现的代码. ...
- 使用HttpWebRequest调用wcf一段代码
public class HttpClass { internal static HttpWebRequest _httpWebRequest; public static void Request( ...
- USB 驱动之 usb_register 函数解析
前段时间在kernel 添加了 USB to LAN 模块 AX88772B 的驱动. 根据相关添加解析一下 usb_register_driver 函数 drivers/net/usb/asix.c ...
- BloomFilter——大规模数据处理利器[转]
原文链接:原文 Bloom Filter是由Bloom在1970年提出的一种多哈希函数映射的快速查找算法.通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合. 一. 实 ...
- debian配置ftp
大家好,最近几天我在配置vsftpd,总结出如何更快的配置vsftpd1.我的系统是debian 5.02.安装 vsftpd, apt-get install vsftpd3.配置 vsftpdcd ...
- Android修改默认SharedPreferences文件的路径,SharedPreferences常用工具类
import android.app.Activity; import android.content.Context; import android.content.ContextWrapper; ...