LevelDB Compaction操作
【LevelDB Compaction操作】
对于LevelDb来说,写入记录操作很简单,删除记录仅仅写入一个删除标记就算完事,但是读取记录比较复杂,需要在内存以及各个层级文件中依照新鲜程度依次查找,代价很高。为了加快读取速度,levelDb采取了compaction的方式来对已有的记录进行整理压缩,通过这种方式,来删除掉一些不再有效的KV数据,减小数据规模,减少文件数量等。
levelDb的compaction机制和过程与Bigtable所讲述的是基本一致的,Bigtable中讲到三种类型的compaction: minor ,major和full。所谓minor Compaction,就是把memtable中的数据导出到SSTable文件中;major compaction就是合并不同层级的SSTable文件,而full compaction就是将所有SSTable进行合并。
LevelDb包含其中两种,minor和major。
先来看看minor Compaction的过程。Minor compaction 的目的是当内存中的memtable大小到了一定值时,将内容保存到磁盘文件中,图8.1是其机理示意图。
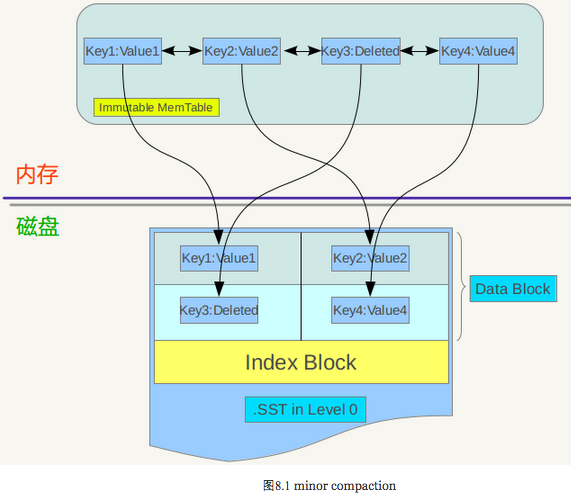
从8.1可以看出,当memtable数量到了一定程度会转换为immutable memtable,此时不能往其中写入记录,只能从中读取KV内容。之前介绍过,immutable memtable其实是一个多层级队列SkipList,其中的记录是根据key有序排列的。所以这个minor compaction实现起来也很简单,就是按照immutable memtable中记录由小到大遍历,并依次写入一个level 0 的新建SSTable文件中,写完后建立文件的index数据,这样就完成了一次minor compaction。从图中也可以看出,对于被删除的记录,在minor compaction过程中并不真正删除这个记录,原因也很简单,这里只知道要删掉key记录,但是这个KV数据在哪里?那需要复杂的查找,所以在minor compaction的时候并不做删除,只是将这个key作为一个记录写入文件中,至于真正的删除操作,在以后更高层级的compaction中会去做。
当某个level下的SSTable文件数目超过一定设置值后,levelDb会从这个level的SSTable中选择一个文件(level>0),将其和高一层级的level+1的SSTable文件合并,这就是major compaction。
我们知道在大于0的层级中,每个SSTable文件内的Key都是由小到大有序存储的,而且不同文件之间的key范围(文件内最小key和最大key之间)不会有任何重叠。Level 0的SSTable文件有些特殊,尽管每个文件也是根据Key由小到大排列,但是因为level 0的文件是通过minor compaction直接生成的,所以任意两个level 0下的两个sstable文件可能再key范围上有重叠。所以在做major compaction的时候,对于大于level 0的层级,选择其中一个文件就行,但是对于level 0来说,指定某个文件后,本level中很可能有其他SSTable文件的key范围和这个文件有重叠,这种情况下,要找出所有有重叠的文件和level 1的文件进行合并,即level 0在进行文件选择的时候,可能会有多个文件参与major compaction。
levelDb在选定某个level进行compaction后,还要选择是具体哪个文件要进行compaction,levelDb在这里有个小技巧, 就是说轮流来,比如这次是文件A进行compaction,那么下次就是在key range上紧挨着文件A的文件B进行compaction,这样每个文件都会有机会轮流和高层的level 文件进行合并。
如果选好了level L的文件A和level L+1层的文件进行合并,那么问题又来了,应该选择level L+1哪些文件进行合并?levelDb选择L+1层中和文件A在key range上有重叠的所有文件来和文件A进行合并。
也就是说,选定了level L的文件A,之后在level L+1中找到了所有需要合并的文件B,C,D…..等等。剩下的问题就是具体是如何进行major 合并的?就是说给定了一系列文件,每个文件内部是key有序的,如何对这些文件进行合并,使得新生成的文件仍然Key有序,同时抛掉哪些不再有价值的KV 数据。
图8.2说明了这一过程。
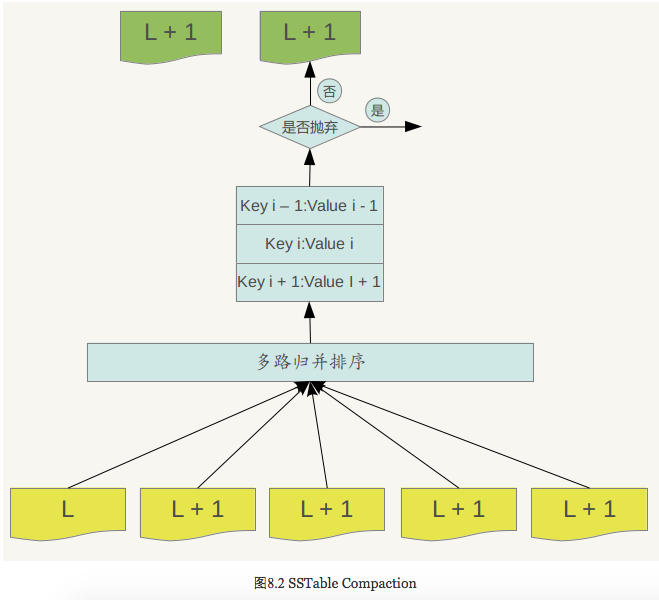
Major compaction的过程如下:对多个文件采用多路归并排序的方式,依次找出其中最小的Key记录,也就是对多个文件中的所有记录重新进行排序。之后采取一定的标准判断这个Key是否还需要保存,如果判断没有保存价值,那么直接抛掉,如果觉得还需要继续保存,那么就将其写入level L+1层中新生成的一个SSTable文件中。就这样对KV数据一一处理,形成了一系列新的L+1层数据文件,之前的L层文件和L+1层参与compaction 的文件数据此时已经没有意义了,所以全部删除。这样就完成了L层和L+1层文件记录的合并过程。
那么在major compaction过程中,判断一个KV记录是否抛弃的标准是什么呢?其中一个标准是:对于某个key来说,如果在小于L层中存在这个Key,那么这个KV在major compaction过程中可以抛掉。因为我们前面分析过,对于层级低于L的文件中如果存在同一Key的记录,那么说明对于Key来说,有更新鲜的Value存在,那么过去的Value就等于没有意义了,所以可以删除。
参考:http://www.cnblogs.com/haippy/archive/2011/12/04/2276064.html
LevelDB Compaction操作的更多相关文章
- LevelDB的源码阅读(四) Compaction操作
leveldb的数据存储采用LSM的思想,将随机写入变为顺序写入,记录写入操作日志,一旦日志被以追加写的形式写入硬盘,就返回写入成功,由后台线程将写入日志作用于原有的磁盘文件生成新的磁盘数据.Leve ...
- Rocksdb Compaction原理
概述 compaction主要包括两类:将内存中imutable 转储到磁盘上sst的过程称之为flush或者minor compaction:磁盘上的sst文件从低层向高层转储的过程称之为compa ...
- LevelDB库简介
LevelDB库简介 一.LevelDB入门 LevelDB是Google开源的持久化KV单机数据库,具有很高的随机写,顺序读/写性能,但是随机读的性能很一般,也就是说,LevelDB很适合应用在查询 ...
- [转载] leveldb日知录
原文: http://www.cnblogs.com/haippy/archive/2011/12/04/2276064.html 对leveldb非常好的一篇学习总结文章 郑重声明:本篇博客是自己学 ...
- LevelDb简单介绍和原理——本质:类似nedb,插入数据文件不断增长(快照),再通过删除老数据做更新
转自:http://www.cnblogs.com/haippy/archive/2011/12/04/2276064.html 有时间再好好看下整个文章! 说起LevelDb也许您不清楚,但是如果作 ...
- Leveldb 实现原理
原文地址:http://www.cnblogs.com/haippy/archive/2011/12/04/2276064.html LevelDb日知录之一:LevelDb 101 说起LevelD ...
- LevelDB源码之五Current文件\Manifest文件\版本信息
版本信息有什么用?先来简要说明三个类的具体用途: Version:代表了某一时刻的数据库版本信息,版本信息的主要内容是当前各个Level的SSTable数据文件列表. VersionSet:维护了一份 ...
- LevelDB系列之整体架构
LevelDb本质上是一套存储系统以及在这套存储系统上提供的一些操作接口.为了便于理解整个系统及其处理流程,我们可以从两个不同的角度来看待LevleDb:静态角度和动态角度.从静态角度,可以假想整个系 ...
- LevelDb原理剖析
在说LevelDb之前,先认识两位大牛,Jeff Dean和Sanjay Ghemawat,这两位是Google公司重量级的工程师,为数甚少的Google Fellow之二. Jeff Dean其人: ...
随机推荐
- HALCON之喷码OCR识别案例
一个喷码识别的案例 1 read_image (Image, 'D:/用户目录/Desktop/2.png') 2 3 rgb1_to_gray(Image, Image) 4 5 get_image ...
- 【DEV GridControl】怎样使GridView中满足某个条件的行可编辑,其余行不可编辑?
DXperience控件包,使用起来非常方便,但有时候某些功能的实现在文档中不太容易找到解决方案,比如下面要提到的这个功能我就在文档中找了很久也没找到,最后还是在官方论坛上找到的. 具体问题是这样的: ...
- copy assign retain 修饰属性的set 方法
@property (nonatomic,retain) NSString * name; - (void)setName:(NSString*)name { [name retain]; 把传进 ...
- L193
Real generosity toward the future lies in giving all to the present.将一切奉献给当下,就是对未来的真正慷慨.The wheels o ...
- PostgreSQL逻辑复制槽
Schema | Name | Result data type | Argument data types | Type ------------+------------------------- ...
- Go安装一些第三方库
原文链接:https://javasgl.github.io/go-get-golang-x-packages/ 侵权联系删除! go在go get 一些 package时候的会由于众所周知的原因而无 ...
- 使用jquery获取url以及jquery获取url参数的方法(转)
使用jquery获取url以及使用jquery获取url参数是我们经常要用到的操作 1.jquery获取url很简单,代码如下 1.window.location.href; 其实只是用到了javas ...
- TCP滑动窗口与回退N针协议
[转]TCP 滑动窗口协议/1比特滑动窗口协议/后退n协议/选择重传协议 2014-1-5阅读884 评论0 本文转自 http://www.cnblogs.com/ulihj/archive/201 ...
- coredns 代理consul 运行noamd 部署的应用
nomad 是一个方便的应用调度平台,consul 一个很不错的服务发现工具,coredns 很不错, 扩展性比较强的dns 服务器,集成起来可能做很强大的事情 我的运行环境是mac,实际情况按需部署 ...
- deno学习一 安装试用&&几个问题解决
基本的依赖可以参考github 我的环境是centos 7 基本安装 需要golang 以及yarn安装 Protobuf 3 这是官方的方式,实际可以变通下 cd ~ wget https:// ...